|
TwojePC.pl © 2001 - 2026
|
 |
RECENZJE | Potokowanie - pluskanie się w potoku z Pentium4 |
 |
| |
|
Potokowanie - pluskanie się w potoku z Pentium4
Autor: Stefan | Data: 12/10/01
|
 Większości z Was zapewne nie umknęło stwierdzenie, iż najnowszy procesor Intel Pentium4 ma zaimplementowaną technikę - w wolnym tłumaczeniu - 20 poziomowego potokowania. Ci z Was, którzy nie śledzą najnowszych wydarzeń, pamiętają na pewno magiczny termin pipeline burst cache. Czym właściwie jest potokowanie? Starałem się uczynić poniższy tekst jak najbardziej przystępnym. Czy mi się udało? Oceńcie sami! Jednak z ręką na sercu mogę obiecać, iż ci z Was, którzy tylko przejrzą tekst, będą mogli zapędzić w kozi róg większość "speców", gdy dyskusja zejdzie na tematy typu - Wydajność procesorów najnowszej generacji. Większości z Was zapewne nie umknęło stwierdzenie, iż najnowszy procesor Intel Pentium4 ma zaimplementowaną technikę - w wolnym tłumaczeniu - 20 poziomowego potokowania. Ci z Was, którzy nie śledzą najnowszych wydarzeń, pamiętają na pewno magiczny termin pipeline burst cache. Czym właściwie jest potokowanie? Starałem się uczynić poniższy tekst jak najbardziej przystępnym. Czy mi się udało? Oceńcie sami! Jednak z ręką na sercu mogę obiecać, iż ci z Was, którzy tylko przejrzą tekst, będą mogli zapędzić w kozi róg większość "speców", gdy dyskusja zejdzie na tematy typu - Wydajność procesorów najnowszej generacji. | |
|
Potokowanie - pluskanie się w potoku z Pentium4
Przetwarzanie rozkazów
Potokowanie pochodzi od angielskiego słowa "pipelining" i oznacza pewien określony sposób przetwarzania rozkazów przez procesor. Inżynierowie zawsze poszukują lepszych i bardziej efektywnych rozwiązań muszących jednocześnie spełnić wszystkie warunki ekonomiczne determinujące opłacalność produkcji. Czasami zamiast tworzenia zupełnie nowych rzeczy można w bardzo skuteczny sposób usprawnić już istniejące technologie.
Przetwarzanie rozkazów w procesorze podzielone jest na kilka oddzielnych etapów. Istnieje wiele rozwiązań , ale najczęściej przytacza się następujący podział:
- IF - pobranie rozkazu
- ID - dekodowanie rozkazu, które jest zwykle połączone z pobraniem operandów (danych) z rejestrów
- EX - wykonanie rozkazu
- W - zapis wyniku operacji
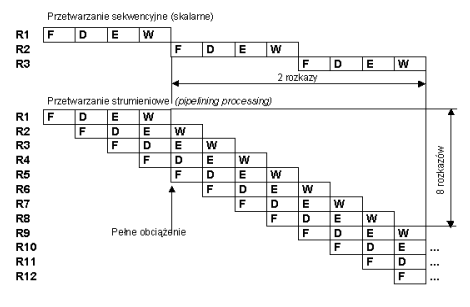
Zauważono, że jeżeli każdy z powyższych etapów wykonywany jest przez niezależne od siebie układy procesora to możliwe staje się jednoczesne przetwarzanie kilku rozkazów znajdujących się na różnych etapach wykonywania; w naszym przykładzie czterech. Do tej pory podczas wykonywania rozkazu, w danej chwili realizowany był tylko jeden etap, co za tym idzie reszta układów odpowiedzialnych za kolejne etapy była niewykorzystywana.
Zakładając, że każdy etap realizowany jest w czasie jednego cyklu zegara procesora to przy naszym - 4-etapowym potoku - uzyskujemy teoretycznie czterokrotne przyspieszenie wykonywania kodu! Wyniki będą generowane, nie co cztery cykle, ale w każdym cyklu zegarowym. Poniższy diagram powinien wyjaśnić wszelkie wątpliwości:
Czas na diagram
Arytmetyka
Teraz pora na, mam nadzieje, prostą arytmetykę. Jeżeli
- k - ilość etapów na jakie dzieli się wykonanie każdego rozkazu
- n - ilość wykonanych rozkazów
- t - częstotliwość taktowania,
to bez potokowania całkowity czas wykonania takiego programu wyniesie
Jeżeli zastosujemy potokowanie to nasz wzór przyjmie poniższą postać
przy czym
- k/t - to czas po jakim pierwszy rozkaz zostanie wykonany i po jakim potok się zapełni
- (n-1)t - czas wykonania reszty rozkazów
Do pokazania przyrostu sprawności wynikającej z użycia potokowania stosuje się tzw. współczynnik przyspieszenia S, który jest stosunkiem obu czasów, tzn. bez użycia potokowania do tego z użyciem potokowania.
Jak widać współczynnik przyspieszenia zależy od ilości stopni w potoku. Mam nadzieję, iż tą arytmetyką nie zniechęciłem Was zbytnio. Choć wybitny fizyk Stephen Hawking mawia, iż każda formuła matematyczna w książce lub artykule zmniejszą ilość jego czytników o połowę.
Ograniczenia potokowania
Częstotliwość wytwarzania wyników jest ograniczona przez czas trwania najdłuższego z etapów. Można zatem podejrzewać, że podział takiego etapu na podetapy dodatkowo zwiększy szybkość przetwarzania. Takie rozwiązanie gdzie dodatkowo dzielimy etapy na mniejsze części nazywane jest przetwarzaniem superpotokowym (superpipelined pipeline lub superpipeining). Należy pamiętać, że zbyt duża ilość podetapów - zwana głębokością potoku - nie będzie wpływać korzystnie na wzrost prędkości, wprost przeciwnie może być powodem zmniejszenia wydajności systemu. Związane to jest z opóźnieniami, generowanymi przez układy sterujące, których udział zwiększa się bardziej niż proporcjonalnie wraz z ilością etapów w potoku. Dodatkowe przyspieszenie przetwarzania można uzyskać dzięki współbieżnemu wykonywaniu rozkazów w bliźniaczych potokach. Taki rodzaj potokowania nazywamy potokowaniem superskalarnym.
Czy zawsze szybciej?
Nasze rozważania dotyczyły idealnego przypadku potoków bez zakłóceń. Zwróćmy uwagę na fakt, że czas wykonania pojedynczego rozkazu w skutek rozbudowanego sterowania oraz dodatkowych narzutów związanych ze ściśle określonym czasem trwania etapów jest dłuższy niż w przypadku zwykłego przetwarzania rekurencyjnego. Przy licznych zakłóceniach potoku możliwa jest sytuacja, iż czas wykonywania programu nie będzie się wyraźnie różnić dla metody potokowej i sekwencyjnej! Niestety wskutek zakłóceń i skoków potok musi być sztucznie wstrzymywany lub "czyszczony", co niekorzystnie modyfikuje współczynnik przyspieszenia.
Przy przetwarzaniu potokowym na każdy cykl powinien przypadać jeden wykonany rozkaz ,a w przypadku przetwarzania super skalarnego, kilka. Średnia liczba wykonanych rozkazów w cyklu nazywa się wydajnością (performance). Nominalna wartość zależy od struktury potoku, ilości podetapów. Rzeczywista wartość ze względu na konflikty danych, sterowania i dostępu jest zawsze mniejsza od nominalnej. Dla dowolnego potoku można ją określić jako odwrotność średniej liczby cykli przypadających na wykonanie rozkazu.
- P=p((1-b-r)+r(1+d)+bn)-1 [rozkaz/cykl]
- p - nominalna wydajność potoku
- n - głębokość potoku
- b - częstotliwość nieprzewidzianych skoków opóźniających potok o n cykli
- d - liczba opóźnionych cykli z powodu konfliktu danych
- r - częstotliwość konfliktów danych
Typy zakłóceń
Opowiedzmy zatem na pytanie - czym są owe tajemnicze zakłócenia w potoku zwane również konfliktami lub z angielska hazardami. Istnieją trzy zasadnicze grupy zakłóceń przepływów instrukcji w potokach. Ogólnie, hazardy to sytuacje, które powstrzymują wykonanie następnej instrukcji w potoku, podczas cyklu, który był dla niej przeznaczony. Powodują to, iż rzeczywisty wzrost prędkości wynikający z przetwarzania potokowego jest mniejszy niż w przypadku idealnym. Statystycznie rzecz biorąc, zdarzenia zakłócające płynne przetwarzanie potoku zdarzają się raz na sześć operacji, tak więc w znaczący sposób obniżają one wydajność. Wyróżniamy zatem następujące rodzaje hazardów:
HAZARDY STRUKTURALNE - Wynikają z konfliktów sprzętowych, niektóre kombinacje instrukcji nie mogą być wykonywane jednocześnie ze względu na konflikt zasobów.
HAZARDY DANYCH - Pojawiają się wtedy, gdy do obiektu danych (rejestry, komórki pamięci, rejestry flag) zwracają się lub zmieniają go dwa różne rozkazy umieszczone tak blisko w programie, że potokowanie powoduje zachodzenie na siebie ich wykonań: Wśród hazardów danych także wyróżniamy trzy typy:
- czytanie po zapisie (Read after Write) - RAW
- zapis po odczycie (Write after Read) - WAR
- zapis po zapisie (Write after Write) - WAW
Zakłócenie WAW istnieje, gdy oba rozkazy próbują zmienić ten sam obiekt, ale zapis wyników przez rozkaz i-ty może nastąpić później niż przez rozkaz j-ty. Wówczas w komórce pamięci znajduje się wartość nie od rozkazu j-tego lecz i-tego. Jeśli nie zrozumieliście tego fragmentu, to proszę przeczytajcie go jeszcze raz, bo wydaje mi się, iż prościej nie mogłem tego wyrazić. Jeśli jednak pozostałyby niejasności to proszę piszcie do mnie.
Zakłócenia RAW między rozkazami i oraz j powstaje podczas, gdy rozkaz j-ty próbuje czytać pewien obiekt zmieniany przez rozkaz i-ty. Jeżeli rozkaz i-ty nie zakończył się oraz nie zdążył zmienić tego obiektu do momentu, gdy rozkaz j-ty zwróci się do tego obiektu, to odczyta niewłaściwą informacje.
Dwa sposoby podejścia do usuwania zakłóceń:
ZATRZYMANIE POTOKU - Jeżeli ujawniono rozkaz j-ty, który znajduje się w stanie zakłócenia z wcześniejszym rozkazem i-tym, to wszystkie kolejne rozkazy są zatrzymane dopóki rozkaz i-ty nie przejdzie przez punkt krytyczny konfliktu.
ZATRZYMANIE ROZKAZU J-TEGO - Rozkazy j+1, j+2 są wpuszczane do potoku. Daje to rozkazom j+1,j+2 możliwość wyprzedzenia rozkazu j-tego przy takich badaniach na istnieje zakłóceń dla rozkazów j+1, j+2 należy również przewidzieć czy nie ma konfliktów z rozkazem j-tym. Jeżeli takie zakłócenie zostanie wykryte, to wykonanie tych rozkazów (j+1,j+2) także powinno być wstrzymane aż do momentu, gdy rozkazowi j-temu nie da się zezwolenia na kontynuowanie przejścia przez potok.
HAZARDY STEROWANIA - Występują na wskutek przetwarzania rozkazów skoków oraz rozkazów zmieniających licznik rozkazów.
Zakończenie
Potokowanie jest obecnie implementowane we wszystkich nowoczesnych rozwiązaniach i wiedza na jego temat jest niezbędna przy tworzeniu wydajnego oprogramowania na niskim poziomie. Czy wszyscy użytkownicy mogą skorzystać z zalet jakie niesie w sobie 20 poziomowe potokowanie najnowszego procesora Pentium4? Zaskakujące jest, iż odpowiedź na to pytanie zupełnie nie leży po stronie producentów sprzętu, ale oprogramowania! Przypomnijmy, iż statystycznie zakłócenia pojawiają się raz na sześć operacji. Poza tym, aby skorzystać z zalet 20 poziomowego potokowania programista od samego początku musi pisać swój program pod ten typ architektury! Nie dziwmy się więc, iż obecne testy nie wykorzystują możliwości drzemiących w Pentium4. Doświadczyli tego testerzy Pentium4 z Tom's Hardware. Początkowo, procesor ten otrzymał od nich zaszczytne wyróżnienie ZAKAZ WJAZDU. Później gdy Intel przesłał testerom dobrze zoptymalizowany program do skompilowania, redakcja oprócz zaszczytnego znaku dodała także ZNAK ZAPYTANIA. Później zaś debata stanęła w martwym punkcie... i Pentium4 został nazwany najbardziej kontrowersyjnym procesorem rodziny x86. Ostatnia uwaga, niejako na boku, jest taka, iż o sukcesie bądź porażce Pentium4 zadecydują twórcy oprogramowania! Jeszcze nigdy w historii nie byli oni tak ważni jak obecnie. Jeśli więc, kiedykolwiek będziecie toczyli debaty na temat wydajności procesorów, optymalizacji, oprogramowania, etc. to mam nadzieję, iż powyższy artykuł dostarczył Wam dobrych merytorycznie argumentów oraz, iż od tej pory słowo potok nie będzie się Wam jednoznacznie kojarzyć z wakacjami w górach.
|
|
|
Rozdziały: Potokowanie - pluskanie się w potoku z Pentium4 |
|
| |
|
|
 |
 |
 |
|
|
|
|
|
|
|
|
|
|
|
|

