Nvidia: Ampere, układ GA100, karty A100 i system DGX-A100 zaprezentowane
Autor: Zbyszek | źródło: Nvidia | 17:42
(13)
Nvidia podczas swojej transmisji online o nazwie GTC 2020 (GeForce Technology Conference) zaprezentowała kilka nowości. Wydarzenie było nagrywane i transmitowane z kuchni Jensena Huanga, z jego prywatnego domu. Wstęp został poświęcony na podziekowania wszystkim walczącym z epidemią, a także prezentację tego, jak nauka pomaga w walce z COVID-19. Następnie prezes Nvidia przeszedł do prezentacji nowych technologii i produktów, w trakcie której wyciągał je ze swojej kuchenki. Trzeba przyznać, że cały materiał jest bardzo dobrze przygotowany i świetnie się go odbiera.
To dzięki wzbogaceniu o ciekawe ujęcia spoza kuchni Jensena Huanga, a także liczne bardzo proste i trafne tłumaczenia wielu skomplikowanych zagadnień. Szef Nvidia okazuje się być świetnym dydaktykiem, dzięki czemu nawet osoby mniej techniczne nie powinny mieć problemów z jego zrozumieniem. Widać też, ze wydarzenie kierowane jest do wszystkich internautów, a nie tylko specjalistów jacy zwykle uczestniczyli w stacjonarnych wersjach GeForce Technology Conference.
Przechodząc do konkretów, na początku Jensen Huagn pochwalił się zakupem firmy Mellanox Technology i przedstawił jej kolejnej generacji rozwiązania komunikacyjne VXLAN o szybkości 400 gigabitów na port, przeznaczone dla Data Center. Jak stwierdził, obecnie architektura Data Center ewoluuje tak, aby całe Data Center mogło być traktowane jako jedna jednostka obliczeniowa - podobnie jak obecnie pojedynczy serwer. Mają w tym pomóc także przygotowane przez Nvidia i Mellanox w pełni programowalne i wydajne karty sieciowe Bluefield 2.
Zaprezentowano także nowe biblioteki SDK dla developerów, nowy Framework Merlin dla aplikacji głębokiego uczenia maszynowego, oraz nową wersję Apache Spark 3.0 z akceleracją GPU. W części 5 wystąpienia Jensen Huang omówił najnowsze osiągnięcia z dziedziny sztucznej inteligencji, a także przedstawił korzystającego z tych technologii interaktywnego 3D chatbota o nazwie Misty, z któym uciął sobie ciekawą pogawędkę.
Wreszcie, po dłuższym czasie oczekiwania zaprezentowana została nowa architektura obliczeniowa i graficzna Ampere, posiadająca znaczne zmiany względem dotychczasowej Turing. Główne z nich to dużo większa liczba jednostek, jakie udało się zmieścić dzięki użyciu 7nm procesu litograficznego, usprawnione rdzenie RT oraz zupełnie nowe jednostki Tensor z akceleracją o nazwie Sparsity. Kolejną Nowością jest funkcja MIG (Multi Instance GPU), pozwalająca na jednym układzie graficznym uruchomić wiele równoległych instancji GPU - symulując obecnosć wielu mniejszych układów graficznych.
Zaprezentowano też największy opracowany układ z architekturą Amepre - GA100, zbudowany z 54 miliardów tranzystorów umieszczonych na powierzchni 826 mm². Chip w pełnej wersji zawiera 8192 rdzeni CUDA, 4096 niezależnych od nich rdzeni CUDA podwójnej precyzji, oraz 512 jednostki Tensor. Zostały one podzielone na 128 bloków SM, umieszczonych w 8 grupach GPC. GA100 ma też aż 48MB pamięci podręcznej L2, w porównaniu z 6MB cache L2 w GV100 "Volta", oraz dodatkowo system kompresji CDC (Compute Data Compression) danych w L2, który efektywnie nawet podwaja jej pojemnosć. Układ obsługuje interfejsy PCI-Express 4.0 x16 (64 GB/s) i NVLink (600 GB/s), oraz posiada 6-kanałowy kontroler pamięci HBM2.
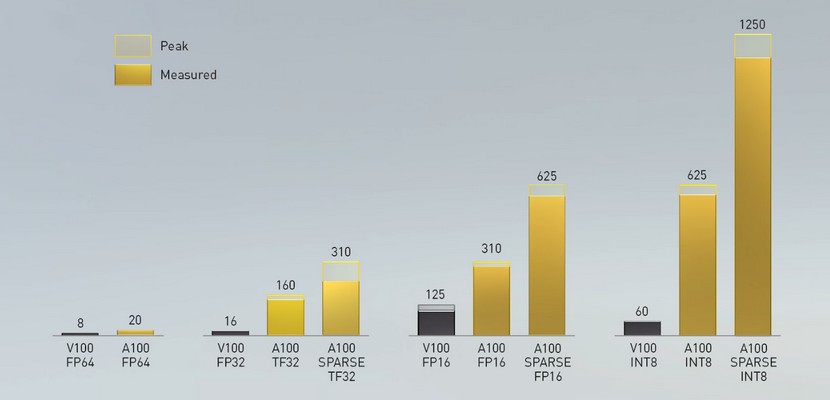
Obecnie produkowany wariant chipu GA100 ma aktywne 6912 rdzeni CUDA, 3456 niezależnych od nich rdzeni CUDA podwójnej precyzji, 432 jednostki Tensor, oraz aktywne 5 z 6 kanałów kontrolera pamięci HBM 2. Taka wersja chipu GA100 jest podstawą karty obliczeniowej Tesla A100, na której jest on zainstalowany wraz z 40GB pamięci HBM2 o łącznej przepustowości ponad 1600 GB/s. Porównanie jej wydajności do wcześniejszej karty Tesla V100 z układem GV100 z serii Volta wygląda wręcz poniżająco dla dotychczasowej karty - w zadaniach obliczeniowych nowa Tesla A100 okazuje się dwukrotnie szybsza w typowych obliczeniach, i od dwóch do dwudziestu razy szybsza w obliczeniach Tensor, AI i uczenia maszynowego.
Kolejna nowość to system obliczeniowy DGX-A100, złożony z 8 kart Tesla A100, dwóch 64-rdzeniowych procesorów AMD EPYC Rome, oraz technologii sieciowych Mellanox. DGX-A100 jest już dostępny w sprzedaży w cenie 199 000 USD za sztukę.
Poza nim, architektura Ampere i zbudowane dzięki niej chipy graficzne/obliczeniowe będą podstawą systemów EGX A100 dla akceleracji robotyki, oraz AGX A100 dla pojazdów autonomicznych.
Ponizej zamieszczono kilka zrzutów ekranu i najciekawsze części GTC 2020 online
K O M E N T A R Z E
2x AMD Epyc 7742 (autor: Conan Barbarian | data: 14/05/20 | godz.: 18:50) 2x AMD Epyc 7742
To tak jakby NVIDIA z liścia strzeliła Intelowi dwa razy.
Teraz tylko patrzeć jak Apple zrobi podobnie.
To jest przykre patrzeć jak Intel będzie tracił kasę bo zaspał. (autor: Mario1978 | data: 14/05/20 | godz.: 18:59) W przyszłym roku nawet nie będzie sensu Nvidia łączyć architekturę Hopper z Xeon 10nm bo AMD będzie miało Epyc 3 sporo lepszy.
Intel teraz co najwyżej swoje CPU będzie łączył z własnym GPU bo nikt inny tego nie będzie chciał po za Amerykańskimi instytucjami wspierającymi Intela.
Jak tak dalej pójdzie to Intel poczuje się w skórze AMD z przed lat.
Trzeba przyznac ze te duze... (autor: gantrithor | data: 14/05/20 | godz.: 20:06) chipy nvidi sa dosc imponujace 826 mm² to niezly kawal krzemu.
@up (autor: Conan Barbarian | data: 14/05/20 | godz.: 20:13) Trzeba też przyznać, że TSMC musi mieć naprawdę dopracowane te 7nm, skoro takie monstrum jest możliwe w produkcji.
Nvidia konsekwentnie prze do przodu (autor: Zbyszek.J | data: 14/05/20 | godz.: 21:52) i z trójki Intel, AMD, Nvidia, raczej Nvidia rozwija się najstabilniej. Niezanotowana takich wtop, jakie zdarzały się Intelowi, czy zwłaszcza AMD
1997-2002, rozprawienie się z 3DFx, potem udane GeForce 1, 2, 3, 4
2003 - pierwsza wtopa, seria FX 5800, gdzie do walki z Radeon 9700 (256-bit DDR) posłano FXa ze 128-bitową magistralą, wyżyłowano go na maksa dając kiepskie i głośne chłodzenia. Ale naprawiono to pół roku później w serii FX 5900, a kolejne pół roku później był już GeForce 6800, i mimo, że w tym samym 130nm procesie, to znacznie bardziej wydajny.
2004-2005 - udane GeForce 6, 7
2006- GeForce 8 który pozamiatał wtedy ATI i swojego poprzednika. Nadal w procesie 90nm jak GeForce 7800 i Radeon X1900 XT, ale 2 razy bardziej wydajny od nich.
2008-2011 - to słabszy okres. Problemy z laptopowymi GPU (awarie) oraz niezbyt udane karty GTX 280/285 (Tesla) i GTX 480/580 (Fermi) - pierwsze karty do zadań obliczeniowych, ale dla graczy i ogólnie to średnio udane. Niby bardziej wydajne od bezpośrednich poprzedników i kilkanaście % od Radeonów 4870, 4890, 5970, 6970, ale bez rewelacji. Wielkie rdzenie krzemowe, wysokie TDP i temperatury. Wydajność tych kart rosła znacznie wolniej niż przyrost liczby ich tranzystorów.
2012-2017 - Kepler, Maxwell, Pascal - bardzo udane produkty, w których wyciągnięto wnioski z błędów serii Tesla i Fermi, oraz mocno postawiono na optymalizację, wydajność na wat i na powierzchnię krzemową. Poprawiono IPC jednostek, efektywność energetyczną, dodano zaawansowaną kompresję danych przesyłanych do GDDR, poprawiając efektywną przepustowość. W efekcie GTX 1080 to niezły mistrz wydajności na wat i wydajności na powierzchnię GPU.
2018-2020 - Turing, Ampere - tutaj korzystając z wypracowanej przewagi w postaci mocno zoptymalizowanej wydajność energetycznej, następuje znaczna rozbudowa funkcjonalności.
Jednocześnie poza grafikami, Nvidia po początkowym okresie 2005-2010 przekształcenia GPU z układu graficznego, do graficzno-obliczeniowego, mocno inwestuje w:
- wykorzystanie GPU do obliczeń i zastosowań różnych typów, znacznie powiększając sobie rynek zbytu na swoje układy
- w chipy z architekturą ARM
- w rozwiązania z dziedziny obliczeń polegających na uczeniu maszynowym i sztucznej inteligencji
- w ostatnim czasie w rozwiązania sieciowe i DataCenter do tworzenia superkomputerów i wydajnej integracji komponentów w DataCenter (CPU + GPU + DPU - data processing unit rozdzielający mega szybkimi interfejsami dane pomiędzy serwerami w DataCenter)
Sumaryczne jedna większa wtopa (FX5800), ale krótka, słabszy okres z GTX 280/285 (Tesla) i GTX 480/580 (Fermi), kiedy te rdzenie były bardzo nieefektywne energetycznie. Pozatym to jednak dość dużo trafionych decyzji i w miarę widoczna stała ścieżka rozwoju. Może brak jednej decyzji: robili swoje rdzenie ARM do dziwnych produktów jak Nvidia Shield, ale zabrakło decyzji o ich produkcji do smartfonów (konkurencja z Qualcomm).
Intel z o wiele większym potencjałem i kasą, jednak miał więcej wpadek i konkretnych (Pentium 4, 10nm). Nvidia od 2011-2012 sama sobie narzuciła wysokie tempo, a Intel siadł na laurach chcąc w nieskończoność serwować 4 rdzenie lepsze o 5% od poprzednich sprzed roku. Następnie okazało się, że jego dział projektowania litografii też siadł na laurach po udanych wdrożeń 32nm, 22nm i 14nm.
O AMD już nie wspominając, bo żeby osiągać poziom wpadki AMD z Bulldozerem to nowa generacja GPU Nvidia, wykonana w nowszym procesie litograficznym, musiałby być nie lepsza od poprzedniej, przy większym zużyciu energii. A takie coś nawet w serii FX się Nvidia nie zdarzyło. W dodatku Bulldozer był ponad 5 lat, a GeForce FX tylko rok.
Nvidia w tej chwili pracuje dla dobra USA bo konkurencja nie śpi. (autor: Mario1978 | data: 14/05/20 | godz.: 23:30) Huawei też ma swoje akceleratory i nie potrzebuje do tego czystego GPU - https://e.huawei.com/...ting-dc/atlas/atlas-900-ai
A to jest stara generacja oparta na Kungpeng 910.
Bardzo mnie ciekawi czy Nvidia porzuci rynek dla graczy a wszystko się wyjaśni po premierze RDNA2x.
@ up (autor: Zbyszek.J | data: 14/05/20 | godz.: 23:40) jakby planowali porzucić rynek GPU dla graczy to by nie zaczynali z RTX. Oni chcą raczej ten rynek utrzymać, stąd właśnie RTX, żeby wybór samodzielnej grafiki miał duży sens - bo IPG jeszcze długo RTX nie pociągnie.
@Zbyszek (autor: Conan Barbarian | data: 14/05/20 | godz.: 23:41) Z tym Pentium 4 to masz na myśli oczywiście tylko grzejnik Prescott w 90nm, gdyż poprzednik w 130nm o imieniu Northwood był znakomity.
@ up (autor: Zbyszek.J | data: 14/05/20 | godz.: 23:57) z tym Pentium 4 to mam na myśli całokształt - beznadziejne Wiliamette, pierwsze Northwoody też przeciętne, no i potem Prescott. Nothwood był dobry ale tylko ten z końca produkcji, z wysokim taktowaniem, HT, i magistralą FSB 800 MHz + dual DDR. Na łącznie 5 lat Pentium 4, dobre było może 1,5-2 lata. A Prescott można porównać do Bulldozera - tak jak Bulldozer wykonany w nowszym procesie litograficznym, a przy tym nie lepszy od poprzednika i zużywający więcej energii. Tyle, że Prescott był dwa lata a po nim było Core 2 Duo. Bulldozer był 5 lat, a po nim był mniej rewelacyjny Ryzen 1xxx
kokretna karta (autor: Shark20 | data: 15/05/20 | godz.: 22:16) liczyłem, że Ampere to będzie Turing z lepszym RT, i raczej nic więcej. Że będą mniejsze rdzenie, a tutaj znów poszli na całość i jest dużo usprawnień i 2,5 razy więcej tranzystorów niż w GV100. Nieźle.
Ciekawe, czy wersje dla graczy będą jakoś przycięte żeby rdzenie były mniejsze i wydajność na wat wyższa. Np - mniej rdzeni Tensor lub rdzenie Tensor poprzedniej generacji z Turinga + brak zbędnych funkcji jak Multi Instance GPU.
osobiscie (autor: pawel1207 | data: 16/05/20 | godz.: 16:27) to bym sie cieszyl jakby nv wizela sie za cpu zgodne z risc V albo open isa :D w koncumoz zobaczylibysmy z czasem jakis postep ..
@ pawel1207 (autor: Shark20 | data: 16/05/20 | godz.: 23:02) oni powinni się wziąć już 10 lat temu za CPU ARM do smartfonów
D O D A J K O M E N T A R Z
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.

")