Technika. Droga ku wydajności
Autor: Zbyszek | Data: 23/04/07
|
 Na przestrzeni ostatnich lat nastąpiła silna ekspansja procesorów z rodziny x86, będących z definicji x86 procesorami CISC, w stronę wysoko wydajnych układów budowanych w oparciu o znacznie lepszą koncepcję RISC. Z biegiem czasu układy x86 wyposażano w coraz to bardziej skomplikowane rozwiązania, mające przybliżyć je wydajnością i sposobem działania do procesorów RISC-owych. Na przestrzeni ostatnich lat nastąpiła silna ekspansja procesorów z rodziny x86, będących z definicji x86 procesorami CISC, w stronę wysoko wydajnych układów budowanych w oparciu o znacznie lepszą koncepcję RISC. Z biegiem czasu układy x86 wyposażano w coraz to bardziej skomplikowane rozwiązania, mające przybliżyć je wydajnością i sposobem działania do procesorów RISC-owych.
Współczesne procesory wyposażone są w mnóstwo rozwiązań technicznych i programistycznych, dzięki którym osiągają znacznie większą wydajność, niż wynikałoby to tylko z ich taktowania. Zbliżenie układów x86 do architektury RISC było o tyle trudne, iż zachowanie zgodności z kodem x86 i pierwotnymi założeniami tej platformy, wymagało zastosowania dodatkowych rozwiązań w ich architekturze wewnętrznej, ponieważ platforma x86 w całości została oparta na koncepcji CISC, i pierwotnie wykluczała takie rozwiązania jak superskalarność, czy potokowość. Ale po kolei. | |
|
CISC i RISC
Architektura pierwszych procesorów z rodziny x86, takich jak 8086, 286, 386 w całości opierała się, na koncepcji CISC (Complex Instruction Set Computing), zakładającej wykonywanie operacji za pomocą bardzo złożonych i długich instrukcji.
Układy te zawierały listę instrukcji, których czasy wykonywania były bardzo długie, i były dość skąpe od strony rozwiązań technicznych. Na dodatek mogły przetwarzać tylko jedną instrukcję jednocześnie - od początku aż do jej końca, co powodowało, iż następna w kolejności instrukcja musiała długo oczekiwać, aż do całkowitego zakończenia prac nad wcześniejszym rozkazem.

Tak wyglądały pierwsze procesory x86.
Widoczny na zdjęciu 8088, to tańsza pochodna pierwszego mikroprocesora x86 - układu 8086.
Rychło w czas, bo dopiero kilka lat po ustaleniu standardu x86, zauważono, że taki tryb pracy w powiązaniu ze złożonymi rozkazami, których czasy wykonana są długie, powoduje bardzo mozolną pracę CPU. Szybko dobrnięto do wniosku, że nie tędy droga, a projektowanie i dalszy rozwój procesorów o złożonym modelu programowym nie ma większego sensu.
Postanowiono więc znacznie uprościć instrukcje - zredukowano ich długość i stopień złożoności, oraz podzielono je na grupy według typów - wykonywane w dedykowanych im, różniących się od siebie jednostkach wykonawczych. W celu dalszego uproszczenia rozkazów i zmniejszenia czasu ich wykonywania, zmniejszono liczbę trybów adresowania, oraz zdecydowano by wszystkie instrukcje miały ten sam format i tę samą długość, a dodatkowo - za wyjątkiem instrukcji pobrania (Load) i zapisu (Store), ograniczały się do operowania wyłącznie na wewnętrznych rejestrach procesora.
Tak narodziła się idea RISC (Reduced Instruction Set Computing) - idea prostych, łatwych i dających się szybko wykonywać instrukcji.
Znaczne zredukowanie złożoności i uproszczenie rozkazów, odkryło przed naukowcami pracującymi nad rozwojem architektury RISC ogromne możliwości rozwoju rozwiązań sprzętowych, zwiększających wydajność przetwarzania instrukcji. Najważniejszym z nich była...
Architektura potokowa
Architektura potokowa to rewolucyjne, i jedno z najlepszych rozwiązań, jakie kiedykolwiek zastosowane zostały w procesorach.
Dotychczas działanie każdego procesora polegało na pracy nad tylko jedną instrukcją jednocześnie. Taki sposób wykonywania rozkazów nie był zbyt wydajny, bo w danym okresie czasu tylko jedna jednostka procesora zajmowała się działaniem, a pozostałe elementy CPU albo "oczekiwały" na efekt tego działania, albo nie robiły zupełnie nic. Przykładowo podczas wczytywania instrukcji z pamięci operacyjnej, jednostka wykonawcza nie była niczym zajęta.
W efekcie tego tylko niewielka część procesora pracowała, a reszta układu była zupełnie niewykorzystana. Czyste marnotrawstwo!
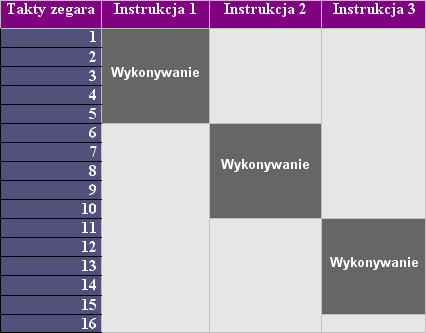
Uproszczony sposób przetwarzania instrukcji w procesorze nie dysponującym architekturą potokową.
A gdyby tak zająć pracą przy innych instrukcjach niepracujące w danym momencie jednostki i bloki procesora? Właśnie dla osiągnięcia tego celu, stworzona została architektura potokowa.
Potok wykonawczy, to porostu ścieżka przetwarzania instrukcji wewnątrz procesora, dzieląca proces ich wykonania na oddzielne, logiczne etapy. Każdy etap wykonywany niezależnie na określonym stopniu potoku, najczęściej w jednym takcie zegara procesora. Instrukcje po pobraniu z pamięci jedna po drugiej przemieszczają się w potoku wykonawczym, przechodząc przez jego kolejne stopnie.
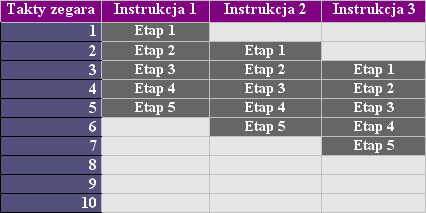
Uproszczony sposób przetwarzania instrukcji w pięcioetapowym
potoku wykonawczym.
Dzięki wprowadzeniu etapowego potoku wykonawczego, możliwa stała się równoczesna praca układów RISC nad więcej niż jedną instrukcją jednocześnie. Przykładowo możliwe stało się w jednoczesne wczytywanie instrukcji oraz równocześnie, w oddzielnym stopniu potoku wpisywanie do rejestru już wcześniej pobranej instrukcji, a w kolejnym stopniu potoku wykonywanie w jednostce wykonawczej kolejnego rozkazu.
Taki tryb pracy pozwolił wykorzystać równocześnie wszystkie bloki procesora, dając mu możliwość rozpoczęcia przetwarzania kolejnych rozkazów, jeszcze przed zakończeniem przetwarzania wcześniejszych instrukcji.
Podczas gdy układ dysponujący przetwarzaniem prostym ( nie potokowym ) po wykonaniu rozkazu, musiał przetwarzać kolejną instrukcję zaczynając "od początku", czyli pobrać ją z pamięci, wpisać do rejestru, itd. - procesor dysponujący etapowym potokiem wykonawczym, po wykonaniu rozkazu w jednostce wykonawczej, ma już wczytaną z pamięci, przygotowaną, i oczekującą na wykonanie kolejną instrukcję.
W efekcie przetwarzanie potokowe znacznie przyśpieszyło wykonywanie ciągu kolejno następujących po sobie instrukcji, i przyniosło spory wzrost wydajności.
Wydajny RISC
Wprowadzenie etapowego potoku wykonawczego dało w efekcie wydajność bliską jednej instrukcji na cykl zegara - nieosiągalną dla procesorów CISC, które na wykonanie jednego rozkazu potrzebowały przeciętnie od kilkunastu, do nawet kilkuset taktów zegara w przypadku bardzo złożonych instrukcji.

Układy x86 przejmują od swoich RISCowych krewnych nie tylko rozwiązania wewnętrznej budowy. Widoczny na zdjęciu układ Sun UltraSparc 4 korzystał z obudowy LGA na długo przed tym, gdy pojawiły się pierwsze Pentium 4 wykorzystujące to rozwiązanie.
Ale to nie wszystkie korzyści, jakie przyniosła architektura potokowa wespół z ideologią RISC. Zredukowanie złożoności instrukcji, oraz podzielenie procesu ich wykonywania na kilka mniej skomplikowanych etapów sprawiło, że poszczególne etapy stały się prostsze, przez co dawały się wykonać w mniejszych przedziałach czasu. Krótsze czasy wykonywania pojedynczych etapów spowodowały, że takty zegara procesora mogły następować po sobie w krótszych odstępach czasu.
Jakieś korzyści? - możliwość kilkukrotnego zwiększenia taktowania CPU!
Kilkakrotnie szybciej taktowany procesor, pracujący nad kilkoma instrukcjami jednocześnie w ramach jednego strumienia instrukcji. Nie trudno wyobrazić sobie skalę przyśpieszenia w stosunku do procesorów CISC dysponujących przetwarzaniem prostym.
Jednak czy coś stało na przeszkodzie, aby w procesorze RISC potoków wykonawczych było więcej niż jeden? Budowa instrukcji, na których operowały układy RISC, przystosowanych do równoległego wykonywania, aż prosiła się o zastosowanie takiego rozwiązania.
Ogromne możliwości
Procesory RISC-owe w niedługim okresie czasu posiadły więc kilka równoległych potoków wykonawczych, stając się niedoścignione dla układów x86 pod względem osiąganej wydajności. Wszystkie potoki zaopatrzono w oddzielne dla nich, zwielokrotnione jednostki wykonawcze, tym samym przeradzając układy RISC w prawdziwą superskalarną maszynkę obliczeniową.
Jakby tego było mało pojedyncze instrukcje RISC zyskały możliwość operowania na dużej ilości danych jednocześnie, w aż 32 rejestrach ogólnego przeznaczenia.
Platforma x86 zakładała jedynie 8 rejestrów ogólnego przeznaczenia, a jej instrukcje miały małe możliwości w jednoczesnym operowaniu na dużej ilości danych, co z góry ograniczało jej możliwości.
Na tle układów x86, RISC stał się obliczeniową potęgą. Dzięki wygodnym do przetwarzania rozkazom o niskim stopniu złożoności, oraz dodatkowemu podzieleniu procesu ich wykonywania na kilka prostych etapów, możliwe było zbudowanie stosunkowo szybko taktowanych układów, posiadających kilka równoległych strumieni wykonawczych.
Każdy potok o wydajności dużo większej od pojedynczego procesora CISC, każda instrukcja o możliwości operowania na większej ilości danych.
Podsumowując: kilkadziesiąt razy więcej przetwarzanych instrukcji, dodatkowo mogących operować na większej ilości danych jednocześnie. Tak ogromna była skala przepaści, dzieląca układy RISC od pierwszych w całości CISC-owych konstrukcji x86

Proste mikroprocesory RISC stosowane są jako mikrokontrolery w różnych urządzeniach elektronicznych, od nowoczesnej pralki do drukarki komputerowej.
Kod x86 niewygody dla architektury RISC
"Wykorzystanie wydajnej architektury układów RISC do wykonywania kodu x86" - na przełomie lat osiemdziesiątych i dziewięćdziesiątych ubiegłego wieku na te słowa inżynierom pracującym nad procesorami x86 włos jeżył się na głowie.
Kod x86, powstały pod koniec lat siedemdziesiątych, gdy o architekturze potokowej i równoległym wykonywaniu instrukcji nikomu się nie śniło, a procesory "raczkowały" z częstotliwością 5 MHz, był, bowiem bardzo niewygodny i ogromnie kłopotliwy dla wysokowydajnej architektury procesorów RISC.
Układy te, zostały stworzone do przetwarzania zupełnie innego typu instrukcji - instrukcji o niskim stopniu złożoności oraz identycznej długości. Rozkazy x86 natomiast cechowały się wszystkimi elementami koncepcji CISC, a więc były dość złożone i posiadały zmienną długość.
Wszystko było by jeszcze dobrze, gdyby nie fakt, że kod x86 zezwalał na różne dodatkowe atrakcje, niedopuszczalne w przypadku przetwarzania potokowego. Atrakcje takie jak: rozgałęzienia, skoki, pętle, dość popularne zależności zachodzące pomiędzy kolejnymi instrukcjami w programie, czy też instrukcje, oprócz rozkazów Load i Store, bezpośrednio odwołujące się do pamięci operacyjnej, a więc łamiące jedną z podstawowych zasad RISCa i przetwarzania potokowego - operowania wyłącznie na wewnętrznych rejestrach procesora (oczywiście za wyjątkiem instrukcji pobrania i zapisu).
W efekcie tego wszystkiego kod x86, będący faktycznie niespójnym szeregowym ciągiem niewygodnych instrukcji, zupełnie nieprzystosowanych do równoległego wykonywania - dla wielo potokowego RISCa był bardzo trudny do przełknięcia.
Pierwsze kroki x86 w stronę RISCa
Kilkanaście lat temu, wiosną 1993 roku nastąpiło pierwsze znaczące zbliżenie procesorów x86 do układów RISC. Wówczas to Intel stworzył rewolucyjny na tamte czasy procesor Pentium. Układ ten wyposażony został w dwa równoległe potoki wykonawcze.
Nie był to jednak pierwszy układ x86 wykorzystujący przetwarzanie potokowe - wcześniej procesor i486 dysponował jednym prostym potokiem wykonawczym. W artykule pominiemy jednak układ 486, skupiając się właśnie na Pentium.

Zastosowanie dwóch potoków wykonawczych miało przynieść dwukrotny wzrost wydajności. Szybko jednak okazało się, że w praktyce osiągnięcie tego celu przy samym tylko podwojeniu potoków wykonawczych jest niemożliwe. Aby efektywnie wykorzystać dwa równoległe potoki wykonawcze, konieczne były dalsze zmiany w architekturze.
Żeby potoki nie zatrzymywały się, jeden czekając aż jednostka wykonawcza wykona instrukcję z drugiego potoku, w układzie tym zaimplementowano dwie współbierne jednostki arytmetyczno-logiczne. Dzięki temu, Pentium stał się pierwszym w historii superskalarnym, a więc wyposażonym w więcej niż jedną jednostkę ALU (Arithmetic Logic Unit), procesorem x86.
Natomiast w celu ograniczenia sytuacji, w której dochodziło do wstrzymywania potoków, ze względu na ograniczenia w dostępie do pamięci cache, pamięć tą podzielono na dwie równe i osobne części. Jedną dedykowano instrukcjom, i umieszczono przed potokami wykonawczymi, natomiast drugą umieszczoną za potokami wykonawczymi dedykowano wynikom instrukcji, a więc danym. Jest to tzw. Harvardzka architektura pamięci.
Oprócz tego Pentium otrzymał znacznie unowocześnioną jednostkę zmiennoprzecinkową, o kilkakrotnie większej wydajności, od tej wcześniej stosowanej w układzie i486.
Rozwiązania te wyeliminowały ograniczenia techniczne, zwalniające pracę dwóch równoległych potoków wykonawczych. Jednak problem, w dodatku znacznie większy leżał zupełnie gdzie indziej...
Przetwarzanie potokowe i x86 - mieszanka wybuchowa
Wykorzystanie dwóch równoległych potoków wykonawczych do pracy nad specyficznym kodem x86, potwierdziło, że szeregowy ciąg instrukcji powiązanych między sobą wzajemnymi relacjami, jest niesłychanie trudny do równoległego wykonywania.
Aby narobić sporego zamieszania w potokach wykonawczych procesora, wystarczyły dwie typowe instrukcje x86 połączone ze sobą prostą zależnością - do wykonania jednej z nich potrzebny jest wyniki innej instrukcji. Co wtedy, gdy obie te instrukcje nastąpią jedna po drugiej i równocześnie znajdą się w dwóch równoległych potokach?
Wystąpienie takiej sytuacji powodowało konieczność zatrzymania pracy potoku wykonawczego, z instrukcją oczekującą na wynik wykonania drugiej instrukcji znajdującej się w drugim potoku. Wstrzymanie pracy potoku musiało trwać do czasu całkowitego wykonania i wczytania wyniku drugiej instrukcji, wykonywanej w sąsiednim potoku.
Łatwo się domyślić, że zaistnienie takiej sytuacji owocowało spadkiem szybkości wykonywania instrukcji. A co w wypadku, gdy jednocześnie w potokach procesora znalazło się więcej takich rozkazów? Powstał w nich po prostu duży korek, zwalniający pracę potoków wykonawczych, i w końcowym efekcie powodujący wyraźny spadek wydajności całego CPU.
Ale to nie koniec niespodzianek. Jeszcze większe kłopoty powodowały instrukcje kodu x86 bezpośrednio odwołujące się do pamięci operacyjnej. Wykonanie takiej instrukcji w potoku wykonawczym, powodowało konieczność zatrzymania pracy tego potoku na dość długi okres czasu, potrzebny do wykonania komunikacji z pamięcią operacyjną, czyli przeciętnie aż kilkaset cykli zegara! Dramat.
Jednak nie była to jeszcze sytuacja najgorsza z możliwych. W potokach układu oba typy instrukcji mogły przecież znaleźć się jednocześnie, a dodatkowo jeszcze we wzmożonych ilościach. I co wtedy? Rozwiązanie takiej plątaniny trwałoby ogrom czasu, a wydajność spadła niemalże do zera. Koszmar!
Oczywiście tak ekstremalnie niekorzystna sytuacja występowała bardzo rzadko, bo w kodzie x86 instrukcje te nie stanowiły większości. Jednak o zatrzymanie pracy całego CPU na kilkaset cykli zegara nie było trudno.
Wystarczyło wystąpienie dwóch odpowiednio ułożonych instrukcji: w pierwszym potoku instrukcja odwołująca się do pamięci RAM, w drugim instrukcja oczekująca na wynik innej instrukcji z pierwszego potoku - wstrzymanym na kilkaset cykli zegara ze względu na odwołanie do pamięci operacyjnej. Wówczas drugi potok, tak jak i pierwszy wstrzymywany był na kilkaset taktów zegara, aż do czasu wykonania instrukcji stojącej obecnie w zatrzymanym pierwszym potoku.
Specyfika kodu x86 okazała się więc dla architektury potokowej dużym problemem, skutecznie ograniczającym jej ogromne możliwości. Nie ulegało wątpliwości, że należało w jakiś sposób wesprzeć ją w wykonywaniu nieprzyjaznych dla niej instrukcji kodu x86.
Kłopotliwe przeskoki
Aby jednak atrakcji nie było za mało, całą sytuacje dodatkowo bardzo skomplikowały rozkazy takie jak rozgałęzienia czy instrukcje warunkowe. Instrukcje te są wykonywane lub nie, w zależności od wyników wcześniejszych instrukcji programu, i mogą ( lecz nie muszą ), powodować przeskok do innego fragmentu kodu. W efekcie procesor nie wie, czy skok zostanie wykonany, czy też nie.
Wykonanie przeskoku niesie za sobą dość poważne konsekwencje, a mianowicie unieważnienie całej następującej po nim zawartości potoku. Każdorazowo po wykonaniu przeskoku, konieczne jest wstrzymanie potoków, opróżnienie ich zawartości, i ponowne pobranie instrukcji, począwszy od rozkazu, do którego wykonany został przeskok. A co w wypadku, gdy instrukcja do której program skacze znajduje się w pamięci operacyjnej?
Wówczas cały proces przeładowywania potoków, trwający przeciętnie kilkadziesiąt taktów zegara wydłuża się o kilkaset cykli zegara, niezbędnych do wykonania komunikacji z pamięcią operacyjną celem pobrania owej instrukcji.
Co gorsza, taka konieczność zachodzi praktycznie zawsze, bo stosunkowo niewielka pamięć podręczna procesora mieści tylko bardzo mały fragment całego programu znajdującego się w pamięci operacyjnej. Przeładowanie potoków połączone z koniecznością czasochłonnego pobrania instrukcji, do której wykonywany jest skok, powoduje oczywiście stosunkowo długą przerwę w wykonywaniu rozkazów, i drastycznie wpływa na spadek wydajności całego procesora.
Aby jednak tak bardzo niekorzystna sytuacja nie miała miejsca za każdym razem wystąpienia przeskoku, w Pentium zastosowane zostało rozwiązanie pozwalające znacznie przyśpieszyć przeładowywanie potoków. Jakim sposobem? Skoro instrukcja i tak będzie musiała zostać pobrana z pamięci, praktycznie za każdym razem wykonania przeskoku, należy sprawić, by jej pobranie nie zatrzymywało pracy całego procesora na kilkaset cykli zegara. Jak? Po prostu - zacząć ją wcześniej pobierać!
W tym celu w układzie zaimplementowano system predykcji rozgałęzień programu, pozwalający znacznie przyśpieszyć pobranie z pamięci instrukcji, do której wykonywany jest skok. Rozwiązanie to szybko stało się standardem, i dziś jest wykorzystywane przez każdy procesor x86.
Zadaniem systemu predykcji rozgałęzień jest nieustanna analiza przetwarzanego programu, czyli ciągu instrukcji, w celu sprawdzenia czy wczytywane instrukcje warunkowe i rozgałęzienia, spowodują przeskok do innego fragmentu kodu, czy nie, i wykonywana będzie dalsza kolejna części kodu. Dlatego system ten wyposażono w zaawansowane algorytmy prognozujące. Jeżeli system wytypuje, że skok zostanie wykonany, odpowiednia instrukcja jest natychmiast, jeszcze przed wykonaniem przeskoku, pobierana z pamięci operacyjnej do pamięci cache układu.
Dzięki temu, w momencie wykonania przeskoku, proces przeładowywania potoków nie musi już oczekiwać na konieczność czasochłonnego pobierania owej instrukcji z pamięci RAM, bo ta znajduje się już w pamięci cache układu. W efekcie przeładowywanie potoków trwa zdecydowanie krócej, co nie pozostaje bez pozytywnego wpływu na wydajność CPU.
Jeżeli natomiast dojdzie do pomyłki w przewidywaniach, w pamięci cache procesora nie znajdą się potrzebne instrukcje, które powinny być właśnie wykonywane i praca potoków wykonawczych zostanie zatrzymana do czasu ich pobrania z pamięci. Z tego powodu trafność przewidywań systemu predykcji skoków, jest kluczowa dla wydajności całego procesora.
W celu osiągnięcia jak największej skuteczności w przewidywaniu skoków, system ten wyposażono także w możliwość sprawdzania historii ostatnio wykonywanego przez procesor kawałka kodu. W efekcie tego sprawdzone zostaje też, czy aktualnie wczytywana instrukcja, mogąca potencjalnie spowodować przeskok, była już wcześniej wykonywana, a jeżeli tak, to jak się wówczas zachowała. Może to nieść cenną podpowiedź, i ułatwić prognozę, jak teraz zachowa się właśnie wczytywany rozkaz.
Okazało się to szczególnie pomocne, w przypadku wykonywania wielokrotnie powtarzających się skoków.
System predykcji rozgałęzień zastosowany w Pentium, cechował się trafnością predykcji wynoszącą około 80%, i przyczynił się do znacznego zniwelowania strat wydajności, powodowanych przez konieczność przeładowywania potoków, połączoną z czasochłonnym odwołaniem do pamięci operacyjnej.
Jednak pozostałe problemy zachodzące w potokach wykonawczych, doprowadzające do ich częstego wstrzymywania i w efekcie dużego spadku wydajności procesora, takie jak instrukcje bezpośrednio odwołujące się do pamięci operacyjnej, czy zależności zachodzące pomiędzy instrukcjami znajdującymi się w równoległych potokach, wciąż występowały.
Konieczne stało się wymyślenie, wzorem systemu predykcji rozgałęzień, rozwiązań w jak największym stopniu minimalizującym ich negatywne skutki. Na to potrzeba było czasu.
1995 - rok procesorowych rewolucji
Na początku 1995 roku pojawił się procesor AMD K5, będący odpowiedzią na procesor Intel Pentium i pierwszym w historii układem stworzonym przez AMD, firmę dotychczas produkującą różne odmiany Intelowskich układów 386 i 486.
W Praktyce K5 nie był w pełni własną konstrukcją AMD - powstał poprzez zmodyfikowanie układu NextGEN, przejętego przez AMD wraz z całą firmą.

Już w czasach K5 AMD stosowało oznaczenia wydajności Performance Rating ( PR ) współcześnie znane z procesorów Athlon 64. Widoczny na zdjęciu K5 wydajnością
odpowiadał Pentium 200MHz, pracując z niższą od niego częstotliwością.
W K5 zastosowano nowatorską technikę, polegającą na przekodowywaniu wewnątrz układu instrukcji x86, na mikroinstrukcje wewnętrznego kodu procesora. Instrukcje x86 będące złożonymi instrukcjami o zmiennej długości, przekodowywane były na prostsze mikroinstrukcje o stałej długości, a te z kolei przeznaczone były do dalszego wykonywania w potokach układu. Przeciętnie jedna markoinstrukcja x86, tłumaczona była na 2-3 mikroinstrukcje wewnętrzne procesora.
Dodatkowo nad procesem przekodowywania instrukcji, czuwał specjalnie stworzony do tego celu kompilator, który w drodze przekodowywania ciągu instrukcji, mógł dokonać na nim pewnych optymalizacji, zastępując najbardziej niewygodne rozkazy zestawem innych instrukcji. Oczywiście wszystko to w pewnych granicach, by nie zmienić programu. To było by niedopuszczalne.
Poza jednym - zdecydowano wówczas by na drodze procesu przekodowywania, pominąć oprócz rozkazów odczytu i zapisu ( Load i Store ) wszystkie pozostałe instrukcje bezpośrednio odwołujące się do lokacji w pamięci operacyjnej, i w ogóle nie uwzględniać ich w przetwarzanym w potokach wewnętrznych mikrokodzie. Wyeliminowało to przynoszące ogromne straty wydajności instrukcje, wstrzymujące potoki wykonawcze na kilkaset cykli zegara - problem bardzo komplikujący potokowe przetwarzanie kodu x86.
Tak drastyczna zmiana nie mogła jednak obejść się bez konsekwencji. Wyeliminowane instrukcje były przecież wykorzystywane przez programy. Efekt: znaczna część programów nie działała poprawnie na K5. Konieczne było czasochłonne przepisanie aplikacji od nowa, bez uwzględniania w nich tychże instrukcji. Na AMD posypały się gromy, a sam procesor cieszył się bardzo niewielkim powodzeniem. Powszechne było całkowicie błędne stwierdzenie, że firma ta nie jest w stanie stworzyć poprawnie działającego układu. Jednak ktoś, kto wiedział, czym spowodowany został taki fakt rzeczy, dostrzegał w tym ogromny krok milowy.
Gdyby nie ówczesne poświęcenie AMD, współczesne procesory mogłyby po dziś dzień "męczyć się" z instrukcjami bezpośrednio odwołującymi się do pamięci operacyjnej. Intel mający w pamięci błędy, i niedawną wymianę dużych ilości procesorów Pentium, mógłby nie zdecydować się na wprowadzenie tak drastycznego, ale koniecznego posunięcia w swoich przyszłych procesorach.
Dziś, na szczęście, można tylko domniemywać jak duży spadek wydajności współczesnych CPU spowodowałaby dalsza konieczność wykonywania instrukcji odwołujących się do lokacji w pamięci RAM, a jeżeli jakiś programista umieści takie, dawniej powszechnie stosowane instrukcje w swoim programie, będzie to tylko i wyłącznie jego błąd.
Bez kuli u nogi
Na drodze kompilacji instrukcji x86, w nieco drastyczny sposób rozwiązano więc ogromny, powodujący dużą stratę wydajności problem, mający miejsce w układach Pentium.
Przekodowywanie rozkazów nie zmniejszyło jednak skali innych problemów, jakie miały miejsce w potokach wykonawczych procesora - wzajemne relacje zachodzące pomiędzy instrukcjami, wstrzymujące potoki wykonawcze oraz rozgałęzienia powodujące konieczność czasochłonnego przeładowywania potoków - nadal występowały.
Gdzie w takim razie leżał sens zastosowania tego rozwiązania? To tylko pozornie nic nie znaczące usprawnienie, w połączeniu z odpowiednim kompilatorem czuwającym nad procesem przekodowywania rozkazów, całkowicie eliminującym bądź zastępującym najbardziej złożone instrukcje x86 na zestawy innych rozkazów, otwarło ogromne możliwości przybliżenia budowy wewnętrznej i sposobu działania procesorów x86, do niedoścignionego wzorca - układów RISC.
Dotychczas do potoków wykonawczych procesora wprowadzane były instrukcje kodu x86 w niezmienionej postaci, a wiec cechujące się zmienną długością i znaczną złożonością. Natomiast przekodowywanie pojedynczych rozkazów x86 na kilka mniej złożonych instrukcji o stałej długości, spowodowało, że instrukcje, z jakimi pracowały potoki wykonawcze procesora upodobniły się do instrukcji, na jakich operowały układy RISC! Skoro instrukcje wykonywane wewnętrznie przez procesor upodobniły się do rozkazów RISC, logicznie więc, także i wewnętrzna architektura układów x86 mogła się bardzo upodobnić do architektury układów RISC!
Wykorzystał to Intel w swoim procesorze Pentium Pro, wprowadzonym końcem roku 1995. Nowy układ Intela, zbudowany na zupełnie nowej architekturze wewnętrznej, nazwanej P6, podobnie jak AMD K5 stosował technikę przekodowywania rozkazów x86, na mikroinstrukcje wewnętrznego kodu procesora.
Praca wewnętrznych potoków wykonawczych układu z rozkazami o niskim stopniu złożoności i stałej długości, umożliwiła zastosowanie kilku zupełnie nowych rozwiązań, wypływających na znaczne przyśpieszenie wykonywania ciągu następujących po sobie instrukcji. Najważniejszym z nich było niekolejne wykonywanie rozkazów w potokach wykonawczych CPU.

Pentium Pro zapoczątkował linię wysokowydajnych procesorów, której najnowszym wcieleniem jest układ Core 2 Duo.
Poza kolejnością
Niekolejne wykonywanie instrukcji przyniosło, niemalże bezcenne dla potokowych układów x86, obejście problemu skutecznie zwalniających pracę potoków wykonawczych zależności, występujących pomiędzy kolejnymi instrukcjami w ich ciągu.
W celu umożliwienia zamiany kolejności wykonywanych instrukcji, w układzie Pentium Pro zaimplementowano systemy niekolejnego (Out of Order Execution) wykonywania rozkazów. Rozwiązanie to, podobnie jak system predykcji rozgałęzień, stało się jednym ze standardów w budowie współczesnych układów x86.
W tym rozwiązaniu, kolejno następujące po sobie instrukcje po wyjściu z dekodera rozkazów, i przed ich wykonaniem w jednostkach wykonawczych, trafiają do specjalnego bufora, nazwanego ReOrder Buffer (ROB), mieszczącego kilkadziesiąt kolejnych instrukcji z kolejki. Procesor analizuje zbiór rozkazów w celu określenia najlepszej możliwej kolejności ich wykonywania.
Następnie instrukcje pobierane są do dalszego wykonania w jednostkach wykonawczych, już nie w kolejności ich występowania w kolejce, lecz w ustalonej kolejności ich wykonania, wykluczającej maksymalnie dużo zależności, zachodzących równocześnie pomiędzy nimi.
Po wykonaniu rozkazów, z powrotem przywracana jest ich właściwa kolejność.
Dotychczas konieczność wykonywania instrukcji w kolejności ich występowania w programie, powodowała częste wstrzymywanie się potoków wykonawczych, przez co ich pełne możliwości wykonawcze nie były osiągane.
Rozważmy układ dysponujący dwoma równoległymi potokami wykonawczymi. Przykładowo, gdy do wykonania jakiejś instrukcji potrzebny był wynik innego rozkazu, wykonywanego równocześnie w drugim potoku wykonawczym, lub też pobranie danej z pamięci, wykonanie tej instrukcji było chwilowo wstrzymywane - aż do czasu pobrania niezbędnych do jej wykonana danych. Z tego powodu potok z tą instrukcją musiał zostać na pewien czas wstrzymany, i w tym czasie nie mógł on wykonywać innych rozkazów.
Natomiast umożliwienie przekolejkowania instrukcji wyeliminowało większość sytuacji, w których dany potok wykonawczy oczekując na spełnienie wszystkich warunków koniecznych do wykonania rozkazu, generował puste cykle (nie wykonywał żadnych instrukcji).
Dzięki odpowiedniej zamianie kolejności wykonywanych instrukcji, w czasie w którym wykonywanie danej instrukcji jest wstrzymane, potok wykonawczy może zająć się pracą przy innych rozkazach których wykonanie jest bezproblemowo możliwe.
Strumień instrukcji przegrupowywany jest tak, aby proces jego wykonywania w równoległych potokach wykonawczych przebiegał jak najszybciej, i wszystkie potoki były maksymalnie wykorzystane.
Dzięki zastosowaniu systemów niekolejnego wykonywania instrukcji, procesor został więc zwolniony z konieczności bezwzględnego wykonywania rozkazów w kolejności ich nadchodzenia z dekodera instrukcji. Umożliwiło to ich równolegle wykonywane bez częstego zachodzenia sytuacji, wstrzymujących potoki wykonawcze układu. Częstość sytuacji, w których dochodziło do wstrzymania któregoś z potoków spadła praktycznie do zera.
W efekcie taki sposób wykonywania instrukcji spowodował znacznie płynniejszą pracę potoków wykonawczych. Płynniej pracujące potoki to też więcej wykonywanych instrukcji i lepiej wykorzystane jednostki wykonawcze. Rozwiązanie to przyniosło znaczny wzrost wydajności CPU. Ale na tym nie koniec pozytywnych stron jego zastosowania.
Więcej mocy
Niekolejne wykonywanie instrukcji było doskonałą furtką do dalszego zbliżenia wnętrza procesora x86, do procesorów RISC.
Dotychczas zastosowanie więcej niż dwóch potoków wykonawczych w procesorach x86 nie miało najmniejszego sensu. Większa liczba potoków, spowodowałaby drastyczny wzrost ilości zależności zachodzących jednocześnie pomiędzy instrukcjami znajdującymi się w potokach.
I zamiast wzrostu wydajności - jej spadek, bo potoki z instrukcjami połączonymi między sobą siecią zależności, wstrzymałyby się na dobre. Wprowadzenie przekolejkowania instrukcji znacznie zmniejszyło skalę tego problemu, dzięki temu w układach x86 możliwe stało się zastosowanie więcej niż dwóch potoków wykonawczych.
W Pentium Pro zastosowano aż cztery równoległe potoki wykonawcze - liczba niewyobrażalna na ówczesne czasy. Do ich obsługi przeznaczono dwie jednostki arytmetyczno-logiczne i dwie zmiennoprzecinkowe FPU (Floating Point Unit). Dodatkowo jednostki FPU same w sobie zostały znacznie zmodyfikowane. W stosunku do wcześniejszych układów takich jak Pentium czy K5, wzrost wydajności był bardzo duży. Zwłaszcza imponujący był wzrost wydajności w operacjach zmiennoprzecinkowych, w których procesory x86 dotychczas najbardziej ustępowały układom RISC.
Oprócz tego, aby zmniejszyć straty wydajności powodowane koniecznością przeładowywania tak dużej liczby potoków wykonawczych po wykonaniu przeskoku, w nowej architekturze dokonano kolejnych usprawnień. Znacznie udoskonalono system predykcji rozgałęzień, stosowany od ponad dwóch lat w układzie Pentium, zwiększając trafność predykcji, z około 80, do ponad 90%, oraz zaimplementowano ogromną, na ówczesne czasy, pamięć podręczną cache drugiego poziomu, o wielkości od 256 do 1024 KB. Warto dodać, że przeciętnie komputery PC posiadały wówczas kilka megabajtów pamięci RAM.
Duża pamięć podręczna, mieściła spory kawałek wykonywanego przez procesor kodu, a czas dostępu do niej był wielokrotnie szybszy niż do pamięci operacyjnej. W przypadku błędnej predykcji istniała więc spora szansa, że odwołanie po instrukcje nastąpi do pamięci cache L2 zamiast do RAMu, i z tego powodu będzie trwać zdecydowanie krócej.

Pentium Pro w wersji z 1MB pamięci cache L2. Po lewej stronie widoczny rdzeń układu, po prawej dwa identyczne 512 KB chipy pamięci cache.
Pentium Pro stał się procesorem na długo niedoścignionym pod względem wydajności. Był też drogi w produkcji, a na dodatek posiadał cechę znaną z procesorów AMD K5 - nie wykonywał, poza rozkazami Load i Store, instrukcji bezpośrednio odwołujących się do lokacji w pamięci operacyjnej. Na dodatek miał istotną dla rynku domowych PC wadę - 16 bitowe aplikacje starszego typu - jeszcze dość powszechnie wówczas wykorzystywane, działały na nim wolniej niż na Pentium pierwszej generacji. Konieczne stało się przystosowanie oprogramowania do układu nowej generacji.
Intel postanowił więc dedykować Pentium Pro dla wysoko wydajnych serwerów wykorzystujących oprogramowanie Unixowe, i poczekać z wprowadzeniem jego architektury na rynek komputerów domowych, w między czasie podejmując próbę rozwiązania kolejnej słabej strony układów x86.
Jedna instrukcja, wiele danych
Mimo ogromnego zbliżenia architektury procesorów x86 do układów RISC, jakie dokonało się w 1995 roku, procesory RISC nadal znacznie przewyższały układy x86 pod pewnymi względami, min. mogąc operować na większej ilości danych jednocześnie.
Najnowsze procesory x86 były na tym polu mocno ograniczone, ponieważ archaiczny kod x86 tworzony dwadzieścia lat wcześniej, z myślą o prymitywnych, z punktu widzenia Pentium Pro układach, nie pozwalał efektywnie wykorzystywać ich możliwości.
Standard x86 powstawał w czasach 8 bitowych ( wewnętrznie ) CPU, oraz zapewnień, że komputery osobiste nigdy nie będą potrzebowały więcej niż 640 KB pamięci RAM. Ilości danych, jak i możliwości operowania nimi przez układy były wówczas skromne. Zatem instrukcje x86 powstając na miarę swoich czasów - mogły operować na równie skromnej, co wówczas ilości danych.
Jednak z biegiem czasu procesory uległy znacznej ewolucji i techniczne możliwości jednoczesnego operowania na dużej ilości danych stały otworem. Rozkazy x86 nie potrafiły jednak tych możliwości wykorzystywać, gdyż były instrukcjami typu SISD (Single Instruction, Single Data), mogącymi operować tylko na jednej danej jednocześnie. Standard x86 w ogóle nie uwzględniał instrukcji, które mogłyby operować na większej ilości danych "za jednym zamachem".
W praktyce Pentium Pro o architekturze wewnętrznej bliskiej układom RISC, musiał wykonywać program za pomocą identycznego zestawu makroinstrukcji jak archaiczne procesory Intel 386 i 486.
Rozwiązanie tego problemu nadeszło wraz z nowymi procesorami Intela w pierwszej połowie 1997 roku, kiedy to na rynek wprowadzone zostały układy Pentium II, oraz Pentium MMX.
Pentium II wykorzystywał architekturę P6 procesora Pentium Pro, przy czym był jego bardziej udomowioną i tańszą w produkcji wersją. W architekturze wewnętrznej dokonano tylko niewielkich zmian mających rozwiązać podstawową bolączkę układu Pentium Pro - niską wydajność w aplikacjach starszego typu. Natomiast Pentium MMX fizycznie był znacząco zmodyfikowanym Pentium pierwszej generacji obecnym na rynku od 1993 roku.

Pod koniec ubiegłego wieku najwydajniejsze procesory montowane były w kasetowych obudowach i wpinane pionowo w gniazdo slot, przypominające wyglądem typowe gniazda PCI.
Jednak znacznie ważniejsze, z dzisiejszego punktu widzenia zmiany, dokonały się w tych układach od ich strony logicznej. W nowych CPU procesorowy gigant zawarł technologię MMX (Multimedia Matrix eXtension). W jej ramach w układach zaimplementowany został zestaw 57 zupełnie nowych instrukcji nazwanych instrukcjami MMX, oraz wyznaczony specjalny 64 bitowy rejestr o identycznej nazwie. Nowe rozkazy były instrukcjami typu SIMD (Single Instruction, Multiple Data) - mogącymi operować na kilku danych jednocześnie.
Implementacja rozkazów typu SIMD, umożliwiła wykonywanie jednego działania na kilku danych jednocześnie, i zniosła wspomniane nieco wcześniej ograniczenia nakładane na procesory przez przestarzały model x86. Możliwe stało się wpisanie do rejestru kilku danych i polecenie jednej instrukcji wykonania na nich tej samej operacji jednocześnie.
Przykładowo program graficzny mógł umieścić w rejestrze MMX osiem jednobajtowych wartości koloru, i polecić jednej instrukcji zmianę ich odcienia. Wykonanie tego działania przy użyciu standardowych rozkazów kodu x86 wymagałoby użycia ośmiu takich instrukcji, podczas gdy wystarczyła do tego tylko jedna instrukcja MMX!
Dzięki technologii MMX, programista piszący program mógł zastąpić archaiczne instrukcje kodu x86 nowymi rozkazami z zestawu MMX, pozwalającymi w znacznie lepszym stopniu wykorzystać możliwości najnowszych CPU, i wyraźnie poprawić ich wydajność. W praktyce programy optymalizowane pod kątem technologii MMX osiągały o kilkadziesiąt procent większą wydajność.
Instrukcje MMX zniosły, więc ograniczenia nakładane na najnowsze procesory x86 przez naleciałości historyczne, pozwalając im wykonywać określone działania w prostszy, mniej złożony, i wymagający dużo mniej czasu sposób. Technologia MMX miała jednak swoje, jak się później okazało, dość poważne wady...
Wciąż słabe zmienne przecinki
Architektura P6 przyniosła znaczący wzrost wydajności w obliczeniach zmiennoprzecinkowych, jednak procesory x86 nadal bardzo odbiegały od układów RISC pod tym względem. W zmniejszeniu tej straty wcale nie pomogły instrukcje MMX.
Poważne wady MMX zauważono bardzo szybko. Instrukcje te były rozkazami wyłącznie stałoprzecinkowymi, wobec czego operacje zmiennoprzecinkowe nadal wykonywane były za pomocą przestarzałych rozkazów x86 typu SISD.
Na dodatek nie do końca rozsądna implementacja MMX nie tylko nie przyniosła wzrostu wydajności zmiennoprzecinkowej, ale jej spadek! Specjalny 64 bitowy rejestr dedykowany instrukcjom MMX wyznaczony został... w rejestrze jednostek FPU, przez co wykonywanie operacji zmiennoprzecinkowych zostało utrudnione.
Całą sytuacje dodatkowo komplikował fakt, że komputery na dobre odeszły od mało wymagającego, tekstowego sposobu obsługi, przekształcając się w centrum multimedialne. Pojawiły się filmy DVD, pierwsze trójwymiarowe gry i akcelatory grafiki 3D, oraz masa innych zastosowań i aplikacji, w których operacje zmiennoprzecinkowe były wykorzystywane w zdecydowanie większej niż dotychczas skali.
Dynamiczny rozwój multimediów spowodował, że wysoka wydajność zmiennoprzecinkowa CPU stała się znacznie bardziej ważna niż dotychczas, i zaczęła mieć kluczowe znaczenie dla wydajności końcowej całego procesora. Konieczne stało się więc wyraźne zwiększenie wydajności układów w obliczeniach zmiennoprzecinkowych. Jedną z możliwości było, wyposażenie procesorów wzorem stałoprzecinkowych instrukcji MMX - w zmiennoprzecinkowe rozkazy typu SIMD.
Pierwszą próbę podjęła konkurencyjna wobec Intela korporacja AMD. Latem 1998 roku pojawił się układ AMD K6-2, zawierający zestaw 21 zmiennoprzecinkowych instrukcji typu SIMD-FP, nazwany 3DNow! Z czasem dodano jeszcze kolejne 24 instrukcje tworząc zestaw Enhanced 3DNow!
Jednak rejestr wykonawczy pozostał bez zmian - instrukcje nadal operowały w rejestrze jednostki zmiennoprzecinkowej, tym samym utrudniając jej pracę.
W efekcie tego, jak i małej liczby samych instrukcji, rozwiązanie 3D Now! przyniosło jedynie nieznaczny wzrost wydajności, i było wykorzystane tylko przez niewielką liczbę aplikacji.
Technologia 3D Now! z pewnością nie była tym, czego układy x86 bardzo potrzebowały. Było to rozwiązanie na tyle nieznaczące, że Intel nigdy nie zastosował go w swoich układach, natomiast wprowadzając własne rozwiązanie dla zmiennoprzecinkowych rozkazów SIMD.
SSE - druga generacja SIMD w układach x86
Co nie udało się AMD osiągnęła Intelowska technologia SSE (Streaming SIMD Extensions), wprowadzona wiosną 1999 roku w procesorze Pentium III.
Implementacja SSE obejmowała oprócz wprowadzenia nowych zmiennoprzecinkowych instrukcji SIMD-FP, wbudowanie w procesor zupełnie odrębnego, 128 bitowego 8-pozycyjnego rejestru, oraz dodanie dodatkowych instrukcji pomocniczych, ułatwiających przesyłanie danych pomiędzy pamięcią operacyjną, i cache.

Wprowadzenie nowego 128 bitowego rejestru okazało się prawdziwym strzałem w dziesiątkę! Rozwiązało to dość duży problem istniejący we wcześniejszych rozwiązaniach MMX i 3D Now! - które korzystając z wydzielonego fragmentu rejestru jednostki zmiennoprzecinkowej, powodowały spadek jej wydajności. Wszystkie rozkazy SSE wykonywane były w oddzielnym 128 bitowym rejestrze bez wykorzystywania rejestru jednostki FPU.
Zastosowanie nowego dodatkowego rejestru, oprócz rozwiązania problemu znanego z technologii MMX, przyniosło też znaczącą korzyść - możliwość jednoczesnego operowania jedną instrukcją na dwa razy większej ilości danych. Instrukcje MMX mogły operować na ośmiu bajtach danych jednocześnie, rozkazy SSE natomiast na szesnastu.
Zestaw instrukcji SSE zaimplementowany w procesorze Pentium III składał się z 70 rozkazów, i stał się największym wówczas, jednorazowym rozszerzeniem listy instrukcji standardowego modelu x86, o nowe rozkazy typu SIMD. Jednak już kilkanaście miesięcy po jego wprowadzeniu Intel pobił swój własny rekord - implementując w procesorze Pentium 4 aż 144 instrukcje SSE2.
SSE2 przyniosło znaczącą ewolucję SSE pierwszej generacji. Możliwe stały się zmiennoprzecinkowe operacje podwójnej precyzji, a także i niektóre operacje stałoprzecinkowe. Duża liczba instrukcji nie tylko pozwoliła programistom zastąpić archaiczne i operujące na małej ilości danych rozkazy x86 nowymi rozkazami z rodziny SSE, praktycznie we wszystkich możliwych sytuacjach, ale też umożliwiła wykorzystanie wielu operacji zupełnie nowego typu.
W efekcie wzrost wydajności programów optymalizowanych pod kątem technologii SSE był znaczący.
128 bitowe zmiennoprzecinkowe FPU - coraz bliżej RISCa
Zwłaszcza zmiennoprzecinkowe instrukcje SIMD podwójnej precyzji zestawu SSE2, stały się swoistą rewolucją, i z czasem stały się coraz powszechniej wykorzystywane przez programistów. Były one jednak wykonywane przez 80 bitowe jednostki FPU procesorów x86 w dwóch taktach zegara. W tej niedoskonałości kryły się dalsze możliwości zwiększenia wydajności zmiennoprzecinkowej układów x86.
Aby zapewnić wykonywanie instrukcji SSE podwójnej precyzji w jednym takcie zegara, jednostki FPU rozbudowano do 128 bitów długości. Dzięki temu wydajność zmiennoprzecinkowa wydatnie wzrosła, co doskonale widać na przykładzie najnowszej architektury Core 2 Intela.

Zastosowanie 128 bitowych jednostek FPU stało się kolejnym krokiem układów x86 w stronę swojego niedoścignionego wzorca - układów RISC, które już od kilkunastu lat posiadały tak rozbudowanie jednostki zmiennoprzecinkowe.
128-bitowe jednostki FPU stały się obecnie wiodącym rozwiązaniem w układach x86, i także AMD niebawem wprowadzi na rynek układy w nie wyposażone, i zdolne wykonywać złożone rozkazy SSE w jednym takcie zegara.
Na przestrzeni ostatnich kilkunastu lat układy x86 zyskały więc wielo potokową superskalarną architekturę układów RISC, oraz nowe listy rozkazów zastępujące archaiczne instrukcje x86. Jednak liczba dostępnych rejestrów modelu programowego wciąż pozostała niezmieniona.
Zaawansowane technicznie i programistycznie układy w dalszym ciągu musiały ( i po dziś dzień muszą ), operować na tylko ośmiu rejestrach ogólnego przeznaczania modelu x86.
x86-64 - więcej rejestrów
Końcem 2003 roku, wraz z wprowadzeniem na rynek układów Athlon 64, standard x86 uległ odświeżeniu. Dzięki wydłużeniu rejestrów modelu programistycznego, możliwa stała się praca w 64 bitowym trybie. Ale oprócz tego, procesory x86 zyskały coś jeszcze...
W czasach, gdy powstawał standard x86, nikt nie przewidywał, że w przyszłości układy będą mogły wykonywać tak wiele rozkazów jednocześnie, stąd archaiczny model programowy x86 zawiera niewielką liczbę rejestrów, na których mogą operować instrukcje. Na dodatek wielu rejestrom przypisana jest konkretna funkcja, co jeszcze bardziej ogranicza możliwości ich wykorzystania.
Jest to sporym utrudnieniem dla nowoczesnych wielo-potokowych i superskalarnych układów x86, w których podczas równoległego wykonania więcej niż jednej instrukcji - kilka rozkazów może zamierzać przeprowadzić operacje na tym samym rejestrze modelu x86.
Wprawdzie, aby zmniejszyć skalę tego problemu, układy x86 już od połowy lat dziewięćdziesiątych posiadają system przemianowywania rejestrów, i dodatkowe kilkadziesiąt rejestrów pomocniczych, które przejmują tymczasowo rolę zajętego rejestru x86. To jednak rozwiązanie to jest tylko obejściem problemu - a dokładniej udawaniem, że rejestrów jest więcej, niż ich faktycznie w modelu x86 jest.
Dlatego w x86-64 oprócz wydłużenia samych rejestrów, dokonano ważnej zmiany- liczba rejestrów ogólnego przeznaczenia uległa podwojeniu. Dodatkowo zwiększono, też dwukrotnie, liczbę 128 bitowych rejestrów SSE.
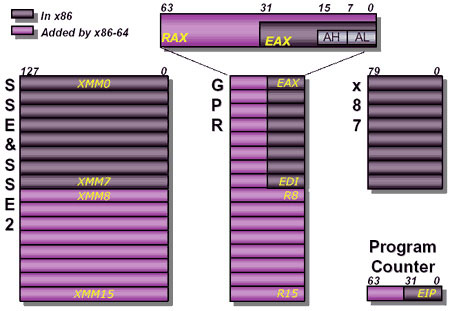
Korzyści wynikające z istnienia dodatkowych rejestrów modelu programowego, doskonale widać na przykładzie testów w 64 bitowym środowisku, w którym aplikacje cechują się wyraźnie większą wydajnością. Wprawdzie do wydajnych układów RISC, posiadających zazwyczaj 32 rejestry GPR, jeszcze trochę brakuje, jednak jest to duży krok naprzód, i jak do tej pory, wraz ze 128 bitowymi jednostkami zmiennoprzecinkowymi, ostatni. Szkoda tylko, że wciąż niewykorzystany.
Zjedzona od środka
Architektura RISC okazała się na tyle udana, że nie mogąc w swojej pełnej postaci zastąpić
CISC-owych układów x86, wkradła się w nie od środka. Jednak nie było to wcale łatwe, gdyż wymagało rozwiązania i obejścia licznych problemów, jakie stwarzał architekturze RISC specyficzny i archaiczny standard x86, tworzony z myslą o układach typu CISC.
Z czasem procesory x86 zyskały początkowo architekturę potokową, następnie system predykcji rozgałęzień, później specjalny dekoder instrukcji, wreszcie systemy spekulatywnego wykonywania rozkazów i kilka równoległych potoków i jednostek wykonawczych.
Tym samym ich wnętrze bardzo upodobniło się do układów RISC. Jak się jednak okazało, archaiczny model x86 ograniczał możliwości wewnętrznej, wysoce zaawansowanej części procesora. W celu ich właściwego wykorzystania konieczne stały się dalsze zmiany. Układy x86 zaopatrzono więc w instrukcje SIMD, 128bitowe jednostki zmiennoprzecinkowe, oraz dodatkowe rejestry ogólnego przeznaczenia, a więc to, co prawdziwy RISC miał w standardzie.
Obecnie, każdy współczesny procesor x86 od czasu Pentium Pro i Pentium II, oraz AMD K6, to wewnętrznie wysokowydajny RISC, jednak na skutek konieczności zachowania wstecznej kompatybilności z aplikacjami i standardem x86 - zewnętrznie udający archaiczny układ typu CISC.
Makroinstrukcje kodu x86 nim dotrą do właściwych elementów CPU, odpowiedzialnych za ich wykonywanie, trafiają najpierw do specjalnego dekodera instrukcji, w którym są przekodowywane na mikroinstrukcje wewnętrznego kodu maszynowego procesora. Dopiero te, tak zmienione rozkazy - w swojej budowie przypominające instrukcje, na jakich operują układy RISC, są z kolei przeznaczone do dalszego wykonywania w potokach wykonawczych procesora.
Dodatkowo nad procesem przekodowywania instrukcji czuwa specjalny kompilator, który dokonując na ciągu rozkazów pewnych optymalizacji, zapewnia zachowanie przez przekodowane instrukcje reguł architektury typu RISC.
Proces przekodowywania instrukcji oddziela od siebie dwie sprzeczne ideologie - CISC i RISC, które w układach x86 funkcjonują obok siebie jednocześnie. Zadanie utajnionego pogodzenia CISC i RISC ze sobą powierzone jest właśnie dekoderowi i kompilatorowi instrukcji.
Dzięki nim z zewnątrz procesor widziany jest jako układ CISC w standardowy, szeregowy sposób, za bieżącą kolejnością wykonujący rozkazy x86, podczas gdy wewnętrzna bardzo zaawansowana architektonicznie część procesora, wykonuje już przekodowane rozkazy w sposób niekolejny w kilku równoległych strumieniach, nie mając pojęcia, z jakim kodem tak na prawdę ma do czynienia właściwy procesor.
Zakończenie oraz Słowo od Autora
Podstępne wykorzystanie RISCa do utajnionego, dla zewnętrznego CISCa, wykonywania rozkazów przysporzyło licznych kłopotów, i wymusiło zastosowanie wielu dodatkowych rozwiązań, w znacznym stopniu komplikujących budowę wewnętrzną procesorów. Efektem tej mieszanki jest, wprawdzie znacznie większa, niż w przypadku pierwotnej architektury CISC wydajność układów, jednak wciąż wyraźnie odbiega ona od teoretycznej wydajności wbudowanego w nie wewnętrznego RISCa, i typowych procesorów RISC, do których układy x86 na przestrzeni lat starały się równać.
Dziś można sobie zadać pytanie, po co to wszystko. Czy nie można było jeszcze na przełomie lat 80 i 90, zamiast brnąć dalej, uciec od standardu x86, będącego patologią tej gałęzi techniki, ustalając jednocześnie zupełnie nowy standard, bardziej adekwatny do zupełnie nowych założeń i rozwiązań technicznych?
Jeszcze wówczas, gdy komputery nie były tak liczne i nie stosowane tak powszechnie jak dziś do niemalże wszystkiego, było to możliwe. Teraz nagłe zerwanie z x86 jest zupełnie nie realne, a jego skutki dla świata były by zupełnie nieprzewidywalne. Jedyną szansą jest znalezienie długofalowego rozwiązania przejściowego. Ale to już temat na osobny artykuł.
Słowo od autora.
Dziękuje wszystkim za czas poświecony na przeczytanie tego felietonu. Cenię sobie wszelkie uwagi szanownych Czytelników TwojePC, dlatego będę za nie bardzo wdzięczny. Jest to mój pierwszy artykuł "na łamach" tego portalu, zamierzam napisać ich więcej, stąd wszelkie uwagi będą tym cenniejsze.
Możecie śmiało pisać jakie tematy Was interesują, co się Wam nie podoba, i czy taki nieco literacki styl artykułu może pozostać, czy jednak zmienić go na "suchszy" językowo, lecz bardziej nasączony konkretami?
Jeżeli ktoś poczuł się dotknięty trochę "łopatologicznym" sposobem pisania, bardzo za to przepraszam. Uznałem, że będzie to większym dobrem, niż uproszczenie opisów i objaśnień, mogące prowadzić do nierozumienia problemów.
Ostatni akapit artykułu kierowany jest głównie do Czytelników, posiadających większy zasób wiedzy na poruszone w artykule tematy.
Zadaniem tego artykułu było głównie, w jak najbardziej zrozumiały, prosty i czytelny sposób, przybliżyć Czytelnikowi kwestie w nim poruszane. Stąd też, aby uczynić artykuł bardziej zwięzłym i zrozumiałym, nie przeciągając go w nieskończoność, celowo dokonano pewnych uproszczeń językowych i skrótów.
Przykładem tego niech będą "instrukcje bezpośrednio odwołujące się do pamięci operacyjnej". W rzeczywistości problem ten jest zdecydowanie bardziej skomplikowany, a jego wyjaśnienie byłoby długie i trudniejsze do zrozumienia dla większości Czytelników. Nieco szerzej można napisać, że są to rozkazy, które poprzez adresowanie względne, operują na argumentach pobieranych na ten czas z pamięci operacyjnej. Taki proces wymaga dwukrotnego odwołania do pamięci operacyjnej, po wcześniejszym uzyskaniu adresu fizycznego z jednostki generacji adresów ( AGU ) procesora. Ale to i tak jest dużym uproszczeniem...
Proszę wybaczyć ten nieco uproszczony sposób traktowania wielu problemów, wymagała go specyfika tego artykułu.
|
