AMD ZEN 2 : szczegóły nowej architektury
Autor: Zbyszek | Data: 14/06/19
|
  Podczas targów E3 w Las Vegas firma AMD oficjalnie zaprezentowała nową architekturę ZEN 2 oraz oparte o nią procesory AMD Ryzen 3. generacji (seria 3000). Nowe procesory produkowane są w 7nm procesie litograficznym, zawierają od 6 do 12 rdzeni i pojawią się w sklepach 7 lipca tego roku, a dwa miesiące później dołączy do nich flagowy 16 rdzeniowy Ryzen 9 3950X. Nowa architektura ZEN 2 zawiera sporo ulepszeń względem dotychczasowych architektur ZEN i ZEN+, które mają skutkować o 15 procent wyższą wydajnością jednowątkową przy takim samym taktowaniu zegara. W niniejszym artykule omówimy je szczegółowo. Zapraszamy. Podczas targów E3 w Las Vegas firma AMD oficjalnie zaprezentowała nową architekturę ZEN 2 oraz oparte o nią procesory AMD Ryzen 3. generacji (seria 3000). Nowe procesory produkowane są w 7nm procesie litograficznym, zawierają od 6 do 12 rdzeni i pojawią się w sklepach 7 lipca tego roku, a dwa miesiące później dołączy do nich flagowy 16 rdzeniowy Ryzen 9 3950X. Nowa architektura ZEN 2 zawiera sporo ulepszeń względem dotychczasowych architektur ZEN i ZEN+, które mają skutkować o 15 procent wyższą wydajnością jednowątkową przy takim samym taktowaniu zegara. W niniejszym artykule omówimy je szczegółowo. Zapraszamy. | |
|
Litografia i budowa fizyczna
Pod względem budowy fizycznej procesory z architekturą ZEN 2 różnią się zasadniczo od dotychczasowych układów opartych o architektury ZEN i ZEN+. Pojedynczy chip krzemowy, zawierający po dwa moduły CCX z czterema rdzeniami i pamięcią L3, kontroler pamięci DDR4 oraz inne kontrolery I/O (PCI-Express, USB 3.0 i Infinity Fabric), w nowych procesorach został podzielony na dwie części. Moduły CCX wraz z pamięcią L3 stanowią teraz odrębny rdzeń krzemowy (tzw. chiplet), a kontroler pamięci i wszystkie pozostałe kontrolery wchodzące w skład procesora zostały wydzielone do odrębnego rdzenia krzemowego, tzw. chipletu I/O. Układy krzemowe łączone są ze sobą przez magistralę Infinity Fabric drugiej generacji, o dwukrotnie większej przepustowości.
Takie rozwiązanie ma kilka zalet, poczynając od tego, że układ I/O i chiplety z rdzeniami x86 mogą być produkowane w odrębnych procesach litograficznych, a kończąc na tym, że pojedyncze chipy z modułami CCX, okrojone od całej otoczki, mają teraz niewielką powierzchnię - co skutkuje wysokim uzyskiem przy ich produkcji. Dodatkową zaletą takiego rozwiązania jest możliwość stosowania większej lub mniejszej liczby chipletów w zależności od ilości rdzeni jaką posiada cały procesor. Zmniejsza to koszt budowy tańszych procesorów (zastosowanie tylko jednego chipletu), jak również zmniejsza koszty projektowe - nie jest konieczne opracowanie dwóch różnych rdzeni krzemowych, z większą lub mniejszą liczbą modułów CCX.


Procesory Ryzen serii 3000, które trafią do sklepów 7 lipca, składają się z jednego rdzenia krzemowego I/O produkowanego w 12nm procesie litograficznym przez GlobalFoundries, oraz jednego lub dwóch chipletów wykonanych w 7nm procesie litograficznym przez TSMC.
Pojedynczy 7nm chiplet ma powierzchnię całkowitą 74mm2, i zawiera dwa czterordzeniowe moduły CCX. Daje to łącznie 8 rdzeni z obsługą wielowątkowości (SMT), 32 MB pamięci podręcznej L3 oraz po 512 kB pamięci podręcznej L2 na rdzeń.
Powierzchnia modułu CCX z 4 rdzeniami ZEN 2 i 16 MB pamięci podręcznej L3 wynosi 31.3 mm2. Dla porównania moduł CCX dotychczasowych 14 nm / 12nm procesorów AMD, zawierający 8 rdzeni ZEN / ZEN + i 8 MB pamięci podręcznej miał powierzchnię 60mm2, zatem nowy 7nm moduł CCX jest o prawie połowę mniejszy.
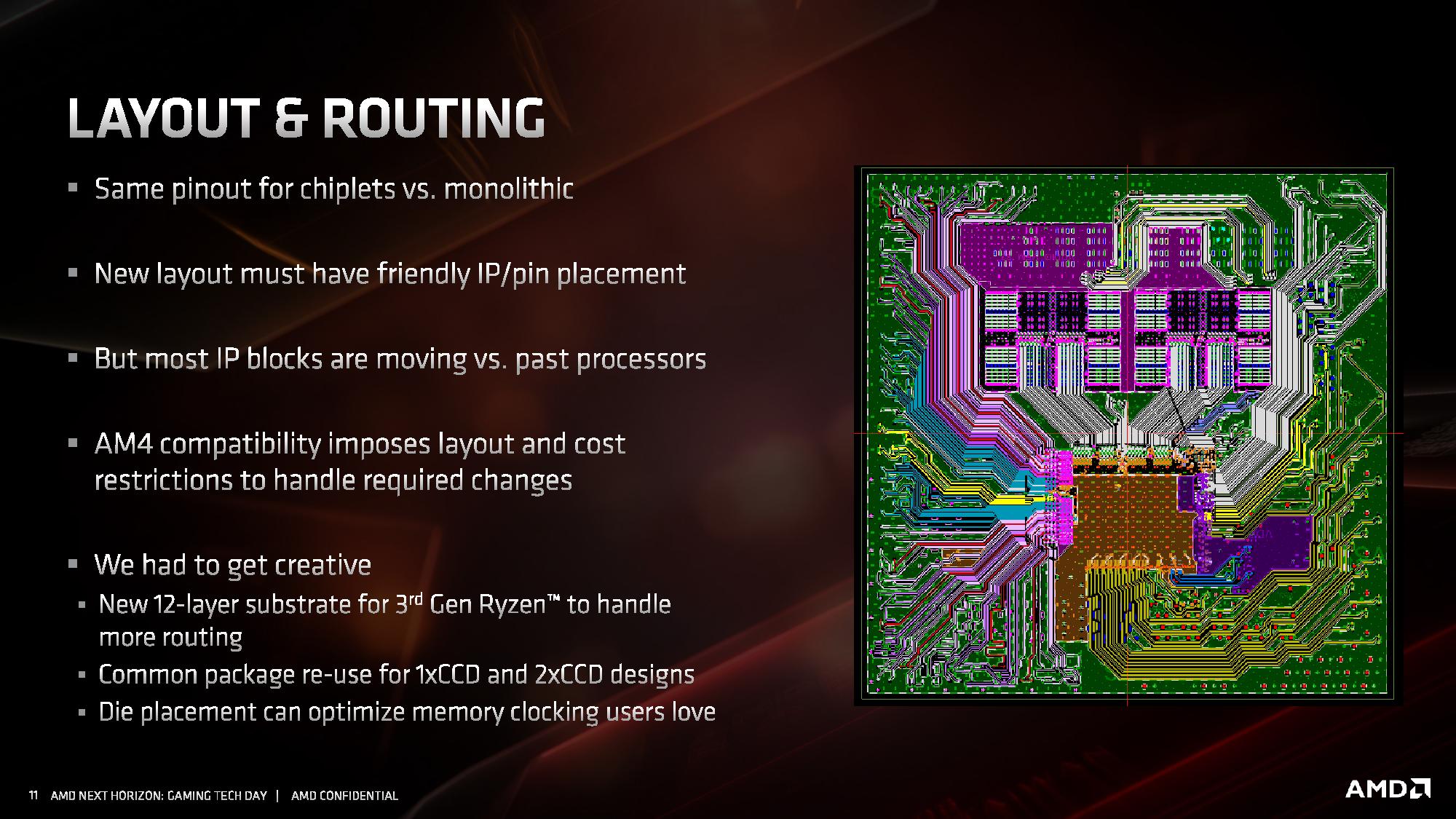
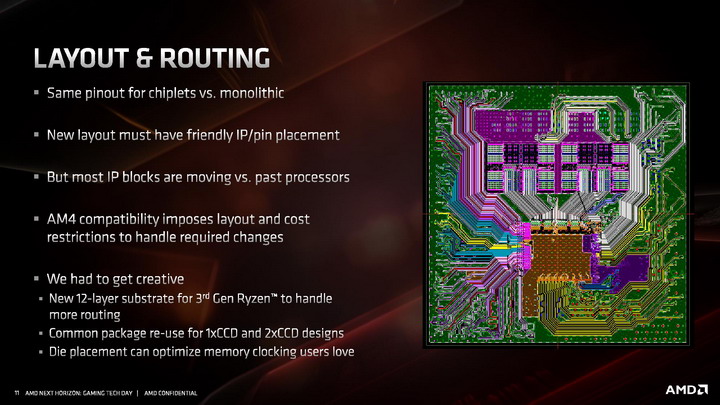
AMD włożyło także sporo pracy projektowej w powstanie nowego substratu, czyli płytki na której montowane są chiplety i rdzenie I/O. Wyzwaniem było zmniejszenie odległości pomiędzy "wypustkami" na których montowane są rdzenie krzemowe ze 150 mikronów do 130 mikronów. Według AMD, nowy substrat jest na tyle zaawansowany, że mogą produkować go jedynie dwie firmy na świecie.

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
Architektura X86
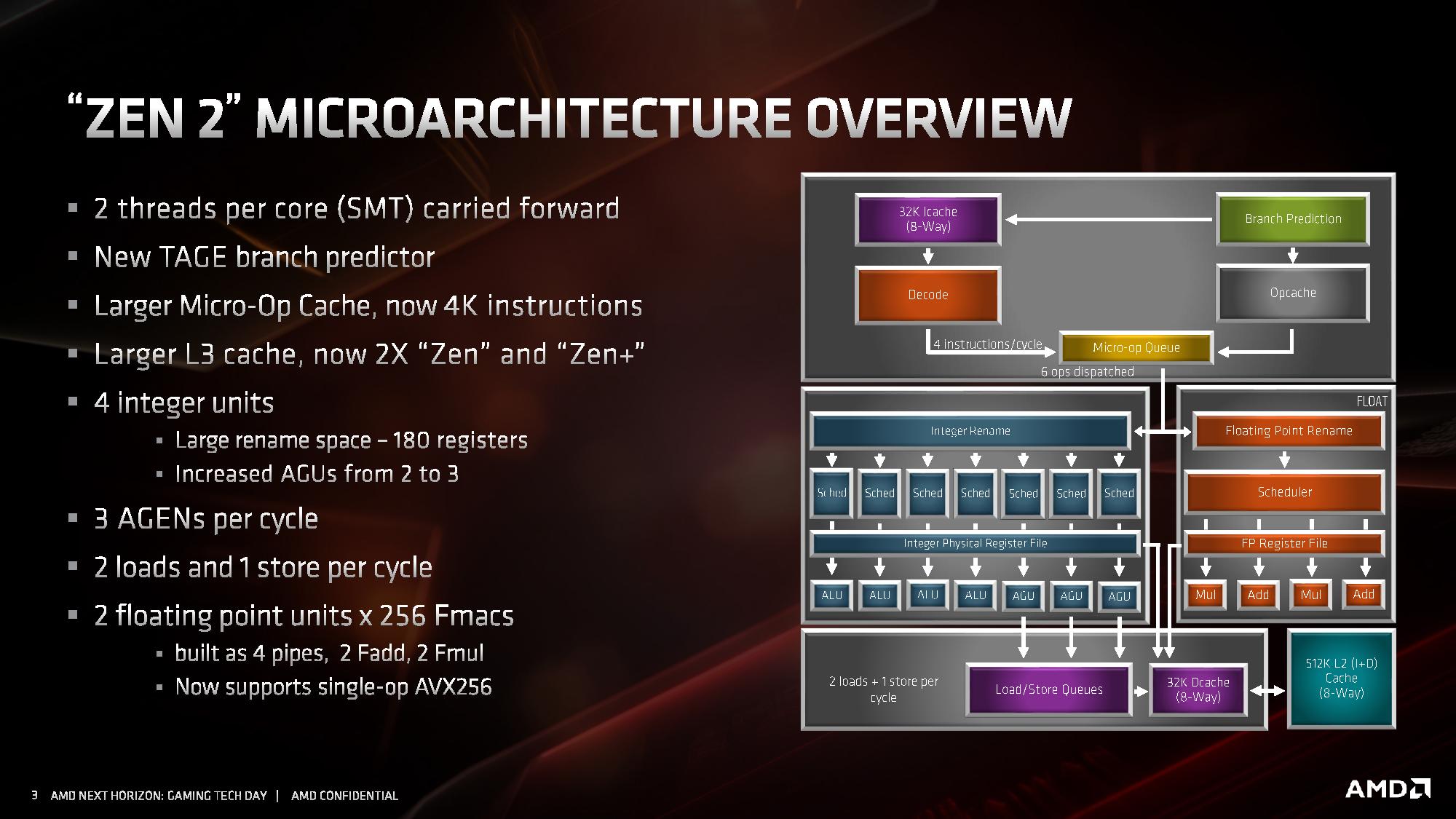
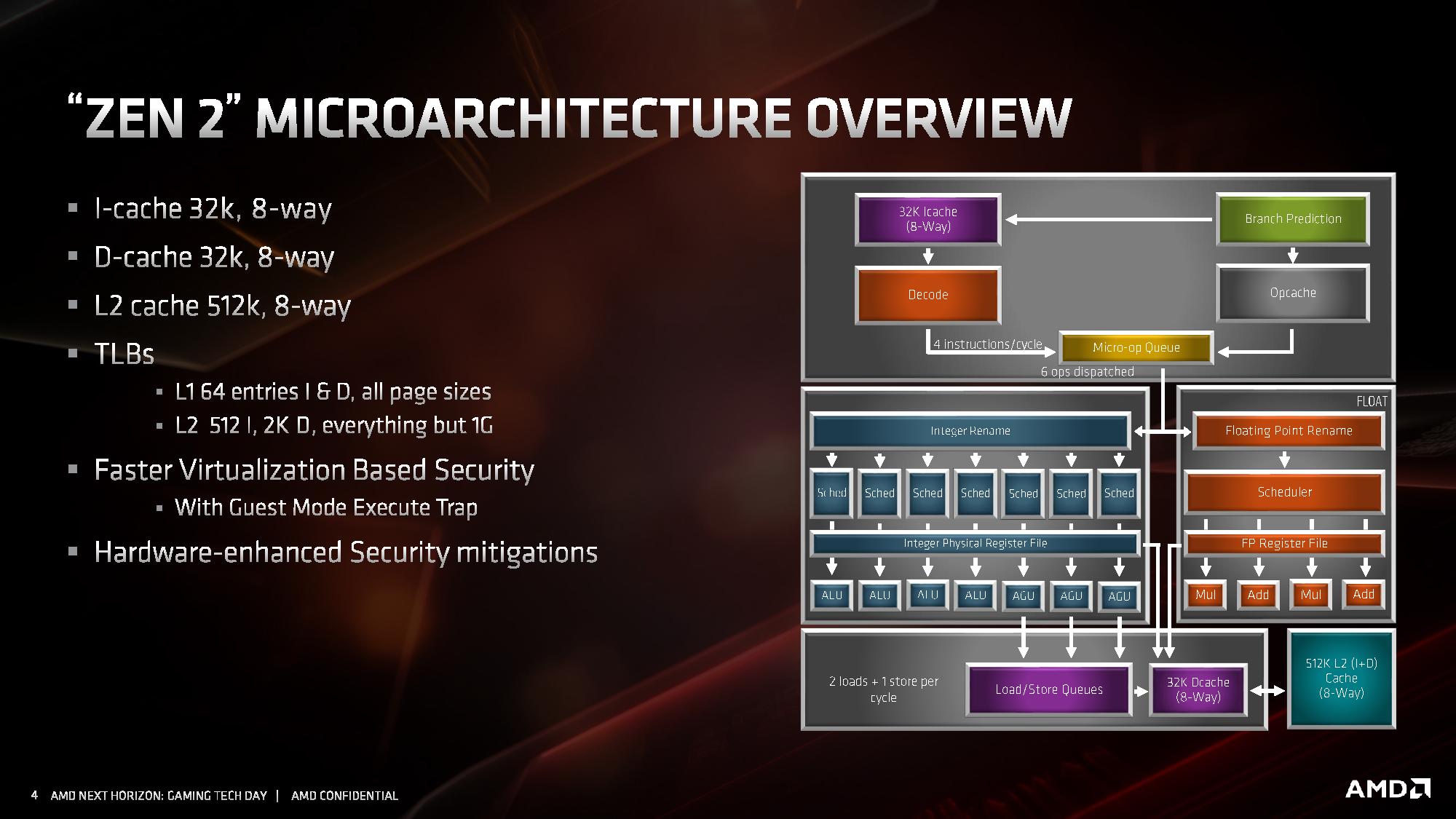
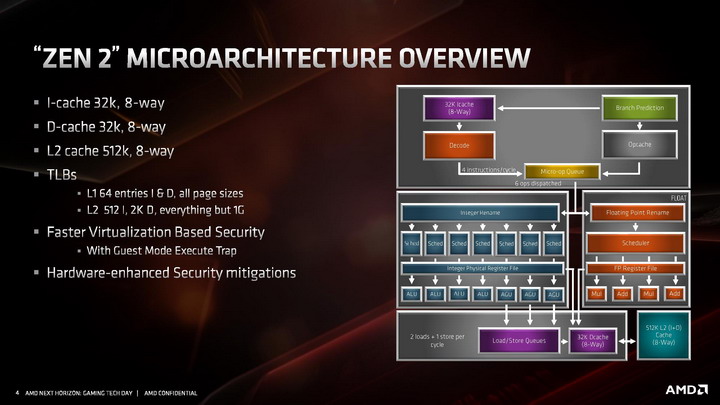
Przechodząc do bardziej ciekawych szczegółów, zaglądamy wgłąb modułu CCX, analizując budowę pojedynczego rdzenia z architekturą ZEN 2. Architektura ZEN 2, względem dotychczasowej ZEN / ZEN+, wprowadza usprawnioną część stałoprzecinkową i znacznie rozbudową jednostkę zmiennoprzecinkową. Towarzyszy temu znacznie usprawniony Front End, czyli część zasilająca potoki i jednostki wykonawcze w instrukcje.

(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
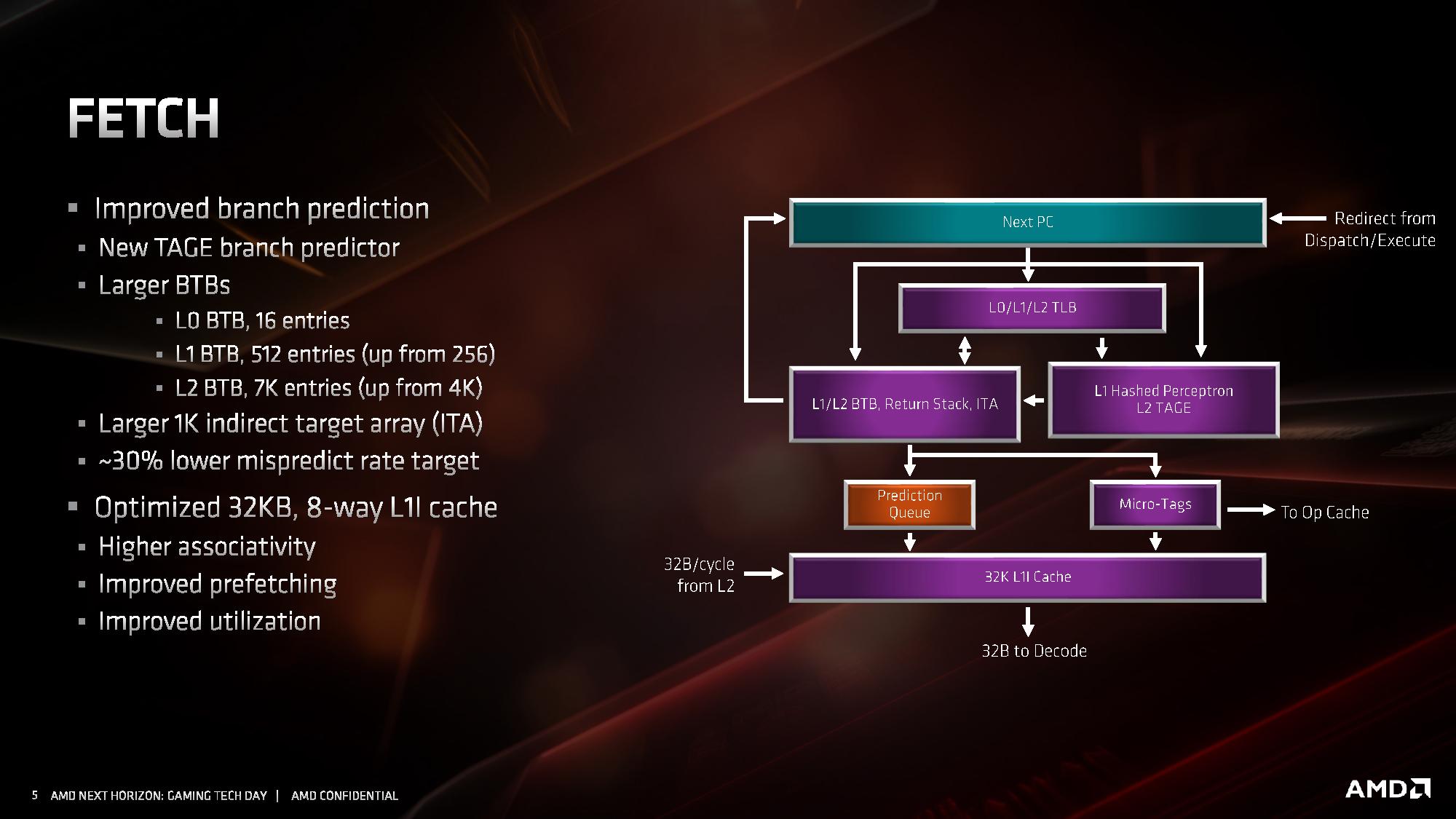
Front-End
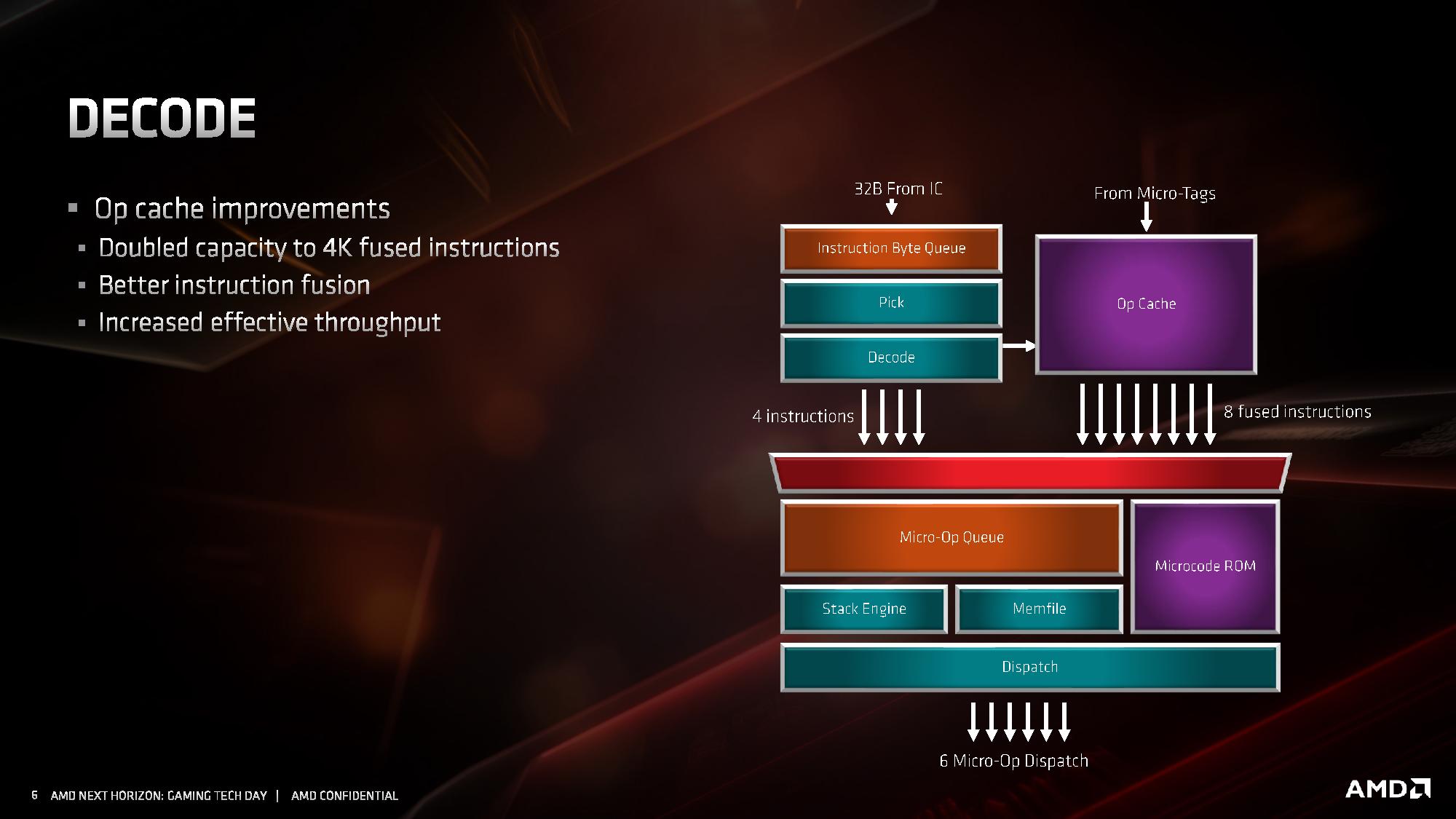
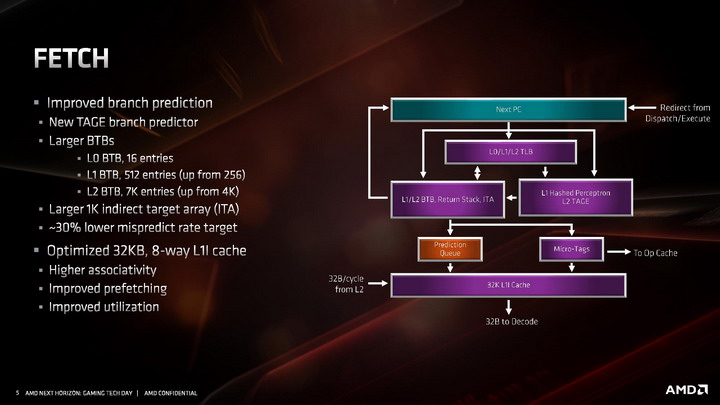
W części odpowiadającej za wczytywanie instrukcji, udoskonalono system przewidywania rozgałęzień. Usprawniono algorytmy odpowiadające za przewidywanie skoków, a także znacznie powiększono bufory predykcyjne rozgałęzień (BTB) dla instrukcji z pamięci L1 i L2. Pojawiła się także nowa dodatkowa logika przewidująca rozgałęzienia w innych sposób, nazywana TAGE branch predictor, bazująca w większym stopniu na analizie tego, czy poprzednio zachowanie instrukcji zostało przewidziane prawidłowo, czy nie, a następnie tagowaniu skutecznych przewidywań. Sumarycznie wszystkie zmiany wpłynęły na około 30 procentowy spadek liczby nietrafionych predykcji.
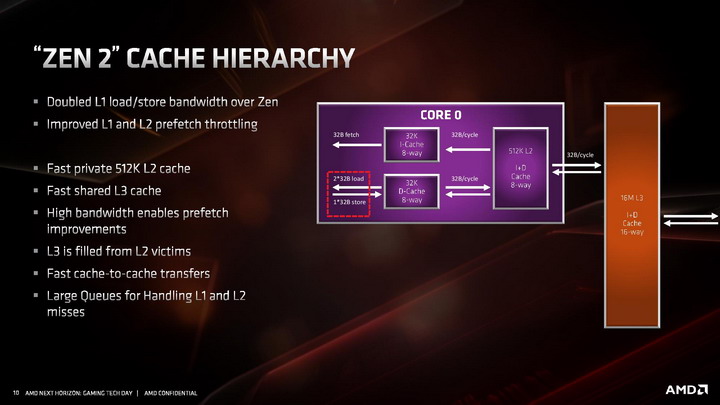
Przebudowana została pamięć podręczna 1. poziomu dla instrukcji, która ma teraz pojemność 32 KB, o połowię mniejszą niż w pierwszej generacji architektury ZEN, ale jej budowa została zmieniona z 4-kanałowej na 8-kanałową, przez co pamięć jest sprawniejsza, ma wyższą przepustowość i efektywniej wykorzystuje swoją pojemność . Uzyskane w ten sposób tranzystory pozwoliły natomiast dwukrotnie powiększyć pamięć podręczną L0, przechowującą zdekodowane mikroinstrukcje. W architekturze ZEN 2 mieści ona 4096 ostatnich instrukcji przetworzonych przez dekoder rozkazów, zamiast 2048 jak w architekturach ZEN / ZEN+. Dla porównania analogiczna pamięć w architekturze Skylake mieści 1536 instrukcji, a w architekturze Sunny Cove mieści 2560 instrukcji.
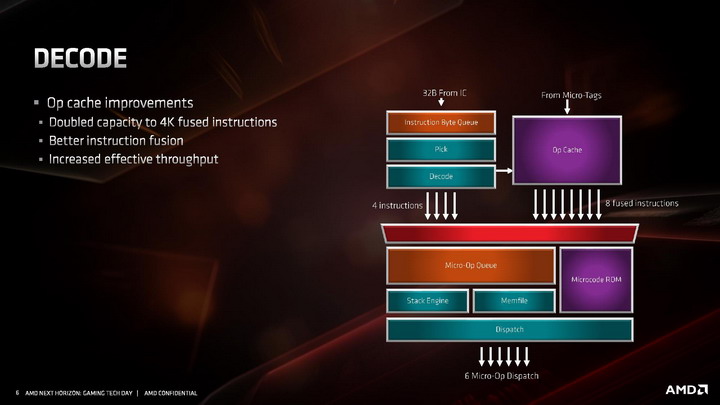
Kolejne z modyfikacji poczynionych w architekturze ZEN 2 objęły dekoder rozkazów, czyli jednostki konwertujące archaiczne instrukcje x86 w mikro-instrukcje wewnętrzne procesora. Dekoder rozkazów w ZEN 2 nadal jest 4-drożny, ale poczyniono modyfikacje zwiększające jego przepustowość oraz usprawniono funkcję odpowiadające za fuzję instrukcji, czyli łączenie ich w paczki i wspólne dekodowanie w jednym dekoderze. Nowy algorytm jest w stanie połączyć do 8 instrukcji x86 w jedną. Kolejna modyfikacja dotyczy instrukcji AVX2, które są teraz przetwarzane w jednym takcie zegara przez jedną jednostkę dekodującą, bez potrzeby rozdzielania ich na dwie odrębne 128-bitowe instrukcje - co zmniejsza zajętość pozostałych trzech dekoderów.
Zmodyfikowany dekoder rozkazów czerpie też korzyści z dwukrotnie powiększonej pamięci podręcznej L0, przechowującej zdekodowane mikro-instrukcje. Jej większa pojemność sprawia, że już raz przetworzone instrukcje rzadziej muszą być dekodowane ponownie, co pozwala dekoderowi zająć się innymi rozkazami i dostarczyć więcej instrukcji do potoków wykonawczych procesora.
Część stałoprzecinkowa i zmiennoprzecinkowa
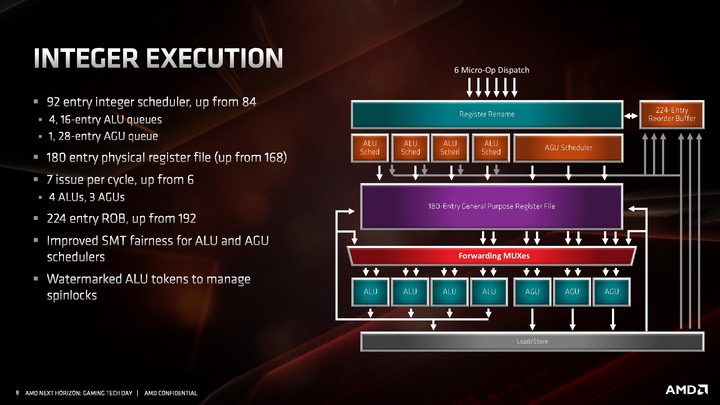
W części stałoprzecinkowej AMD zdecydowało się zwiększyć liczbę potoków wykonawczych z 6 do 7, dodając dodatkowy potok z jednostką AGU. Sumarycznie architektura ZEN 2 zawiera więc 4 jednostki ALU i 3 jednostki AGU. To oczywiście nie wszystkie ze zmian. Reorder buffer, czyli bufor odpowiadający za przekolejkowanie instrukcji przed ich wykonaniem został powiększony z 192 do 224 pozycji. Usprawniono także Scheduler, odpowiadający za przydzielanie jednostkom wykonawczym instrukcji do wykonania. Jednostki ALU posiadają teraz 16 wejściowe Schedulery, zamiast 14-wejściowych, a jednostki AGU otrzymały jeden zunifikowany 28-wejściowy Scheduler. Powiększono także zestaw fizycznych rejestrów, aby zmniejszyć ryzyko potencjalnego wstrzymywania wykonywania operacji z powodu tymczasowego braku wolnego rejestru.
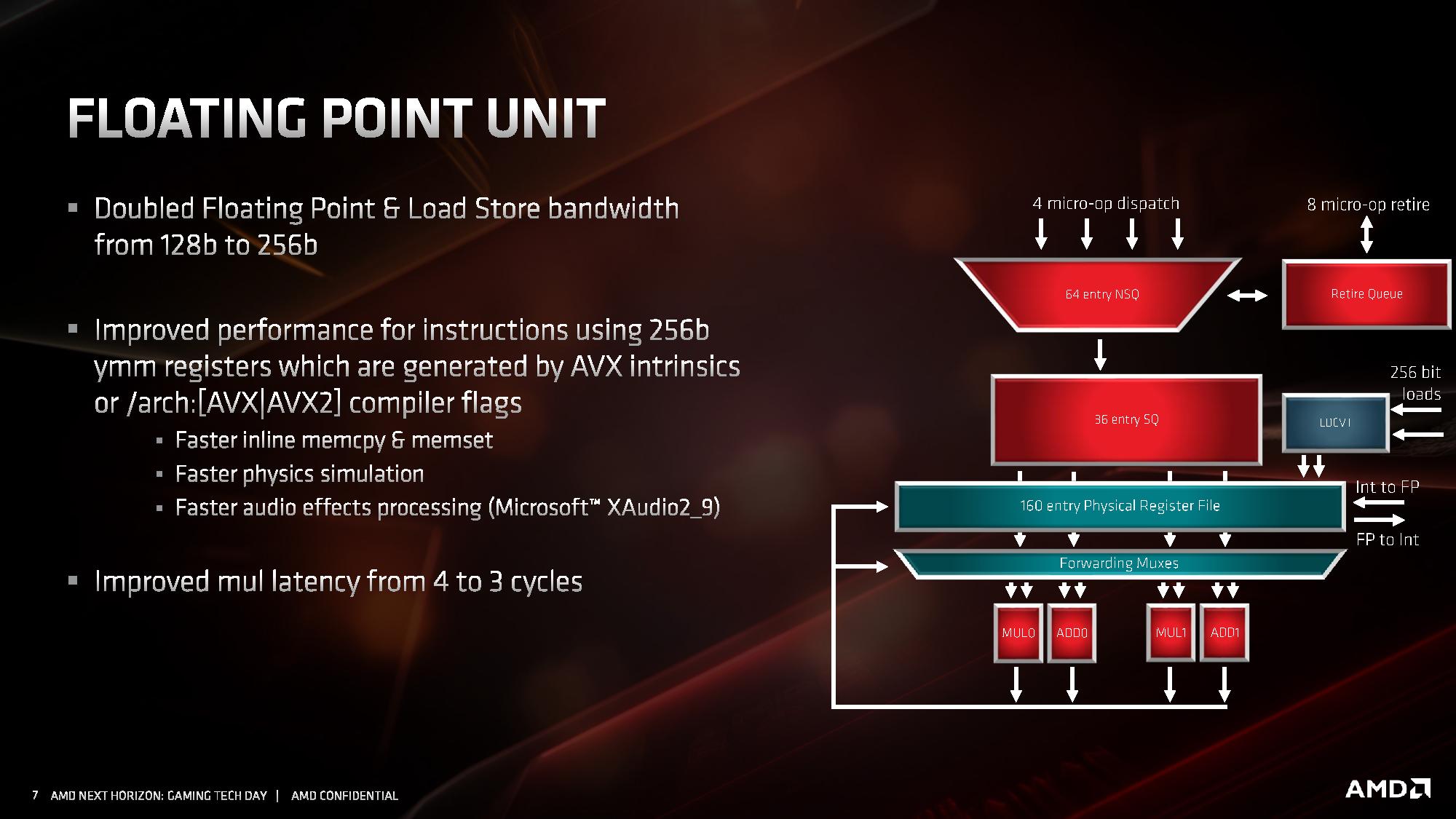
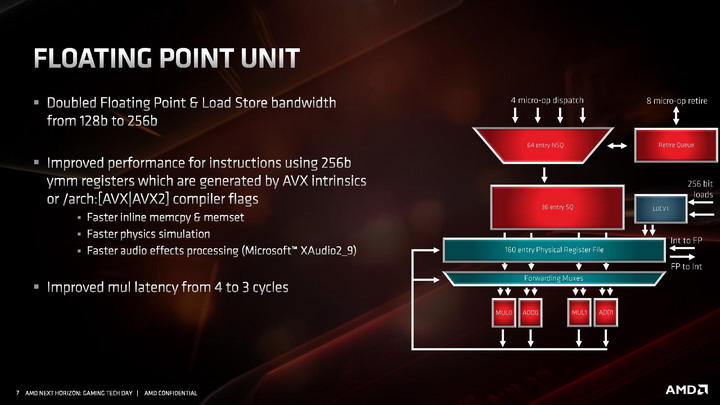
Jednostka zmiennoprzecinkowa w architekturze ZEN 2 zachowała czteropotokową budowę, ale każda z czterech dostępnych jednostek wykonawczych jest teraz natywnie 256-bitowa, co pozwala na obsługę instrukcji AVX2 bez potrzeby dzielenia ich na dwie 128-bitowe instrukcje. Skutuje to oczywiście dwukrotnym wzrostem wydajności zmiennoprzecinkowej podczas pracy z 256-bitowymi instrukcjami. Ale to nie wszystko. Oprócz tego przyspieszono wykonywanie operacji mnożenia, której wykonanie zajmuje teraz 3 cykle zegara zamiast 4 cykli. Usprawnienie to ma dać wyższą wydajność zmiennoprzecinkową niezależnie od tego, czy procesor pracuje z instrukcjami AVX2, czy też starszymi rozkazami AVX i SSE.
Część odpowiadająca za ładowanie i odbieranie danych
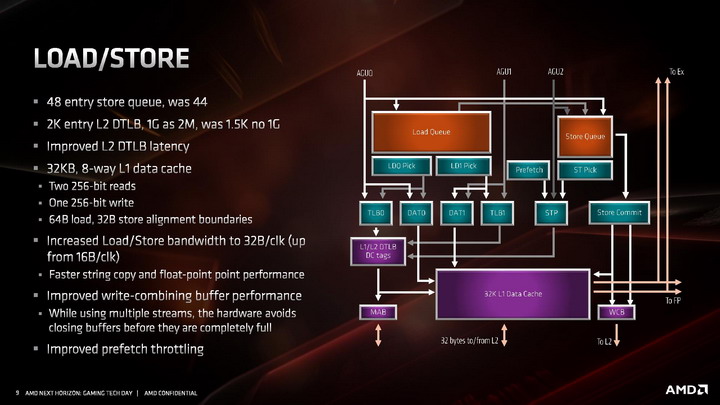
Kolejne z ulepszeń objęły część architektury odpowiadającą za ładowanie i odbieranie danych do wykonujących na nich instrukcje jednostek wykonawczych. Zmiany wprowadzone w tej części objęły dwukrotny wzrost przepustowości, wymagany do tego, aby 256-bitowe jednostki zmiennoprzecinkowe mogły zostać obsłużone danymi. W architekturze ZEN 2 część load / store jest w stanie obsłużyć natywnie 32 bajty danych, zamiast 16 bajtów jak dotychczas.
Poza tym wprowadzono także szereg drobnych ulepszeń skutkujących wzrostem wydajności ładowania i zapisu danych w każdym scenariuszu, nie tylko gdy wykonywane są instrukcje AVX 2. W tym celu dwukrotnie zwiększono przepustowość pamięci podręcznej L1 dla danych, powiększono kolejkę zapisu z 44 do 48 pozycji, ulepszono mechanizm TLB dla pamięci L2, powiększono wydajność buforów oraz zmniejszono ich opóźnienia, zmniejszając ryzyko tzw. throttlingu, czyli sytuacji, w której dane na których mają operować instrukcje nie zostaną dostarczone do jednostek wykonawczych na czas.
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
Infinity Fabric drugiej generacji i PCI-Express 4.0
Nowa magistrala Infinity Fabric drugiej generacji ma nawet czterokrotnie zwiększoną przepustowość, która została uzyskana poprzez wzrost częstotliwości taktowania i dwukrotnie powiększenie szerokości magistrali. Nowa wersja Infinity Fabric jest w stanie przesłać 512 bitów w jednym takcie zegara, zamiast 256 bitów jak jej pierwsza wersja. Jednocześnie wzrósł zegar taktujący.
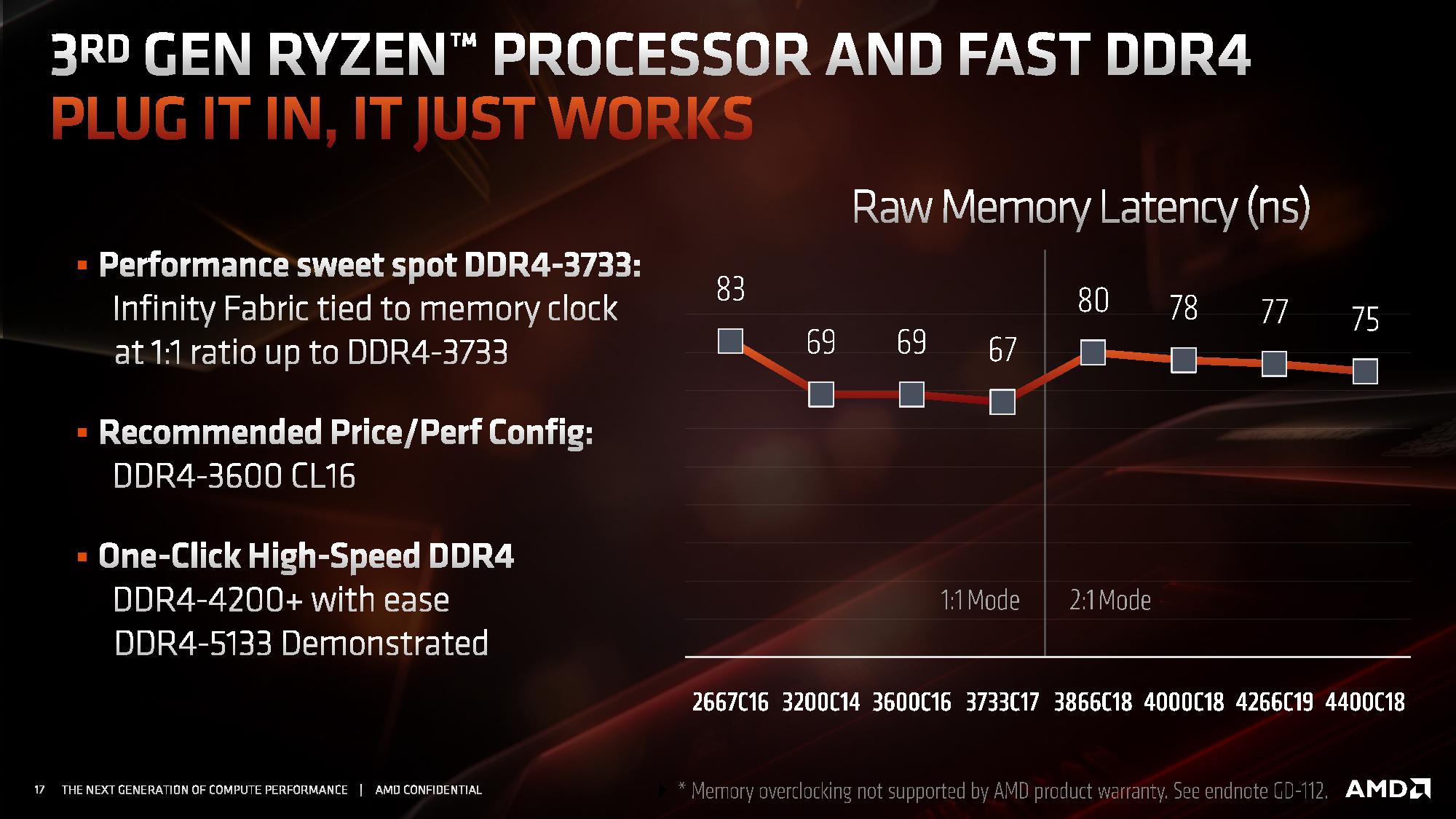
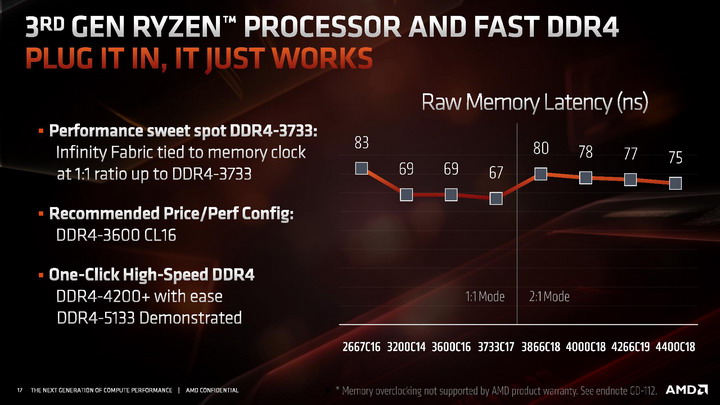
Standardowe taktowanie magistrali Infinity Fabric w nowej generacji procesorów Ryzen jest równe efektywnemu taktowaniu pamięci DRAM, czyli dwukrotnie większe aniżeli w pierwszej i drugiej generacji tych CPU, w których wynosiło połowę efektywnego taktowania pamięci DDR4. Wprowadzono jednak dodatkowy dzielnik pozwalający zmniejszyć taktowanie Infinity Fabric 2 do połowy efektywnego taktowania pamięci DDR4, czyli do wartości takiej jak w 1. i 2. generacji procesorów Ryzen. Jego użycie ma pozwalać na uzyskiwanie bardzo wysokich częstotliwości pracy pamięci RAM.
Według AMD, przy standardowym dzielniku 1:1 możliwe jest korzystanie z pamięci DDR4-3600 lub DDR4-3733. Przestawienie dzielnika na 2:1, czyli do scenariusza, w którym tak jak w poprzednich procesorach magistrala Infinity Fabric pracuje z połową efektywnej częstotliwości pamięci RAM, pozwala na uzyskiwanie ekstremalnie wysokich częstotliwości taktowania DDR4 - wynoszących około 5000 MHz.
Dwukrotnie szersza magistrala, wyższe częstotliwości taktowania i standardowo dwukrotnie wyższe taktowanie niż w poprzedniej generacji, to nie jedyne zmiany wprowadzane przez Infinity Fabric 2. Zastosowano też szereg modyfikacji zwiększających efektywność energetyczną magistrali - zdaniem AMD transfer jednego bitu pochłania teraz o 27 procent mniej energii elektrycznej.
AMD rekomenduje pozostawienie dzielnika 1:1 dla częstotliwości RAM wynoszących do około 3800 MHz, a powyżej tej wartości należy przełączyć Infinity Fabric 2 w tryb pracy z połową efektywnej częstotliwości taktowania pamięci DDR4.
Architektura ZEN 2 to także pierwsze procesory na rynku zgodne z magistralą PCI-Express 4.0 Nowa wersja PCI-E posiada podwójną przepustowość względem PCI-E 3.0, co ma przełożyć się na możliwość zastosowania znacznie szybszych nośników SSD. Dodatkowo z PCI-Express 4.0 zgodne są najnowsze Radeony oparte o architekturę Navi, dzięki czemu wymiana danych z procesorem i GPU będzie przebiegać bardzo szybko.

(kliknij, aby powiększyć)
źródło: Anandtech.com

źródło: Anandtech.com

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)
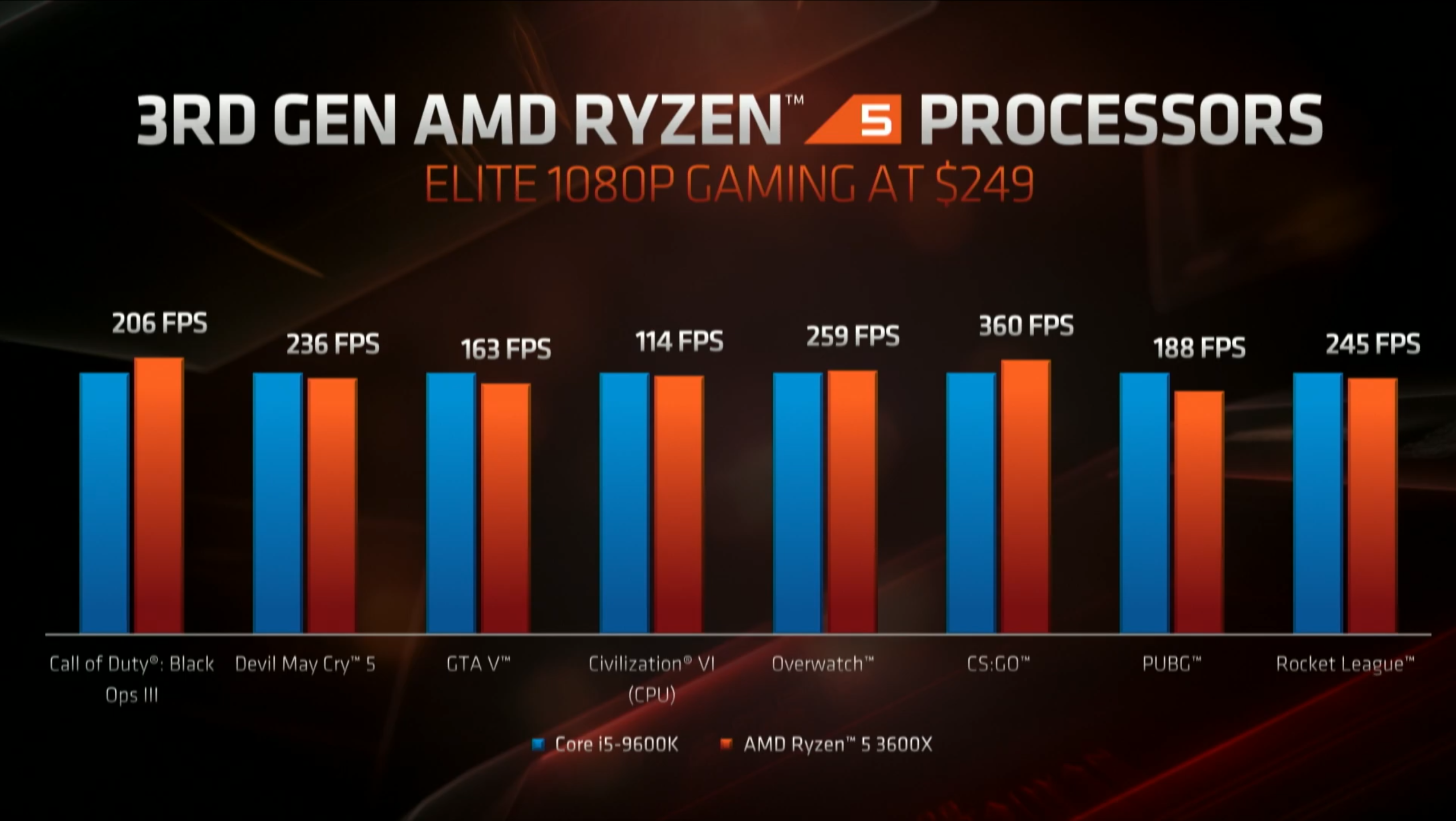
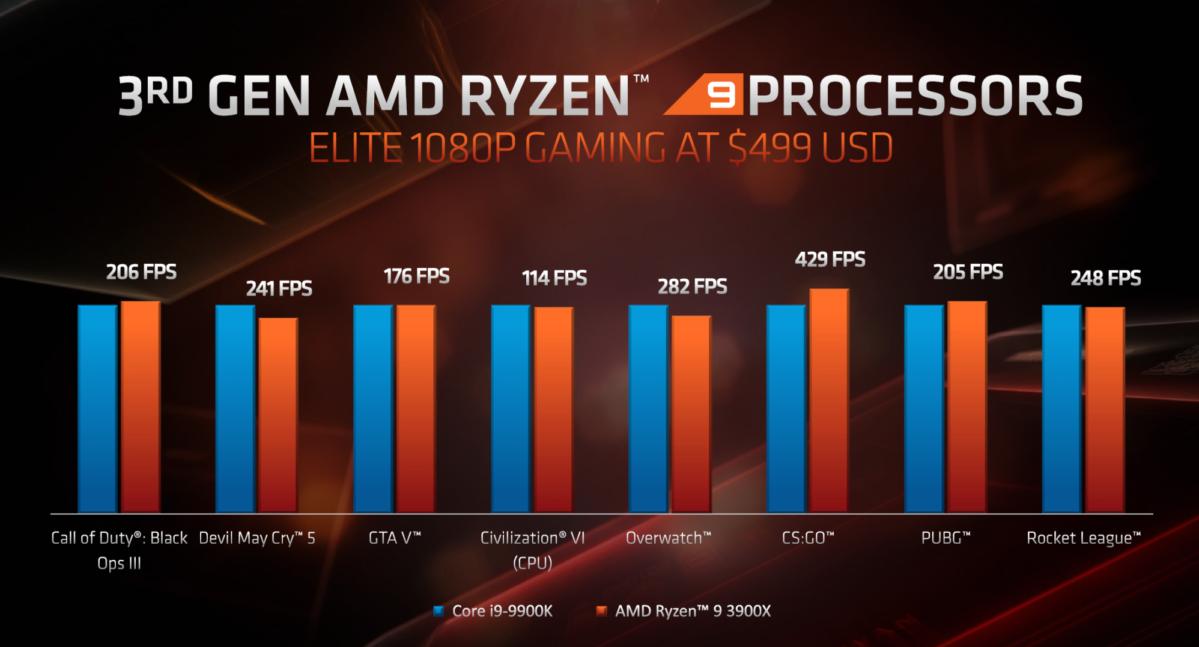
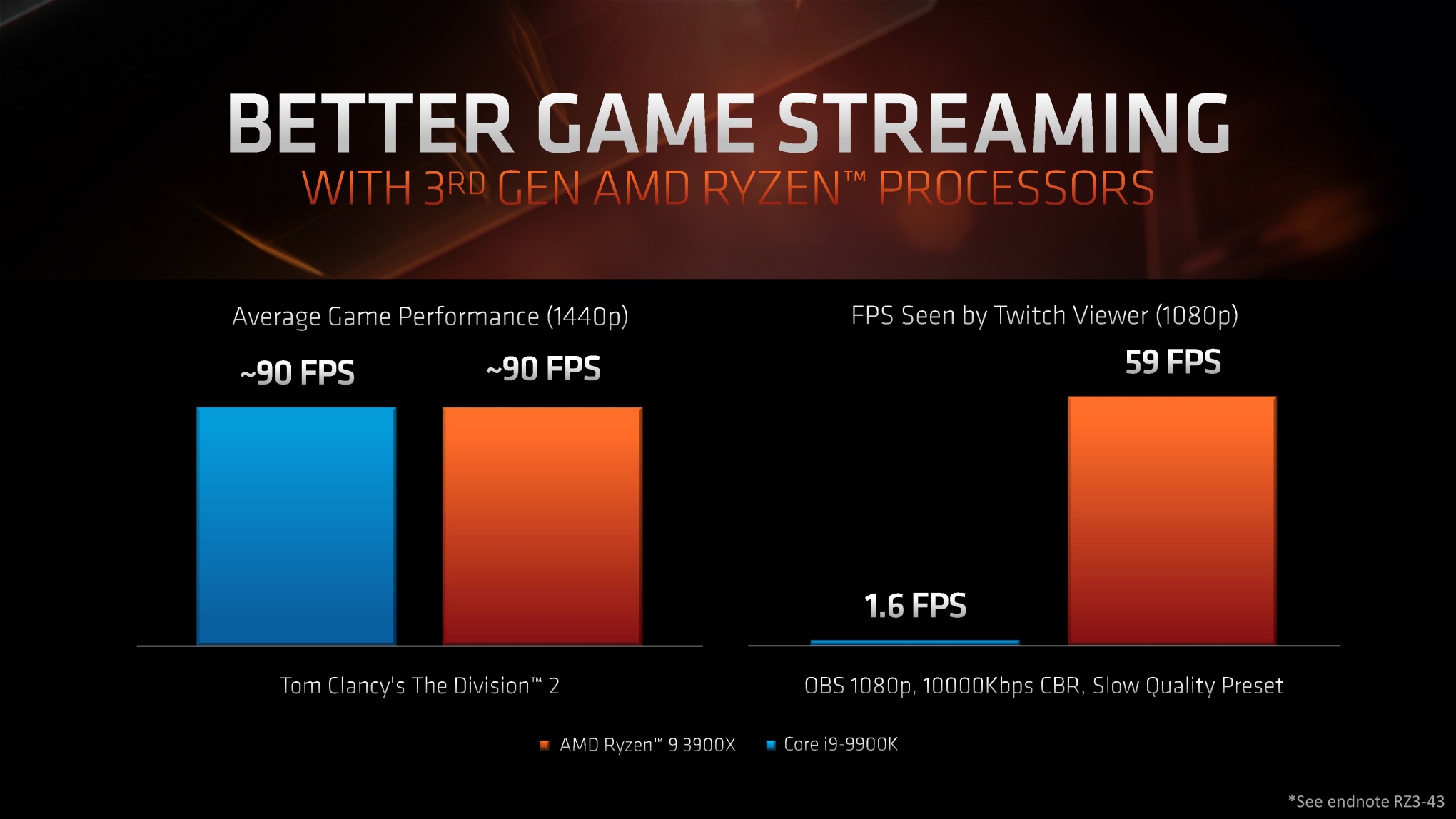
Wydajność w grach, pamięć L3
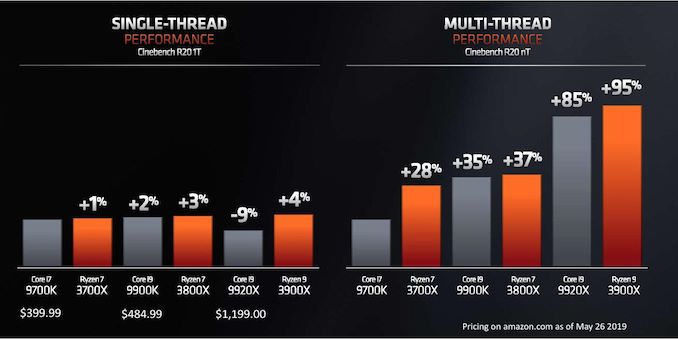
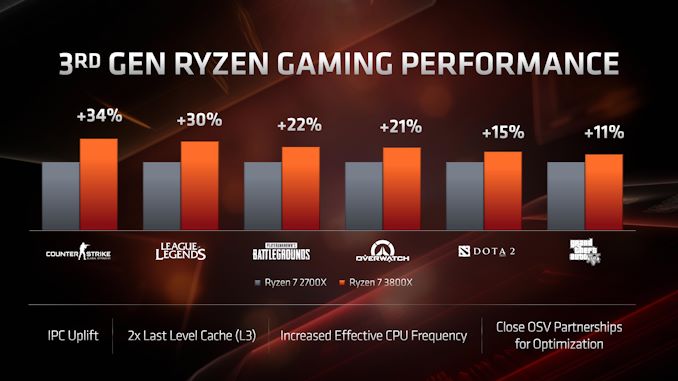
Zdaniem AMD, architektura ZEN2 i procesory Ryzen 3. generacji ma oferować porównywalną lub wyższą wydajność w grach 3D w stosunku do procesorów Intela. Ma być to efektem nie tylko o 15 procent wyższej wydajności jednowątkowej, ale innych ulepszeń takich jak dwukrotnie powiększona pamięć podręczna L3, znacznie usprawniona jednostka zmiennoprzecinkowa oraz magistrala Infinity Fabric 2 i lepsza obsługa pamięci DDR4.
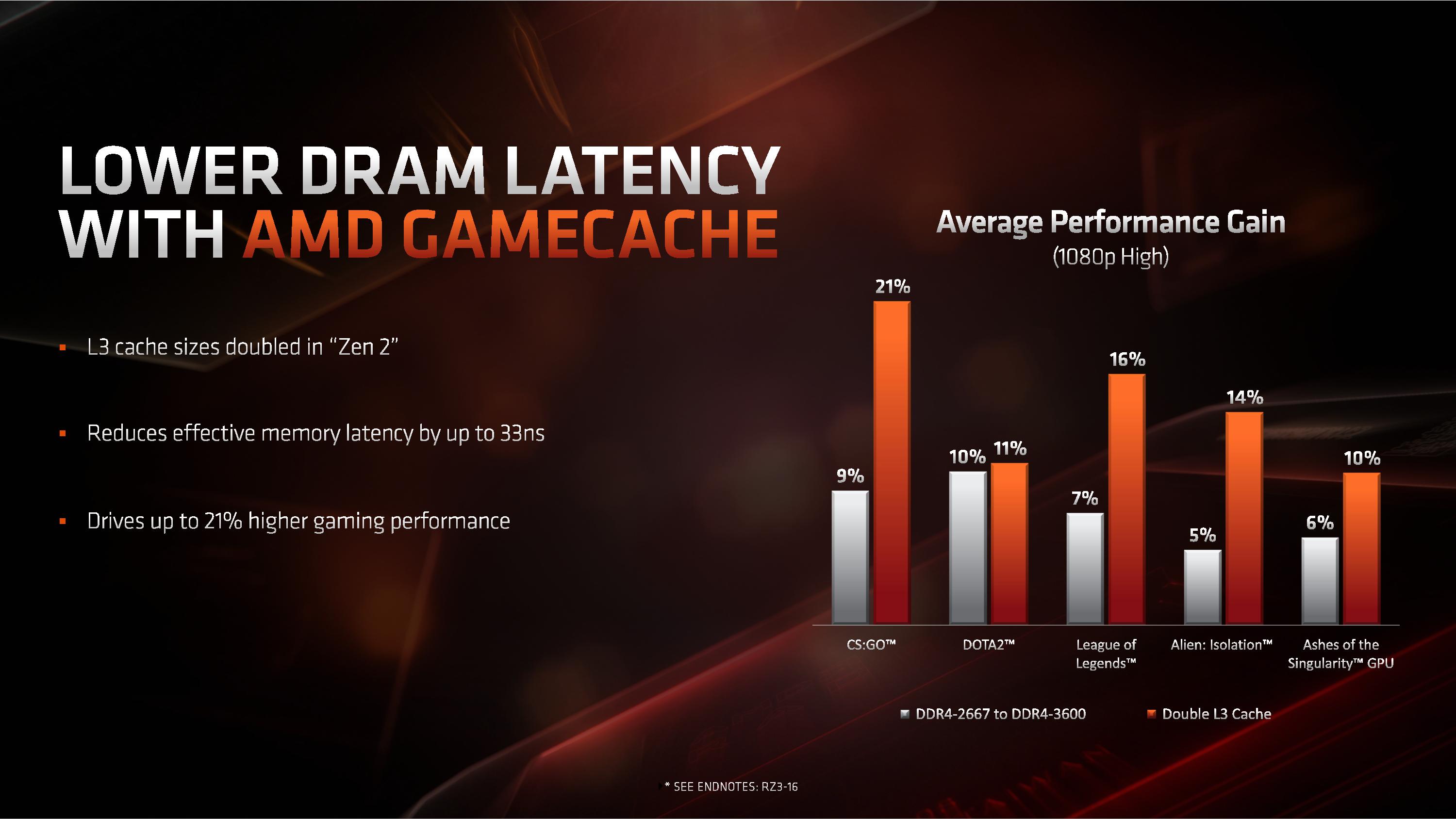
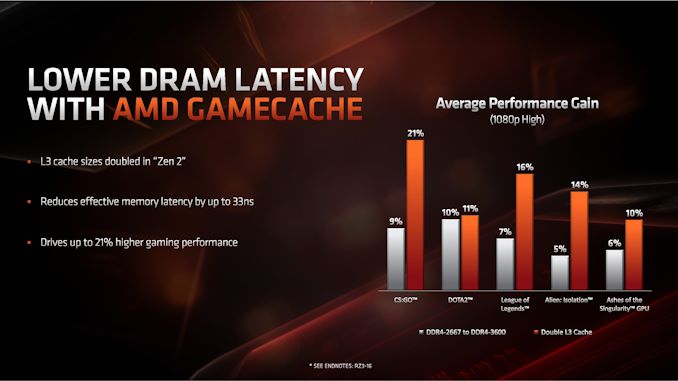
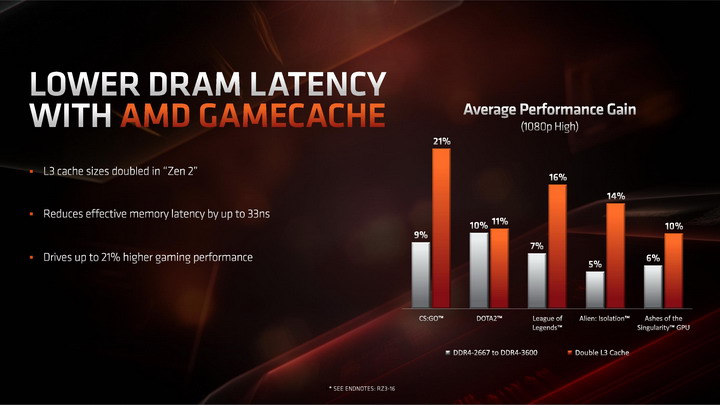
Pamięć podręczna L3 o podwojonej pojemności zyskała swoją marketingową nazwę GameCache. Według wewnętrznych testów AMD, jej zastosowanie skraca czas dostępu do pamięci RAM nawet o 33ns, i wpływa na wzrost ilości generowanych FPS przeciętnie o 10 do 20 procent. W efekcie tej modyfikacji procesory Ryzen 3. generacji mają wyeliminować największą wadę dotychczasowych Ryzenów, jaką była odbiegająca od CPU Intela wydajność w grach 3D.
Warto dodać, że tak naprawdę dwukrotne powiększenie pojemności pamięci L3 oznacza trzykrotny wzrost jej efektywnej pojemności. Dlaczego? Pamięć podręczna trzeciego poziomu przechowuje kopię pamięci L2 rdzeni z modułu CCX, czyli 4 x 512 KB. Oznacza to, że w architekturach ZEN i ZEN+ spośród 8MB pamięci L3 połowa zajęta była na kopie pamięci L2, a faktycznie rolę pamięci podręcznej spełniało pozostałe 4MB pamięci L3. W architekturze ZEN 2, pamięć podręczna L3 ma pojemność 16 MB, i aż 12 MB, czyli trzykrotnie więcej może zostać wykorzystane do przyspieszenia komunikacji z pamięcią RAM.
W nowej architekturze wprowadzono też trzy nowe instrukcje zwiększające kontrole nad pracą pamięci podręcznych, oraz przyspieszono transfery danych pomiędzy pamięciami kolejnych poziomów.
(kliknij, aby powiększyć)

(kliknij, aby powiększyć)
(kliknij, aby powiększyć)
Poniżej można zapoznać się z deklarowaną przez AMD wydajnością nowych procesorów w grach 3D na tle konkurencyjnych CPU Intela.
źródło: Anandtech.com
źródło: Anandtech.com

(kliknij, aby powiększyć)
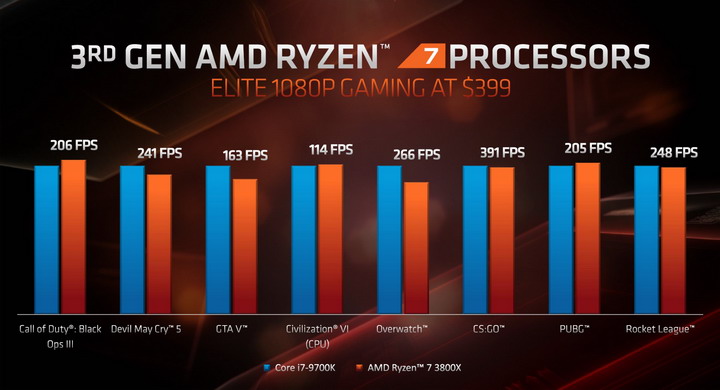
(kliknij, aby powiększyć)
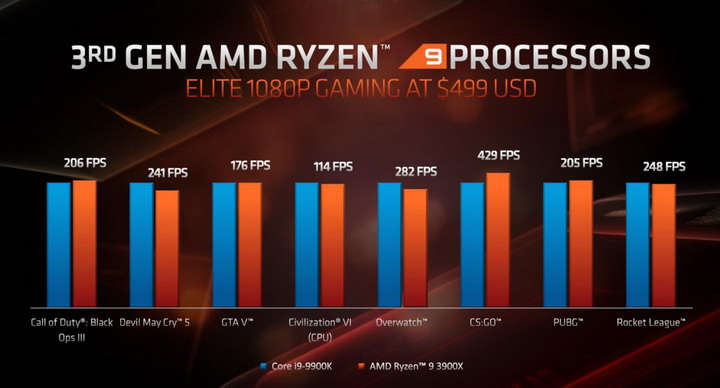
(kliknij, aby powiększyć)
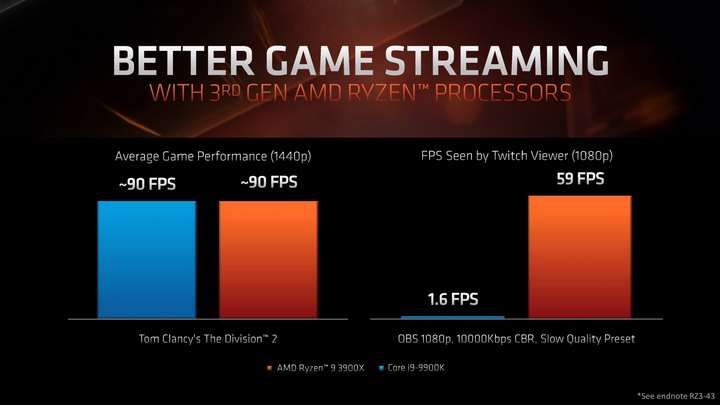
(kliknij, aby powiększyć)
Optymalizacje Windows, poprawki bezpieczeństwa
Wraz z procesorami opartymi o architekturę ZEN 2 firma AMD wprowadza optymalizacje dla systemu Windows 10, nowy mechanizm wybudzania rdzeni z uśpienia oraz sprzętowe poprawki dla niektórych luk bezpieczeństwa dotyczących architektur ZEN i ZEN+.
Optymalizacje dla systemu Windows 10 opracowane wspólnie przez AMD i Microsoft dotyczą mechanizmu przydzielania wątków do rdzeni, i zostały zaszyte w ostatniej aktualizacji Windows 10 2019 May Update. Wprowadzone ulepszenie polega na tym, aby wątek potrzebujący obsłużenia był alokowany do już aktywnego modułu CCX. Dzięki temu zostanie szybciej obsłużony (brak konieczności wybudzania innego modułu CCX ze stanu uśpienia). Dodatkowo, jeśli okaże się, że aktualny scenariusz użycia komputera jest typowo jednowątkowy, to w efekcie braku wybudzenia innego modułu CCX, ten moduł CCX to którego przydzielono wątek będzie taktowany wyższym zegarem, niż w przypadku, gdyby dwa wątki zostały rozlokowane do dwóch odrębnych modułów CCX. Mniejsze będą także opóźnienia, ponieważ odpadnie konieczność komunikacji pomiędzy modułami CCX.
Druga ze zmian jest bardziej sprzętowa i została zaszyta w samych procesorach z architekturą ZEN 2. Nowość nazwa się CPPC2 (Collaborative Power Performance Control 2) i pozwala na skrócenie czasu potrzebnego na wzrost częstotliwości taktowania rdzeni w module CCX z około 30ms do 1-2 ms. Modyfikacja wymaga jednak zgodnej wersji UEFI BIOS, oraz obsłużenia po stronie systemu operacyjnego - która także została dodana do Windows 10 w wersji 2019 May Update. Uzyskana przez AMD wartość 1-2 milisekundy wystarczającej na wybudzenie rdzeni z uśpienia jest doprawdy imponująca. Dla porównania Intel posiada podobne rozwiązanie o nazwie Speed Shift, które zadebiutowało w procesorach Skylake skracając czas rozpędzenia rdzeni do wysokich częstotliwości taktowania z około 100ms do 30ms. Następnie w Kaby Lake czas ten skrócono z 30ms do 15ms. To obecnie około 10-krotnie wolniej aniżeli potrafią procesory z architekturą ZEN2.
Zdaniem AMD, nowość zwiększa zauważalnie responsywność komputera oraz czas ładowania gier i aplikacji. W teście PCMark10 app launch użycie CPPC2 daje według AMD o 6 procent lepszy wynik.
Kolejna z nowości w architekturze ZEN2 to wprowadzenie sprzętowych zabezpieczeń uniemożliwiających wykorzystanie luk, na które podatne były architektury ZEN i ZEN+. Chodzi tutaj o dwie z kilku wersji ataku Spectre. W architekturze ZEN 2 dodano sprzętowych nadzorców, którzy we współpracy z systemem operacyjnym kontrolują przepływ danych, w efekcie czego użycie tych luk nie jest możliwe. Na pozostałe wersje ataków takie jak m.in. Meltdown, Foreshadow, Lazy FPU, Spoiler i ataki MDS, procesory z architekturą ZEN2 są odporne tak samo, jak starsze CPU z architekturą ZEN / ZEN+.

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)

(kliknij, aby powiększyć)
Nowe procesory: Ryzen 9 3950X, Ryzen 9 3900X, Ryzen 7 3800X, Ryzen 7 3700X i Ryzen 5 3600X
Podsumowując, zmiany wprowadzone w architekturze ZEN 2 i nowych procesorach są dość duzą ewolucją pierwszych procesorów Ryzen wprowadzonych na rynek dwa lata temu. Znacznie usprawniona architektura x86 zapewniająca 15 procent wyższą wydajność jednowątkową, dwukrotnie powiększona jednostka zmiennoprzecinkowa i pamięć podręczna L3 oraz obsługa PCI-Express 4.0 i magistrala Infinity Fabric drugiej generacji to znaczące nowości. Nowe procesory to także pierwsze użycie 7nm procesu litograficznego w procesorach przeznaczonych na rynek konsumencki. Przygotowano także optymalizacje dla Windows oraz sprzętowe poprawki zabezpieczeń na te luki, które dotyczyły pierwszej architektury ZEN.
Sumarycznie do sprzedaży trafi sześć modeli nowych procesorów, wyposażonych w od 6 do 16 rdzeni i zgodnych z podstawką AM4. Będą to modele Ryzen 9 3900X (12 rdzeni), Ryzen 7 3800X i Ryzen 7 3700X (8 rdzeni) oraz Ryzen 5 3600X i Ryzen 5 3600 (6 rdzeni), które pojawią się w sprzedaży 7 lipca w cenach od 499 do 199 USD. Dwa miesiące później dołączy do nich flagowy 16 rdzeniowy Ryzen 9 3950X, w cenie 749 USD.
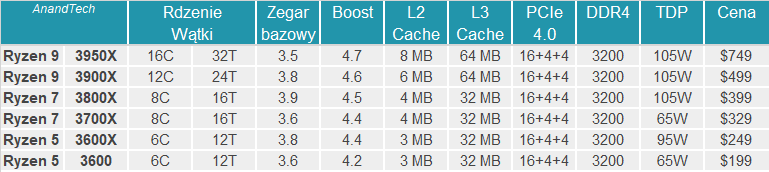
|