Radeon X1800 XT - nowa architektura ATI
Autor: Kris | Data: 17/01/06
| |
|
Co w krzemie piszczy?

W zasadzie każda kolejna generacja kart reklamowana jest przez producentów układów jako rewolucyjna w zakresie technologii 3D. Niestety rzeczywistość wygląda nieco inaczej. Ostatni konkretny wkład w przetwarzanie 3D pojawił się półtora roku temu wraz z GF6800U, choć i jego trudno nazwać rewolucyjnym. Taką łatkę można natomiast z pewnością przylepić kartom Radeon 9700 Pro oraz GeForceFX 5800 Ultra. Inne premiery zdecydowanie niosły ze sobą jedynie aspekt wydajnościowy. Niezależnie od kwestii głębokości zmian mogę zaryzykować twierdzenie, że w dziedzinie premier architektury 3D w grupie kart Dx9 mieliśmy 2:1 dla nVidia i oczekiwałem od ATI wyrównania tego bilansu. No i z całą odpowiedzialności za słowa muszę przyznać, że się nie zawiodłem. Radeon X1800XT zdecydowanie pokazuje coś nowego kończąc tym samym ponad trzyletnią serie kart opartych na bardziej lub mniej "podpompowanym" rdzeniu R300.
(kliknij, aby powiększyć)
W tym miejscu niestety (dla mnie) muszę poświęcić trochę czasu na udowodnienie tej tezy. Najpierw jednak kilka słów o samym układzie. ATI R520 zawiera 321 mln tranzystorów, które upchano w krzemie 90 nm (+low-k). Mamy więc światowego rekordzistę wśród GPU w ilości tranzystorów oraz pierwszy układ graficzny wykonany w tej technologii. Przyjrzyjmy się mu bliżej.
Silnik wierzchołków
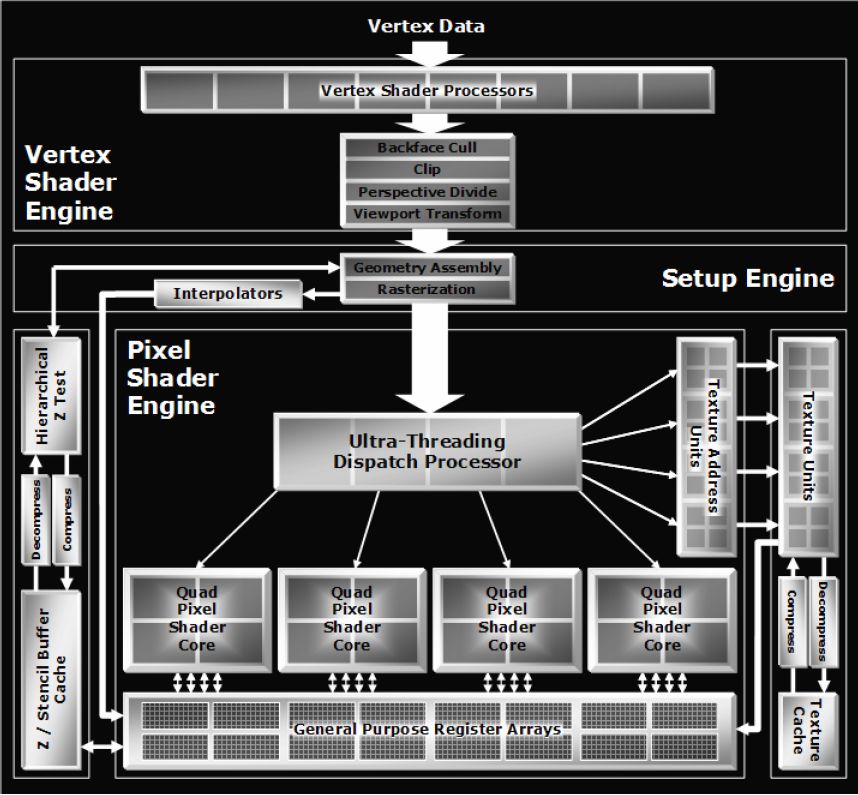
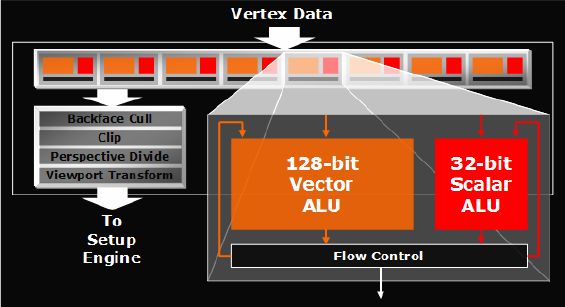
Podstawową zmianą jest dostosowanie jednostek arytmetycznych bloku obliczeń geometrii i oświetlenia do wymogów specyfikacji shaderów modelu 3 (SM3). W przypadku R520 kwestia dotyczy dodania dynamicznej kontroli przebiegu oraz możliwości operowania na teksturach. Każdy z procesorów Vertex może wykonać jednocześnie jedną instrukcję skalarną i jedną wektorową. Łącznie układ wyposażono w osiem takich procesorów dzięki czemu jest w stanie w jednym takcie zegara przetworzyć dwa wierzchołki. ATI chwali się możliwością wykonywania 10 miliardów instrukcji Vertex Shadera na sekundę.
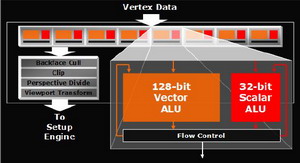
(kliknij, aby powiększyć)
Silnik Vertex w znacznym stopniu upodobnił się do konstrukcji nVidia, choć różnice oczywiście są. Jednostka arytmetyczna ATI może przetwarzać 128-bitowe instrukcje wektorowe natomiast GeForce operuje na "klasycznych", 32-bitowych. Ideą tego pomysłu była możliwość emulowania procesora na układzie graficznym. Z resztą rozwiązanie zastosowano również we wcześniejszych konstrukcjach. Muszę przyznać, że choć zmiany w tym bloku rdzenia są znacznie większe, niż w przypadku przejścia nVidia z serii FX na serię 6, to innowacji, które nazwałbym rewolucją osobiście nie dostrzegam. Z resztą to nie Vertex jest aktualnie najwęższym gardłem procesu przetwarzania grafiki aktualnych gier.
Silnik pikseli
Najważniejsza z punktu widzenia procesu przetwarzania 3D jest część odpowiedzialna za obliczenia pikseli. Już krótkie spojrzenie na schemat rdzenia może u znawców architektury GPU wywołać pewne zdziwienie. Wcześniej sprawa była klarowna. Klasyczny potok pikseli oparty na przynajmniej jednej jednostce teksturowania (TMU), procesorze Shaderów i ROP (Raster Operation) rozwijano przez dokładanie kolejnych modułów. Pierwsze zakłócenie w tym schemacie pojawiło się wraz z GeForceFX, który wprowadził elementy współdzielone dla potoków. GF6 posuwa się jeszcze dalej przez wyprowadzenie z potoków jednostek ROP i zmniejszanie ich ilości w stosunku do pozostałych modułów przetwarzania pikseli. Oczywiście ideą rozwiązania była z jednej strony oszczędność wielkości rdzenia, a z drugiej lepsze wykorzystanie mniejszej ilości bloków. Jeśli potok zawiera szereg modułów, które sekwencyjnie wykonują operacje to naturalnym jest fakt blokowania przez przetwarzany piksel również tej części jego zasobów, które nie uczestniczą w danym procesie. Prowadzi to do zmniejszenia efektywności działania rdzenia, a jego stopień jest ściśle powiązany z rodzajem wykonywanych operacji na pikselu.
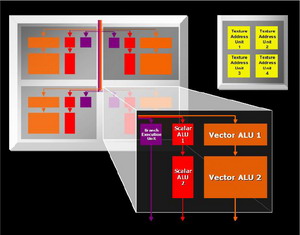
(kliknij, aby powiększyć)
Bardziej spektakularną metodą na wyeliminowanie tego zjawiska jest uniezależnienie od siebie poszczególnych modułów potoku tak, aby każdy z nich po wykonaniu operacji mógł być wykorzystany przez inny piksel. Proces przetwarzania miałby wtedy do dyspozycji zestaw jednostek wykonawczych bez przyporządkowania do konkretnego piksela i wykorzystywał je niezależnie od innych. Takie zarządzenie zasobami wymaga zastosowania dodatkowej jednostki nadrzędnej zajmującej się ich dystrybucją, działającej na zasadzie elektronicznego przełącznika. Oczywiście wprowadzenie nowego modułu, przez który przekazywane są informacje o każdym obliczanym pikselu ma negatywny wpływ na wydajność (opóźnienia synchronizacji) ale uwzględniając różnicę efektywności wykorzystania modułów można spodziewać się konkretnego zysku w całym procesie przetwarzania. Drugą zaletą jest możliwość uzyskania asymetrii w ilości poszczególnych modułów i projektowania rdzenia tak, aby lepiej wykorzystać jego powierzchnię. Układ ATI R520 jest pierwszym na rynku rdzeniem, którym w praktyce próbuje realizować taką wizję architektury. Jednostkę odpowiedzialną za dystrybucję zasobów nazwano Ultra-Threaded Dispatch Processor. Powiązane czwórkami (Quad) procesory shaderów zajmujące się operacjami arytmetycznymi na pikselach odseparowano od TMU i jednostek adresujących tekstury. Proces przetwarzania dzielony jest na wątki (thread) związane z identycznymi obliczeniami stosowanymi do grupy pikseli. Radeon X1800XT jest w stanie przetwarzać jednocześnie 512 takich wątków. Informacje o bieżącym stanie każdego piksela przechowywana jest w dedykowanej pamięci podręcznej.
Zmiany dotyczą nie tylko wzajemnych zależności pomiędzy modułami bloku przetwarzania pikseli, ale dotykają również samych jednostek arytmetycznych shadera. Do czterech ALU znanych z wcześniejszych układów ATI dodano jednostkę odpowiedzialną za przetwarzanie instrukcji sterowania przepływem, a dodatkowo w związku z wymogami SM3.0 zwiększono precyzję obliczeń z 24 na 32 bity (bez możliwości stosowania "częściowej" precyzji 16bitowej, jak w układach nVidia). Jeśli do tego dodamy fakt niezależnej pracy modułów operujących na teksturach to mamy teoretyczną możliwość wykonania do 6 instrukcji na piksel w jednym takcie zegara. Oczywiście wynikowa efektywność działania nowej architektury zależy od wielu czynników i nawet pomijając kwestię optymalnego dostosowania do niej sterowników trudno wyrokować cokolwiek bez praktycznych testów w grach. Na dwie kwestie chciałbym zwrócić dodatkową uwagę. Po pierwsze uniezależnienie modułów przetwarzania i wprowadzenie jednostki do ich dystrybucji wydaje się być konkretnym krokiem w jednym z kierunków wyznaczonych przez Windows Graphic Foundation (następca DirectX), w postaci idei "uniwersalnych" shaderów (brak podziału na jednostki vertex i pixel). Po drugie odseparowanie modułów związanych z teksturowaniem od shaderów praktycznie pozbawiło nowy rdzeń potoków pikseli. Przynajmniej w klasycznym tego słowa znaczeniu. Możemy od biedy napisać, że rdzeń zachowuje się jak 16-stopotokowiec z uwagi na fakt tego, że jednocześnie może przygotować do szesnastu pikseli. Problem w tym, że efektywność może mieć zupełnie inną niż układ z typowymi "długimi" potokami. Jeśli do tego wprowadzić asymetrię ilości modułów (shader vs TMU) to w przypadku kodu obciążającego piksele zaawansowani shaderami sumaryczna wydajność będzie zupełnie z innej (niż szesnastopotokowa) bajki.
|