RECENZJE | Audiotechnika: dźwięk cyfrowy - czy analog naprawdę był lepszy?
Audiotechnika: dźwięk cyfrowy - czy analog naprawdę był lepszy?
Autor: Przemysław Rel | Data: 11/04/13
Dziś czarne, trzeszczące płyty winylowe spotyka się dość rzadko. Znajdują swoich miłośników raczej tylko wśród audiofili, kolekcjonerów i didżejów. Z tego artykułu dowiecie się trochę o tym, w jaki sposób rejestrowany jest dźwięk cyfrowy i czym tak naprawdę różni się od analogowego. Zastanowimy się także, czy audiofile mają rację, kiedy mówią, że płyta CD to jedna z najgorszych rzeczy, która mogła przydarzyć się muzyce. Zapraszam do środka!
Wstęp
Od najmłodszych lat fascynowało mnie jak to się dzieje, że igła gramofonu podróżując po ścieżce płyty winylowej powoduje, że powstaje dźwięk. Najmniejszym problemem było to, że dźwięk ten wydobywa się z głośnika – największą tajemnicą było to, że przystawiając ucho do samej igły można było usłyszeć muzykę. Później zaciekawiły mnie kasety magnetofonowe, a kiedy płyta CD przestała był towarem wyjątkowo ekskluzywnym, odkryłem oprogramowanie do obróbki audio. Możliwości, jakie się pojawiły, były niemal nieograniczone.
Zapewne podobne wrażenie cyfrowa obróbka wywarła na inżynierach zajmujących się miksowaniem i masteringiem dźwięku. Odejście od analogu nie spotkało się jednak ze szczególnie ciepłym przyjęciem ludzi ceniących jakość dźwięku, którzy inwestują niepojętą ilość pieniędzy w sprzęt audio. Dlaczego tak się stało? Czy plik w formacie Wave, o częstotliwości próbkowania 44,1kHz i rozdzielczości 16-bitów to za mało, by zarejestrować i odtworzyć dobrej jakości dźwięk? Może potrzeba nam 24 bitów i próbkowania typu 96kHz? Czy „empetrójki” są naprawdę takie tragiczne? Przecież większość z nas nie jest w stanie rozpoznać, czy muzyka odtwarzana jest z takiego pliku czy z płyty CD. Czy kompresja bezstratna jest naprawdę bezstratna? Dlaczego nowej muzyki nie da się słuchać? Czy wojna głośności to coś złego?
Na te wszystkie pytania postaram się odpowiedzieć w tym artykule. Będę posługiwał się prostym językiem i nie będę zanudzał Was wzorami z fizyki. Nie obędzie się jednak bez wykresów. Dużej ilości wykresów.
Zapraszam!
Kilka słów ogólnie o dźwięku i zapisie analogowym
W największym uproszczeniu, dźwięk to są drgania powietrza. Między innymi dlatego w przestrzeni kosmicznej panuje totalna cisza – coś, o czym często zapominają twórcy filmów (choć bardziej prawdopodobne jest to, że efektowna wojna w kosmosie byłaby mało... efektowna, gdyby nie było nic słychać).
Drgania powietrza można przedstawić w postaci wykresu - fala dźwiękowa jest sinusoidą i nie trzeba być wybitnym matematykiem, żeby zrozumieć sposób jej prezentacji. Wykresy przedstawiają falę w danym odstępie czasu i każdy program komputerowy, służący do obróbki dźwięku, przedstawia ją jako główny element interfejsu użytkownika. Ale o tym później.
Generowana przez dźwięk fala to w gruncie rzeczy zmiany ciśnienia powietrza. Na tej właśnie zasadzie działa mikrofon, który wykrywa te zmiany i zamienia je na sygnał elektryczny, który wygląda praktycznie identycznie jak na przedstawionym wyżej wykresie. Głośnik działa na odwrotnej zasadzie – sygnał elektryczny zamienia na drgania, a drgania zmieniają ciśnienie powietrza w jego sąsiedztwie.
Falę dźwiękową można zarejestrować na taśmie magnetycznej lub na płycie gramofonowej. Na tej ostatniej tworzone są rowki o kształcie fali – igła gramofonu podróżuje po nich i rusza się na boki. Ruchy te przetwarzane są na sygnał elektryczny (a dokładniej, piezoelektryczny), a ten wędruje do wzmacniacza, z którego następnie trafia do głośników.
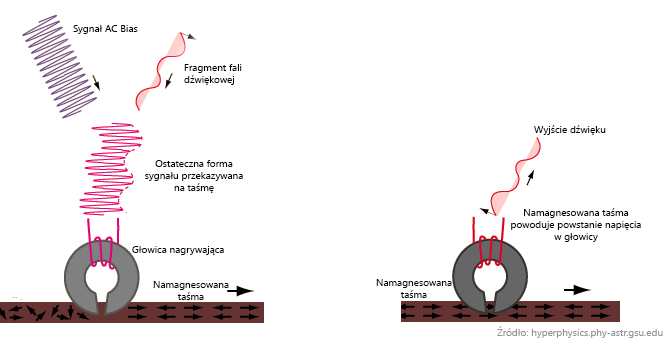
W przypadku kasety magnetofonowej mamy do czynienia z taśmą magnetyczną. Głowica nagrywająca stykająca się z przesuwaną taśmą przekazuje jej ładunek elektryczny (falę dźwiękową wraz z dodatkowymi sygnałami „rozbudzającymi” namagnesowanie), który powoduje, że na taśmie tworzony jest wzór. Podczas odtwarzania odbywa się proces odwrotny i ów wzór z powrotem zamieniany jest w sygnał elektryczny.
Oczywiście, powyższe opisy są znacznie uproszczone, ale w zupełności wystarczające do rozważań zawartych w tym tekście.
Zapis analogowy ma kilka dość istotnych wad. Między innymi, jest to współczynnik sygnału do szumu – płyta winylowa i kaseta po prostu szumią. Wpływ na powstawanie tego niezamierzonego efektu mają głównie czynniki mechaniczne (np. niedoskonałości łożysk gramofonu). W praktyce oznacza to, że najcichszy zarejestrowany dźwięk musi mieć odpowiednio wysoki poziom, aby być w ogóle słyszalnym. Mowa więc tutaj o tzw. kompresji dynamiki – tym tematem zajmuję się szerzej w osobnym rozdziale. Może wystąpić również zmiana wysokości tonów – silnik gramofonu lub magnetofonu może pracować z minimalnie mniejszą lub większą prędkością niż ta właściwa. Myślę, że każdy słyszał taki efekt na starych nagraniach na kasetach.
Długość fali i częstotliwość
Długość fali dźwiękowej to odległość na wykresie między jedną częścią fali a drugą... najlepiej przedstawi to wykres:
Częstotliwość to ilość takich fal zarejestrowanych w ciągu sekundy:
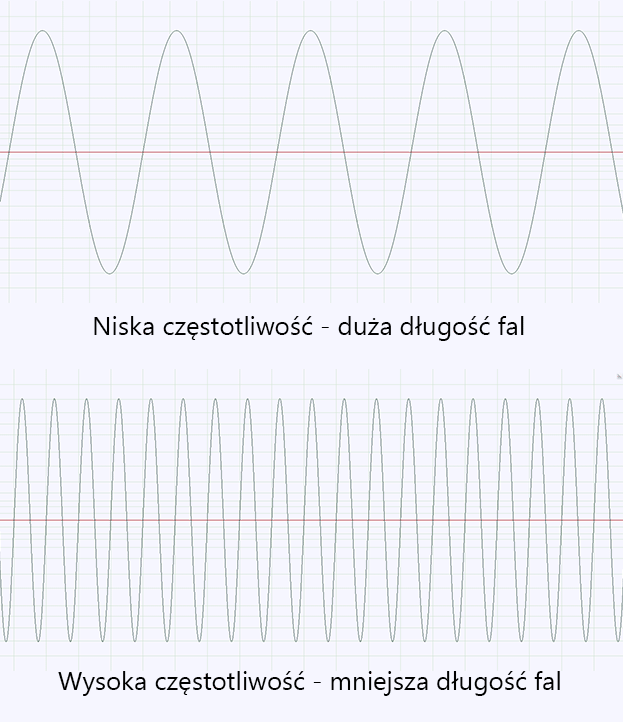
Im mniejsza odległość między kolejnymi „peakami”, tym dźwięk jest o wyższej częstotliwości, czyli w uproszczeniu... bardziej piszczący. Dźwiękiem niskim będzie np. brzmienie gitary basowej, zaś wysokim – talerze perkusji.
W tym momencie możemy przejść dalej, czyli jak to wszystko jest zapisane w formie cyfrowej.
Zapis cyfrowy
Wiadomo więc, że dźwięk to rozchodząca się we wszystkich kierunkach fala, którą można przedstawić na wykresie. To, co widzimy na wykresie jest niemal bezpośrednio nanoszone na najpopularniejsze analogowe nośniki dźwięku – na płytę winylową i na taśmę magnetyczną. Skoro jest to wykres, to można go zapisać pewnie w postaci funkcji. Wykresy, funkcje... od razu z przerażeniem można zdać sobie sprawę, że to wszystko można wyrazić matematycznie. Matematyka kojarzy się jednak nie tylko z traumą ze szkoły, ale też z komputerami, które w gruncie rzeczy są przerośniętymi kalkulatorami.
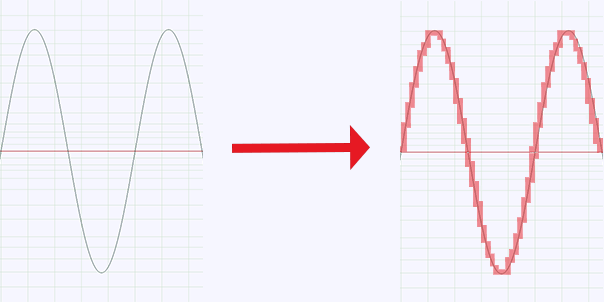
Wykres fali dźwiękowej można zapisać w formie cyfrowej, ale trzeba pokonać kilka problemów. Przede wszystkim, odwzorowanie fali dźwiękowej nie będzie dokładne. Odwzorowanie fali następuje poprzez dokonywanie pomiarów jej natężenia wiele razy w ciągu sekundy. Takie pomiary nazywają się próbkowaniem (sampling).
Na powyższym wykresie kolorem czarnym oznaczoną mamy „analogową” falę dźwiękową, zaś czerwone „schody” to cyfrowe odwzorowanie jej. Zwrócicie pewnie uwagę na to, że nie jest to zbyt precyzyjne – ale jest to tylko wykres poglądowy. Ponadto, matematyczny opis fali dźwiękowej jest na tyle dokładny, że podczas odtwarzania jest ona w pełni przywracana do oryginalnej, analogowej formy. Jak by tego było mało, ilość próbek (pomiarów) na sekundę wynosi zwykle ok. 44 tysiące razy, a każdy z tych razy opisany jest kilkudziesięcioma tysiącami wartości liczbowych.
To już brzmi trochę znajomo – płyta Audio CD i większość plików muzycznych na naszych komputerach, „empetrójkach”, czy telefonach, to pliki o częstotliwości próbkowania (sampling rate) wynoszącej 44100Hz (lub 44.1kHz). Istnieje jeszcze druga rzecz mająca znaczenie w cyfrowym dźwięku, mianowicie precyzja pomiarów. Ta określana jest za pomocą bitów, a dokładniej głębi bitów. Najczęściej jest to 16.
Powróćmy do częstotliwości próbkowania. Ma ona bezpośredni związek z maksymalną częstotliwością dźwięku, jaką można zarejestrować i odtworzyć. Częstotliwość dźwięku (odległość między falami dźwięku – o czym wspominaliśmy wcześniej) określa jego wysokość. Ludzkie ucho jest w stanie usłyszeć ok. 20kHz. Dźwięki o większej częstotliwości to tzw. ultradźwięki. Są ludzie, którzy twierdzą, że słyszą dźwięki powyżej 20kHz – nie będziemy tutaj wątpić w ich istnienie, choć warto wspomnieć, że 20kHz są w stanie usłyszeć tylko niektórzy... i tylko młodzi. Wraz z wiekiem narząd słuchu traci precyzję – słuch dorosłej osoby kończy się zwykle w okolicach 16kHz.
Według teorii Harry'ego Nyquista, który już na początku XX wieku opracował zasady odwzorowania audio w formie cyfrowej, maksymalna częstotliwość zarejestrowanego dźwięku jest o połowę niższa od częstotliwości próbkowania. Czyli dźwięk zapisany na płycie CD Audio, o częstotliwości 44,1kHz, jest w stanie odwzorować dźwięki o częstotliwości 22kHz. Wydaje się więc to w zupełności wystarczające – przynajmniej dla większości ludzi.
Teraz słówko na temat głębi bitów. Co to oznacza, że plik audio ma właściwości 44.1kHz i 16 bitów? Bity te określają po prostu ilość szczegółów, które można zapisać dla każdej pojedynczej próbki. Dokładniej: podczas rejestrowania dźwięku cyfrowo, każda próbka opisywana jest za pomocą liczby. Im więcej bitów (zer i jedynek), tym dokładniejsze odwzorowanie danego sampla i całej fali dźwiękowej.
Podczas takiego zapisu powstają pewne przekłamania, określane mianem błędów kwantyzacji (kwantyzacja to właśnie proces opisu próbki za pomocą bitów), co w praktyce oznacza... szum. Im mniej bitów, tym więcej przekłamań w zapisanym dźwięku. Im więcej bitów przeznaczymy na opis próbki, tym te błędy są mniej znaczące. Dlatego 8-bitowe nagranie jest wyraźnie słabszej jakości od 16 bitowego i najczęściej charakteryzuje się tym, że szumi.
Trochę matematyki będzie teraz potrzebne. Komputery liczą w systemie binarnym, czyli składającym się tylko z dwóch cyfr: 0 i 1. Osiem bitów oznacza, że jest możliwość zapisania ośmiu cyfr o wartościach 0 lub 1 – czyli 2 możliwe wartości, osiem pozycji, zatem 2^8, czyli w systemie dziesiętnym będzie to liczba od 0 do 255 (czyli 256 możliwych wartości). Jeśli zwiększymy głębię bitów z ośmiu do szesnastu, będziemy mieć 2^16, co da nam wynik 65536 (od 0 do 65535).
Wniosek jest następujący: ośmiobitowe nagranie będzie używać 256 możliwych wartości dla każdej pojedynczej próbki dźwięku. Szesnastobitowe nagranie może już spożytkować 65536 wartości. Jeśli zwiększymy głębię bitów do 24, otrzymamy aż 16777216 wartości.
Skoro 44,1kHz i 16 bitów wystarcza do zapisania dźwięku o jakości CD Audio... po co wyższe wartości? Co daje 48kHz i 24 bity? Po co komuś 192kHz?
Wspomniałem już, że ilość bitów na próbkę ma wpływ na szum, a dokładniej stosunek sygnału do szumu. To z kolei ma znaczenie przy zakresie dynamicznym, czyli najcichszym i najgłośniejszym możliwym do odwzorowania dźwiękiem. 16 bitowy plik audio pozwala na uzyskanie zakresu dynamiki na poziomie 96dB – jest to wartość podobna, a nawet nieco większa od zakresu płyt winylowych i kaset (które są w stanie odtworzyć 80-90dB). Jeśli zwiększymy ilość bitów do 24, zakres dynamiki zwiększa się do 144dB.
Od jakiegoś czasu coraz popularniejsze stają się pliki audio „HD”, które mają zagwarantować wyższą jakość niż standardowe dla CD Audio 44kHz/16bit. Co daje nam rozdzielczość 96kHz/24bit? Zakres dynamiki 144dB i odwzorowanie częstotliwości dźwięków do 48kHz. Jak pisałem wcześniej, większość ludzi potrafi usłyszeć dźwięki do ok. 20-22kHz. Wszystko powyżej, to ultradźwięki, słyszalne z reguły tylko przez zwierzęta. Ludzie, którzy twierdzą, że słyszą różnicę między 44,1kHz a wyższymi częstotliwościami próbkowania nie muszą jednak kłamać. Nawet jeśli nie są w stanie usłyszeć np. pisku o częstotliwości 48kHz, to przestrzeń powyżej 20-22kHz może sprawiać, że dźwięk reprodukowany jest nieco naturalniej. Większa głębia bitów z kolei może przełożyć się na lepszą reprodukcję niskich częstotliwości (których wykres fali jest „rozwlekły”, więc opisywać go musi większa ilość bitów). Jest to jednak tematem wciąż trwających debat - „ślepe” testy, kiedy odsłuchujący nie wie o jakiej jakości dźwięku słucha muzyki, nie są w pełni rozstrzygające.
Czy zatem pliki audio „HD” nie mają w ogóle sensu? Wydaje się, że... nie. O ile rejestrowanie audio przy najwyższej możliwej jakości sens ma (obróbka dźwięku lubi wysoką precyzję), to wyszukiwanie nagrań np. 24-bit i 192kHz sensu nie ma. Są to jedynie przerośnięte pliki!
Zakres reprodukowanych częstotliwości od 20Hz do 22kHz jest i tak bardzo szeroki – mało kto słyszy powyżej 20kHz, a dźwięki tak niskie jak 20Hz są bardziej odczuwalne fizycznie niż autentycznie słyszalne.
Każdy wzmacniacz generuje mniejszy lub większy przester (zniekształcenia), szczególnie przy bardzo niskich i bardzo wysokich częstotliwościach. Z pewnością każdy z Was słyszał co dzieje się z dźwiękiem kiedy przesadzi się z pokrętłem „volume” - występuje wtedy nie tylko dudnienie basu, które pierwsze „rzuca się w uszy”, ale także duże zniekształcenie dźwięków wysokich. Co to ma za znaczenie? Ano takie, że im więcej wysokich dźwięków, tym większy przester. Odtwarzając nagranie o częstotliwości 192kHz, czyli reprodukujące dźwięki do 96kHz, dodajemy ogromną ilość niesłyszalnych dźwięków, które doprowadzą wzmacniacz do przesteru szybciej, niż nagranie „ucięte” przy 22kHz. Przester przy tych częstotliwościach wpływa na niższe, zatem... plik audio o 192kHz w rzeczywistości będzie słabszej jakości niż 44,1kHz!
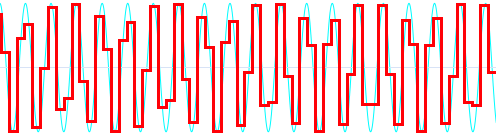
Nawet jeśli ktoś pokaże Wam taki wykres:
udowadniając, że niebieska fala dźwiękowa została zmasakrowana do formy czerwonej (cyfrowej) i przez to dźwięk utracił jakość... przypomnijmy sobie o czym wspomniałem na samym początku: matematyczny opis fali dźwiękowej jest na tyle dokładny, że fala zmieniana z powrotem na analogową, jest dokładnie taka sama jak fala wejściowa. Przy częstotliwości próbkowania wynoszącej 44.1kHz każdy zarejestrowany dźwięk o połowie tej częstotliwości, czyli maksymalnie 22,05kHz, podczas odtwarzania, czyli zamieniania go z powrotem z formy cyfrowej na analogową, będzie identyczny. Nie ma więc mowy o tym, że większa częstotliwość próbkowania, np. 192kHz, wpłynie pozytywnie także na te słyszalne częstotliwości tylko dlatego, że dźwięk analizowany jest częściej w ciągu sekundy.
Każdy zainteresowany dużo bardziej szczegółowym opisem tematu bezcelowości istnienia wysokich częstotliwości próbkowania i głębi bitów powinien odwiedzić m.in. ten artykuł. Wniosek jest jeden: nie ma sensu „rzucać się” na dużo ważące pliki obiecujące wyższą jakość dźwięku. Jeśli jednak chcielibyście wyższą jakość... trzeba zwrócić uwagę na zupełnie inny fenomen, któremu poświęcony jest jeden z kolejnych działów – o wojnie głośności.
Kompresja stratna i bezstratna
Dźwięk o jakości CD Audio charakteryzuje się dużą objętością. Przy stereofonicznym nagraniu o 16-bitowej głębi bitów i częstotliwości próbkowania 44,1kHz, każda sekunda składa się z 1,411,200 bitów, czyli 1378kb/s, co ostatecznie daje nam rozmiar 172kB.
Aby było możliwe przesyłanie dźwięku o takiej jakości przez internet, potrzebny byłby nieprzerwany strumień 1378 kilobitów na sekundę. Nie jest to może szczególnie dużo dziś, kiedy domowe łącza o prędkości 60 Megabitów nie wywołują większego szoku, ale cofając się ponad 10 lat wstecz, kiedy coraz popularniejsze stawały się internetowe stacje radiowe okazuje się, że jednak jest to dość sporo.
Nie ma dziś chyba takiej osoby, która nie wie co to jest „empetrójka”. Pliki z rozszerzeniem mp3 to dla wielu po prostu plik z muzyką. Nie każdy zastanawia się jak to się dzieje, że podczas gdy nieskompresowany plik WAV zajmuje 70MB przestrzeni dyskowej, ten sam fragment dźwięku w postaci pliku mp3 „waży” już np. jedynie 7MB. Jeśli czytasz ten artykuł, pewnie chcesz się dowiedzieć, więc... zaczynamy.
Zacznę może od wyjaśnienia czym jest kompresja. Jest to też pojęcie znane niemal każdemu użytkownikowi komputerów – prędzej czy później musi nastąpić sytuacja, że potrzebujemy coś rozpakować lub skompresować, bo np. używane przez nas konto pocztowe nie chce przepuścić nieco przerośniętego dokumentu, krzycząc, że plik jest zbyt duży. Taka kompresja danych polega na (również w dużym uproszczeniu) wyszukiwaniu podobnych ciągów zer i jedynek oraz zapisywaniu informacji o nich. Pewne ciągi bitów po prostu powtarzają się – dla przykładu, jeśli w pliku zapisane jest dwadzieścia zer występujących jedno po drugim, można skrócić ten zapis z 00000000000000000000 do „20 zer”. Popularne dziś formaty kompresji, takie jak zip, rar, czy 7zip, używają bardzo wyrafinowanych metod kompresji danych. Rozpoznają typ pliku i dobierają odpowiednie, skomplikowane algorytmy, których zadaniem jest zmniejszenie rozmiaru pliku, ale nie uszkodzenie go. Po rozpakowaniu archiwum musi być utworzony plik identyczny z oryginalnym.
W przypadku dźwięku, podobnie jak w grafice, stosowane są dwie metody kompresji: stratna i bezstratna. Każdy internauta widział obrazki w formacie JPG, które wyglądają fatalnie – przekłamania kolorów, artefakty w postaci kwadracików. To jest właśnie przykład kompresji stratnej, dość skrajny, gdyż odpowiednio dobrane parametry kompresji powinny pozwolić na uzyskanie obrazu o takiej jakości, że widz nie powinien być świadom, że ogląda rzecz pozbawioną szczegółów. Kiedy kopiujemy zdjęcia z telefonu lub aparatu, najczęściej widzimy pliki JPG – zajmują po kilka megabajtów, ale mało kto zdaje sobie sprawę z tego, że są one właśnie skompresowane z utratą szczegółów. Algorytmy stosowane przez producenta aparatu są tak dobrane, abyśmy nie zdawali sobie z tego sprawy – aby utrata szczegółów następowała w obszarach tak mało widocznych, że... można by rzecz, niewidocznych.
Na podobnej zasadzie działa kompresja stratna dźwięku. Formaty typu mp3, aac, czy ogg, stosują pewne skomplikowane działania matematyczne, których zadaniem jest ograniczenie liczby szczegółów. Skoro dorosły człowiek z reguły nie słyszy dźwięków powyżej 15-16kHz, to po co mają one zajmować miejsce na dysku? Można je po prostu w drastyczny sposób obciąć i wyrzucić lub zastosować pewne rozwiązania służące zmniejszeniu ich szczegółowości – i tak mało kto to usłyszy, a jeśli nawet ktoś usłyszy, to pewnie się nie zorientuje.
Tak w uproszczeniu działają empetrójki, ale za chwilę trochę bardziej zagłębimy się w ten temat. Nie chcę, aby ten artykuł był aż tak trywialny. Zanim to nastąpi, słów kilka o kompresji bezstratnej. Możemy duży plik WAVE skompresować za pomocą np. WinRara. Ulegnie on nierzadko dość znacznemu zmniejszeniu, ale... pewnie dałoby się zrobić to lepiej oraz to jest to dodatkowe utrudnienie. Plik trzeba najpierw rozpakować, zanim uda się go odtworzyć. Programiści wpadli więc na pomysł, że można opracować bardziej efektywne metody kompresji dźwięku poprzez zastosowanie algorytmów przeznaczonych specjalnie dla dźwięku i utworzyć format, który byłby odtwarzalny bezpośrednio przez oprogramowanie oraz np. przenośne odtwarzacze. Najpopularniejszy okazał się być FLAC – nietrudno znaleźć przenośne odtwarzacze potrafiące go odczytać, potrafią to też domowe sprzęty hi-fi, nie wspominając już o telefonach komórkowych.
Wspominałem już wcześniej o tym, że w najlepszym wypadku człowiek słyszy częstotliwości maksymalnie do ok. 20kHz. Dużą rolę w tej kwestii pełni nie tylko ucho, będące mechanicznym wzmacniaczem dźwięku, ale także sam mózg. Większość dorosłych osób nie słyszy wysokich dźwięków powyżej 16kHz, ani niższych (bardziej basowych) niż 20Hz. Uszy najbardziej wyczulone są na zakres od 2 do 5kHz.
Format stratnej kompresji dźwięku, taki jak MP3, bierze to pod uwagę. Niskie i wysokie częstotliwości są obcinane całkowicie przy niższej jakości, zaś przy wyższej – tracą na szczegółowości. To nie wszystko – brane są pod uwagę inne tzw. psychoakustyczne właściwości audio. Na przykład, przysłanianie (maskowanie) częstotliwości. Dwa dźwięki o podobnej częstotliwości, np. 100 i 110Hz, o różnej sile natężenia, odtwarzane równocześnie. Jeśli jeden z nich będzie głośniejszy, jest duża szansa, że na tyle przysłoni ten cichszy, że usłyszymy tylko jeden z nich – ten głośniejszy. Algorytmy stosowane przez kompresory starają się ocenić takie sytuacje i zdecydować o ewentualnym całkowitym wycięciu dźwięków, których nie usłyszymy.
Do zakodowania dźwięku w formacie MP3 potrzebujemy pierw źródła, czyli nieskompresowanego dźwięku w formacie PCM (czyli zwykły Wave). Na początku, koder dzieli strumień audio na krótkie sekcje i analizuje je za pomocą specjalnych filtry (Fast Fourier Transformation – FFT, Discrete Cosine Transformation – DCT). Każda sekcja dzielona jest następnie na 32 grupy, w których umieszczane są dźwięki należące tylko do specyficznych przedziałów częstotliwości (np. jedna grupa zawiera tylko najniższe częstotliwości). Każda z nich analizowana jest oddzielnie i przydzielany jest im priorytet: które z nich są najbardziej słyszalne, które można zapisać z większą ilością bitów, a które z mniejszą (poświęcając więcej bitów np. na wokal). Później wszystko grupowane jest z powrotem, ale znów dzielone na tzw. ramki. Koder analizuje następnie każdą z nich i ponownie przypisuje mniejszą lub większą ilość danych (bitów) do jej opisania.
Występuje także jeszcze jedna opcja, z której korzysta większość koderów MP3. Mianowicie: joint-stereo. Metoda ta pozwala na zapisanie większej jakości dźwięku przy tym samym rozmiarze pliku w pewien ciekawy sposób. Często jest tak, że pewne dźwięki są identyczne w obu kanałach – np. perkusja, czy wokal, znajdują się z reguły w samym centrum. Po co więc opisywać te same dane dla obu kanałów dwukrotnie? Joint-stereo (inaczej middle/side stereo) polega na tym, w dwóch kanałach dźwięku nie są zapisywane kanały lewy i prawy oddzielnie – w jednym zapisywane są wszystkie dźwięki, które są identyczne dla obu kanałów stereo, zaś w drugim zapisywana jest różnica między nimi. Czytając dokumentację LAME można znaleźć zalecenie, by nie wyłączać trybu joint-stereo, gdyż jest to tryb o najwyższej jakości.
W ten sposób utworzony plik można następnie odtworzyć za pomocą specjalnego dekodera, który odwraca ten proces, ale jest przy tym dużo prostszy i potrzebuje znacznie mniejszej mocy obliczeniowej.
Głównym czynnikiem wpływającym na jakość utworzonej empetrójki jest tzw. przepływność bitów, czyli liczba bitów opisująca każdą sekundę zarejestrowanego dźwięku. Jak wspomniałem wcześniej, każda sekunda nieskompresowanego strumienia PCM (Wave) opisana jest za pomocą 1378 kilobitów. W przypadku formatu MP3 mamy do czynienia z wartościami typu 128, 160, 192, czy maksymalnie 320 kilobitów na sekundę. Możliwe jest też zapisanie dźwięku z tak niskimi wartościami jak 16kb/s – spada jednak wtedy maksymalna częstotliwość dźwięku i jest to dość skrajna metoda zapisu np. audycji radiowych. Widzimy zatem, że przepływność bitów empetrójki znacznie mniejsza ilość danych, bezpośrednio przekładając się na rozmiar pliku na dysku oraz na wymagania co do szybkości przesyłu danych przez internet w przypadku transmisji „na żywo” w sieci.
Wszystkie inne metody kodowania dźwięku metodami stratnymi działają na mniej więcej podobnej zasadzie. Warto pamiętać o tym, że MP3 to format bardzo stary – początki jego opracowywania sięgają 1991 roku. Dostępne dziś metody w postaci AAC (formatu opracowanego 6 lat później przez to samo konsorcjum Fraunhofer, które opracowało MP3), OGG Vorbis i inne, najczęściej potrafią zapisać dźwięk znacznie bardziej szczegółowy niż MP3. Dla przykładu, uważa się, że Ogg Vorbis o jakości 160kb/s posiada jakość zbliżoną lub lepszą do MP3 320kb/s.
Kompresja dynamiki, czyli wojna głośności
Pojęcie kompresji występuje także w innym znaczeniu niż redukcja rozmiaru komputerowego pliku. Opisując głębię bitów wspomniałem o możliwym do zarejestrowania i odtworzenia zakresie dynamiki dźwięku. Najprościej wyjaśnić to na przykładzie muzyki klasycznej, w której występują największe wahania dynamiki. Gra na flecie będzie naprawdę bardzo cicha w porównaniu z momentem, kiedy zacznie grać cała orkiestra, składająca się z dużej ilości instrumentów, które same w sobie potrafią zagrać głośniej niż flet.
Dynamika dźwięku ma bardzo duże znaczenie we wzbudzaniu emocji u słuchacza. Cichutki wstęp na pojedynczym instrumencie sprawia, że kiedy zacznie grać orkiestra niemal podskoczymy w miejscu z wrażenia. W zależności od przekazu utworu, może to pogłębić uczucie radości lub smutku.
Często w dyskusjach o wyższości analogowego zapisu dźwięku nad cyfrowym, podnoszony jest temat dynamiki. Mówi się, że cyfrowe nagrania są niemal z niej ogołocone, podczas gdy z płyty winylowej wręcz „wylewają” się emocje. Internet pełny jest porównań np. płyty grupy Red Hot Chilli Peppers pod tytułem Californication. Wersji CD niemal nikt nie lubi – w porównaniu z winylowym wydaniem jest ona niemal totalnie płaska i... nieco paradoksalnie, ale... trzeszczy! Tak, moi drodzy: płyta CD okazuje się trzeszczeć, pomimo tego, że to płyta winylowa jest tą określaną od zawsze jako tą trzeszczącą. Do opisu tego fenomenu wrócimy za chwilę.
Dlaczego tak się dzieje, że kiedy podłączymy gramofon do karty dźwiękowej komputera, uruchomimy program do obróbki dźwięku i nagramy to, co wydobywa się z płyty winylowej, uzyskamy lepszy dźwięk niż na specjalnie przygotowanej płycie CD? Jak to jest, że w epoce, kiedy większość płyt nagrywa się w studiu w metodami cyfrowymi, płyta CD brzmi gorzej niż płyta „analogowa”?
Wszystko stanie się jasne, kiedy zrozumiemy pewien inny fenomen. Otóż ludzki mózg zwraca większą uwagę na dźwięk głośniejszy od poprzedniego. Jeśli słuchając teraz cicho muzyki, nagle kolejny utwór na liście odtwarzania będzie od poprzedniego dwukrotnie głośniejszy, zwrócimy na niego większą uwagę. Z tego faktu postanowili skorzystać ludzie, którzy najczęściej o muzyce nie mają większego pojęcia – rozumieją tylko pieniądze. Chodzi o prezesów firm fonograficznych, ich księgowych i niektórych producentów. Pewnego dnia stwierdzili oni, że jeśli wydamy głośniejszą płytę niż konkurencja, ludzie zwrócą na nią większą uwagę i zakupią większą liczbę kopii.
Poniekąd mają rację. Niestety, wraz z rozwojem cyfrowej techniki obróbki dźwięku oraz z rozpędu w dążeniu do największej głośności przekroczono moment, w którym to wszystko ma sens. Przekroczono poziom, powyżej którego jakość dźwięku traci.
Dodatkowym wytłumaczeniem przemawiającym za „wojną głośności” jest sposób, w jaki większość z nas wydaje się słuchać muzyki. Najczęściej widzimy ludzi spacerujących po mieście, jadących autobusem, pociągiem, itp., ze słuchawkami w uszach. Aby wszystkie dźwięki dotarły do ich uszu, muzyka powinna być skompresowana dynamicznie, gdyż w przeciwnym razie dźwięki zbyt ciche zostaną przysłonięte przez miejski hałas. Co jednak z ludźmi, którzy preferują jednak odsłuch muzyki w domowym zaciszu, przy zgaszonym świetle i w wygodnym fotelu? Cierpią.
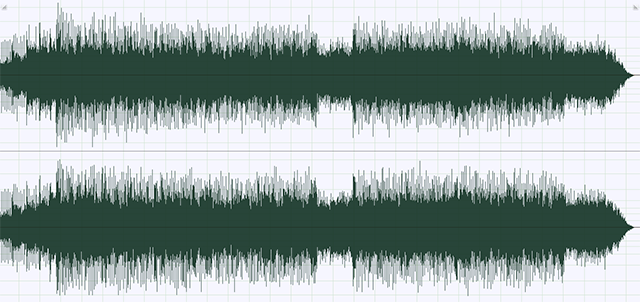
Spójrzmy na stare nagranie z lat osiemdziesiątych, a dokładniej na jego wykres fali dźwiękowej:
Widzimy duże wahania fali i po samym spojrzeniu na nią możemy domyśleć się, że mamy do czynienia z muzyką, a nie hałasem młota pneumatycznego. Spójrzmy teraz na ten sam utwór, ale wydany w ramach remasterowanej reedycji tego samego albumu:
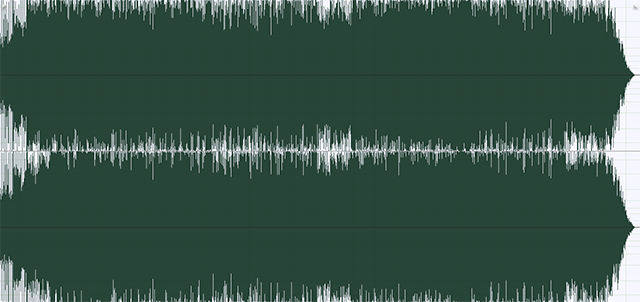
Wszystkie maksymalne wychyły fali dźwiękowej zostały spłaszczone. Do pewnego stopnia ma to sens – czasami fala dźwiękowa może wystrzeliwać bardzo do góry lub dołu, ale nie być w praktyce słyszalna. Dzięki kompresji dynamiki można ją przyciąć i pogłośnić. Kiedy jednak przesadzimy, zobaczymy taki wykres... nie można już na oko stwierdzić, czy to jest muzyka, czy jakieś efekty dźwiękowe, a może nawet biały szum (jak radio FM między stacjami).
Warto nadmienić, że – co widać na powyższych wykresach – cyfrowe pliki audio mają pewną przestrzeń. Maksymalną głośność określa się mianem 0dB. Nie ma możliwości zapisania głośniejszego dźwięku. Jeśli zaczniemy ograniczać wychyły fali, pozwoli to na pogłośnienie całości, ale wraz z utratą dynamiki – wykres po prostu mniej skacze. W ramach „wojny głośności” posunięto się jednak tak daleko, że fala próbuje przekroczyć 0dB. Prawidłowo wyprodukowana płyta powinna „gładko” ograniczać maksymalne wychyły (peaki), ale obecnie nagminne jest, że są one drastycznie obcięte i na wykresie przedstawiane są jak... linia prosta. Występuje wtedy nieprzyjemny przester: trzask. Stąd płyta CD może trzeszczeć w większym (bo bardziej wychwytywanym i nieprzyjemnym) stopniu niż winylowa!
Czym odznacza się negatywny wpływ ograniczenia dynamiki dźwięku? Ciche, gitarowe intro przestaje być cichsze od całego zespołu, w skład którego wchodzą dwie gitary elektryczne, gitara basowa, perkusja i klawisze. Efekt rosnącego napięcia emocjonalnego w utworze został zredukowany lub zniwelowany całkowicie. Ponadto, w dalszej części utworu widzimy brak specyficznych peaków fali dźwiękowej. To jest perkusja – jej dźwięk został spłaszczony, przez co została jak by przesunięta do tyłu, że zaczęła stanowić tło dla utworu zamiast być jego siłą napędową.
Obrazki i słowa to za mało, by opisać tą sytuację, ale internet pełen jest dużo lepiej przemawiających przykładów, jak chociażby poniższy filmik:
Bardzo dokładnie przedstawia on w czym rzecz. Dlaczego dzisiejsza muzyka wydaje się być płaska i bez życia? Bo tak została nagrana. A dokładniej – tak została „obrobiona” w procesie masteringu, czyli przygotowywania płyty CD do tłoczenia. Proces masteringu (lub premasteringu) polega na ustaleniu równej głośności wszystkich poszczególnych utworów, ustaleniu przerw między nimi, mniejszymi lub większymi poprawkami za pomocą equalizera itp. Dziś do tego ważnego elementu produkcji płyty dołączyła przesadzona kompresja dynamiki. Bo to trzeba powiedzieć: kompresja dynamiki jest potrzebna. To dzięki ograniczaniu zakresu dynamiki np. wokalistki jesteśmy w stanie usłyszeć ją pomimo ściany elektrycznych gitar. Jest to nieodzowny element w studiu nagraniowym... pod warunkiem, że wykorzystywany jest prawidłowo, czyli w celu, w którym został stworzony.
Dlaczego płyty winylowe nie cierpią z powodu wojny głośności? Z powodu technicznego ograniczenia, które w tym przypadku jest ogromną zaletą. Im głośniejszy dźwięk, tym rowki na płycie są szersze. Im szersze rowki tym większe ryzyko, że... igła może wręcz wyskoczyć ze ścieżki i przeskoczyć obok. Z tego powodu zakres dynamiki i głośność nagrania na takiej płycie musi być dość ściśle kontrolowany. Biorąc to wszystko pod uwagę, płyta CD pozwala na zarejestrowanie dźwięku o większej dynamice niż płyta „analogowa”. Tylko co z tego, skoro dzisiejsza muzyka w formie cyfrowej, przedstawiona wykresem fali dźwiękowej, wygląda nierzadko jak kwadrat? Choćbyśmy ściągali z internetowych sklepów pliki FLAC posiadające 64 bity... nic by to nie zmieniło. W porównaniu z 16-bitową płytą CD brzmiałyby one identycznie, zasięg dynamiczny byłby tak samo mały.
Na szczęście, w ostatnich latach nastąpił duży wzrost świadomości w tym temacie. Producenci muzyczni zaczynają się buntować (choć wielu z nich mówi, że jeśli nie zmasakrują muzyki „wojną głośności”, wytwórnia znajdzie innego producenta, który to zrobi), inżynierowie zajmujący się masteringiem wypowiadają się coraz głośniej przeciwko rujnowaniu muzyki. Powstały inicjatywy w postaci fundacji, które chcą przekonywać producentów i inżynierów do postawienia się dyrektorom firm fonograficznych. Niektórzy muzycy stwierdzili, że nie będą nagrywać płyt w ten sposób – w ostatnich latach ukazało się kilka albumów, które brzmią świetnie, na których nie zastosowano żadnej dodatkowej kompresji, a wręcz całkowicie pominięto proces (pre)masteringu. Na płycie CD dostajemy dokładnie to, co słyszał artysta w studiu nagraniowym.
Na koniec tego rozdziału wspomnę tylko o jednej rzeczy: muzyk nie musi o tym wszystkim wiedzieć. Muzyk może nie być w stanie rozróżnić dynamicznego nagrania od silnie skompresowanego... i niczego złego w tym nie ma. Nierzadko kiedy muzyk doskonale zdaje sobie z tego wszystkiego sprawę... po prostu nie słucha swoich własnych płyt. On wie, co nagrał, bo słyszał to w studiu nagraniowym, kiedy znajdował się tam ze swoim producentem. Miłośnicy muzyki często nie rozróżnią lub po prostu nie zwracają uwagi na dynamiczne lub niedynamiczne utwory. Mało tego – stacje radiowe korzystają z własnych kompresorów dynamiki, więc nie może być mowy o tym, że utwór jednego wykonawcy będzie głośniejszy od innego i przez to popularniejszy. Podobnie w popularnym serwisie muzycznym Spotify, który korzysta z metody wyrównywania poziomu dźwięku metodą zwaną „replay gain”. Głośność płyty nie wpływa także pozytywnie na jej sprzedaż. Negatywnie też nie, choć kilkadziesiąt podpisów pod petycją o ponowne zmiksowanie lub zremasterowanie ostatniej płyty grupy Metallica może wskazywać, że ludzie są jednak niezadowoleni.
Jaki jest sens tej wojny głośności? No właśnie... nie ma go.
Podsumowanie
Myślę, że ten artykuł przybliżył nieco przedstawione w nim pojęcia. Jeśli tematyka zainteresowała Was bardziej, internet pełen jest dużo bardziej szczegółowych opisów, łącznie z niezliczonymi wzorami matematycznymi i fizycznymi, które autora osobiście przerażają.
Mój opis dźwięku analogowego i cyfrowego nie jest zbyt dokładny i z pewnością znajdą się Czytelnicy, którzy wiedzą o tym więcej i z pewnością w komentarzach o tym powiedzą.
Kilka lat temu, kiedy oprogramowanie służące do tworzenia plików MP3 nie było zbyt dobre, nie było trudno odróżnić dźwięk skompresowany od płyty audio CD. Dźwięk stawał się sztuczny, metaliczny, szeleszczący. Dziś, kiedy najpopularniejszym koderem jest LAME, okazuje się, że empetrójki są często „przeźroczyste”, czyli nie do odróżnienia od nieskompresowanego źródła. Wytrenowane ucho z pewnością wykryje w pewnych przypadkach mniejszą szczegółowość skompresowanego audio, ale większość „niedzielnych słuchaczy” tego nie potrafi. Miłośnik perfekcyjnej jakości dźwięku, z jedynie początkowymi objawami audiofilii, będzie wolał zaopatrywać się w pliki o bezstratnej kompresji – nawet niezależnie od tego, czy potrafi rozpoznać empetrójkę.
Osoby, które można by nazwać audiofilami, pewnie będą sprzeczać się ze mną w kwestii audio o wyższej jakości niż 44,1kHz/16 bit i próbować będą udowodnić, że nie jest to „audio voodoo” oraz, że odpowiednio drogi sprzęt, z koniecznie drogimi kablami zasilającymi (za które nierzadko można kupić niezły samochód) wydobędzie z plików 192kHz/24 bit wszystko co najlepsze i pokaże, jak bardzo 44,1/16 jest niedoskonałe. Dyskusja na ten temat toczy się od dawna i wszystko wskazuje na to, że toczyć się będzie.
Nawet jeśli by uznać, że odpowiedni sprzęt pozwoli na to, by pliki „HD” brzmiały autentycznie lepiej, to i tak wszystko przestaje mieć znaczenie w obliczu „wojny głośności”, kiedy to standard 44,1/16 nie jest wykorzystywany nawet w połowie tak, jak powinien. Świadome rujnowanie muzyki tylko po to, by była ona jak najgłośniejsza osiągnęło już szczyt. Trudno wyobrazić sobie płyty głośniejsze i o bardziej zniszczonym dźwięku niż Metallica „Death Magnetic”... ale ostatnia płyta Justina Biebiera nagrana jest jeszcze głośniej! Wszystko po to, aby to piosenka Biebera wydała nam się lepsza od słuchanego przed chwilą King Crimson...
Na zakończenie proszę Was o komentarze – szczególnie istotne, jeśli znajdziecie jakieś błędy, których wytknięcie będzie przeze mnie szczególnie mile widziane.