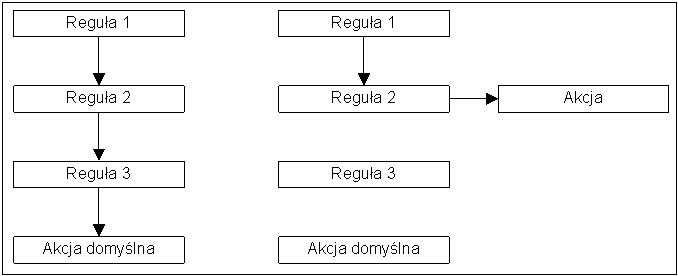
Techinka: Konfiguracja systemu Vyatta w ćwiczeniach
Autor: Łukasz Łaciak | Data: 09/06/11
|
 Wiele osób pragnie rozwiązań dobrych i darmowych, ale rzadko kiedy jest to możliwe. Jednak sieciowy system operacyjny Vyatta (oparty na Linuksie) spełnia oba te warunki, jednocześnie stanowiąc niezłą alternatywę dla drogich routerów (i nie tylko). Choć jest to system dość prosty w konfiguracji, da się dzięki niemu wprowadzić w życie większość rozwiązań potrzebnych do administracji sieciami, nawet tymi sporymi. Zapraszam więc do utrzymanego w konwencji ćwiczeń artykułu, dzięki któremu odkryjesz możliwości oraz sposoby konfiguracji Vyatta w różnych przykładach. (Aktualizacja rozdziałów: 9 czerwca) Wiele osób pragnie rozwiązań dobrych i darmowych, ale rzadko kiedy jest to możliwe. Jednak sieciowy system operacyjny Vyatta (oparty na Linuksie) spełnia oba te warunki, jednocześnie stanowiąc niezłą alternatywę dla drogich routerów (i nie tylko). Choć jest to system dość prosty w konfiguracji, da się dzięki niemu wprowadzić w życie większość rozwiązań potrzebnych do administracji sieciami, nawet tymi sporymi. Zapraszam więc do utrzymanego w konwencji ćwiczeń artykułu, dzięki któremu odkryjesz możliwości oraz sposoby konfiguracji Vyatta w różnych przykładach. (Aktualizacja rozdziałów: 9 czerwca) | |
|
Wstęp
W dzisiejszych czasach ważnym elementem ułatwiającym wymianę informacji, w firmie, szkołach czy w domu, jest sieć, która łączy pojedyncze stanowiska robocze w większe segmenty. Sieć komputerowa jest to grupa komputerów połączonych wspólnym medium, często mających dostęp do Internetu, który jest globalną siecią. Są one budowane w celu udostępnienia innym użytkownikom zasobów oraz różnych usług: zaczynając od drukarki sieciowej, przez serwer poczty elektronicznej, usługi zarządzające pracą tych sieci; po specjalistyczne oprogramowanie pracujące na mocnym serwerze, które umożliwia obliczenia i inne funkcje niedostępne dla zwykłych komputerów w tej sieci.
Jednym z niezbędnych elementów koniecznych do funkcjonowania sieci są routery. Są to urządzenia, kierujące ruch do odpowiednich jej segmentów lub do poszczególnych komputerów. Czasem mają one "wiedzę" o tym jak wygląda cała sieć, chociaż często "wiedzą" tylko, gdzie mają kierować dane, aby osiągnęły konkretny cel. Routery zazwyczaj posiadają kilka interfejsów sieciowych, a ich zadaniem jest szybkie podjęcie decyzji, gdzie przekazać dane. Tańsze konstrukcje posiadają pewne ograniczenia, takie jak ilość interfejsów czy maksymalna przepustowość, a urządzenia profesjonalne, zawierające więcej portów i pozwalające na szybsze przesyłanie informacji są, niestety, bardzo drogie. Tu z pomocą przychodzi Vyatta; system, który może realizować te, a także różne inne zadania będąc zainstalowanym na niedrogim komputerze. Takie rozwiązanie zwie się routerem softwarowym (od software, co z języka angielskiego znaczy oprogramowanie).
Vyatta.
System Vyatta to otwarty, sieciowy system operacyjny, przeznaczony do zarządzania siecią, jej zasobami oraz dostarczający rozwiązań komunikacyjnych. Do głównych zadań tego systemu należy routing, zabezpieczenie sieci przed intruzami oraz zapewnienie ciągłości dostarczania usług, w tym wymagających dużych przepustowości.
Vyatta jest dystrybucją Linuksa opartą na Debianie. Systemy oparte na jądrze Linux są stabilne, jest pisane na nie wiele aplikacji umożliwiających zaawansowane zarządzanie nimi i zadaniami przez nie wykonywanymi, ale przez to są trudne w administrowaniu. Jednak Vyatta posiada konsolę konfiguracyjną podobną do rozwiązania znanego z routerów firmy Juniper (JUNOS), która ułatwia zarządzanie, sprowadzając je do wpisywania odpowiednich poleceń konfiguracyjnych, które budują hierarchiczne drzewo konfiguracji.
W wersji Core, na której będą przeprowadzane ćwiczenia, jest systemem całkowicie darmowym, jednak bez wsparcia technicznego, które zapewniają wersje Subscription Edition oraz Plus
Cel i zakres.
Artykuł ten jest pracą dyplomową autora, w stanie praktycznie oryginalnym. Oprócz zaliczenia studiów celem tej pracy było opracowanie zestawu ćwiczeń laboratoryjnych z zakresu konfiguracji systemu Vyatta, tak, aby zainteresować Czytelnika możliwościami tego systemu poprzez ukazanie sposobów jego konfiguracji w przystępny sposób. Jako, że cel tekstu jest dydaktyczny, więc poszczególne działy będą nadal nazywane ćwiczeniami.
Zakres obejmuje podstawową oraz zaawansowaną obsługę systemu. W skład podstawowej obsługi wchodzi instalacja systemu, przygotowanie do pracy z Internetem, konfiguracja maskarady oraz serwera DHCP, a także wykonanie routingu statycznego. Część zaawansowana, która zostanie opublikowana w kolejnych dwóch częściach - jeśli ta się spodoba czytelnikom - zawiera konfigurację trzech protokołów routingu dynamicznego, tj. OSPF w wersji drugiej, RIP w wersji drugiej i BGP w wersji czwartej oraz konfigurację firewalla, systemu zapobiegania włamaniom (IPS), filtrowania ruchu webowego, QoS, a także rozwiązań zwiększających dostępność takich jak failover i load balancing.
Ćwiczenia.
Opracowane ćwiczenia są konfiguracją systemu Vyatta do wykonywania różnorodnych zadań, a także próbą wyjaśnienia działania przedstawionych rozwiązań i usług. Są one przeznaczone dla osób zainteresowanych tematyką sieci komputerowych, choć niekoniecznie planujących związać swoją przyszłość z zawodem administratora. Chociaż dla wielu osób przedstawione tu informacje są oczywiste, to ćwiczenia są tak napisane, aby każdy Czytelnik, nawet ten niemający zbyt wiele pojęcia o tematyce sieci, dał sobie radę.
Po ukończeniu tych ćwiczeń, Czytelnik będzie posiadał wiedzę wystarczającą do skonfigurowania przedstawionych usług oraz protokołów. Uzupełnieniem będą informacje zawarte w odnośnikach w bibliografii, z którą autor poleca się zapoznać w razie problemów ze zrozumieniem danego zagadnienia.
Autor zakłada przynajmniej podstawową znajomość języka angielskiego przez Czytelnika, gdyż każda osoba chcąca pracować z oprogramowaniem nastawionym na komunikację w tym języku powinna rozumieć komunikaty wyświetlane na ekranie.
Układ.
Przedstawione ćwiczenia podzielone są na kilka części. W każdym zadaniu znajduje się: opis teorii koniecznej do zrozumienia działania danej usługi; topologia sieci, na której będzie przedstawiane jej działanie; konfiguracja sieci wirtualnych, aby połączenia między wirtualnymi maszynami przebiegała prawidłowo; cel wykonywanego ćwiczenia oraz założenia autora w stosunku do Czytelnika; oraz konfiguracja danej usługi, często na kilka sposobów działania. W niektórych, bardziej rozwiniętych ćwiczeniach, dane części występują kilkakrotnie.
Od autora: jest to moja pierwsza praca na taką skalę, a przy tym nie mam zbyt wiele praktyki w administracji, więc proszę o trochę wyrozumiałości. Przy tworzeniu tego tekstu bazowałem na źródłach internetowych (w tym producenta) oraz na własnym rozumowaniu. Proszę także o zgłaszanie wszelkich błędów (rzeczowych, stylistycznych, w rozumowaniu, czy jakichkolwiek innych) do mnie - w miarę możliwości będą one poprawiane. Po trochę przydługim wstępie, zapraszam do lektury.
1. Instalacja.
Najpierw należy utworzyć maszynę wirtualną, na której zagości system. Przy jej tworzeniu należy ustalić ilość pamięci na 256 MB, a wielkość dysku na 1 GB oraz wskazać płytę z obrazem ISO systemu Vyatta. Połączenie sieciowe powinno zostać takie jak domyślnie zaznaczone (NAT). Instalowana wersja to 6.0 Core.
Na potrzeby ćwiczeń wystarczy tak mała ilość pamięci i przestrzeni dyskowej oraz standardowy procesor, jednak do poważniejszych zastosowań, z większą ilością interfejsów, dużą tablicą routingu oraz kilkoma protokołami trasowania potrzebny może być procesor posiadający od 2 do 8 rdzeni, nawet 4 GB pamięci RAM oraz tyle samo miejsca na dysku.
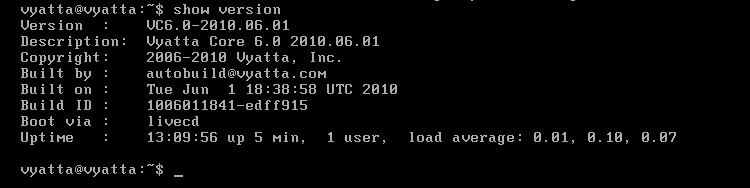
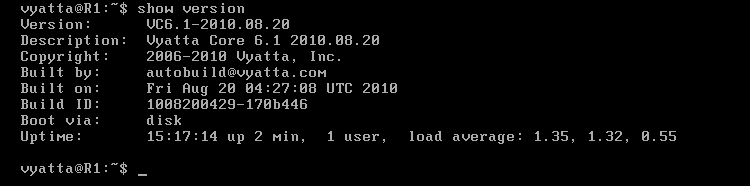
Po włączeniu, system będzie działał jako Live CD, czyli będzie uruchomiony z płyty (wirtualnej) i będzie rezydował w pamięci RAM [Obraz 1-1], a zatem zapisywane zmiany będą się ulatniać. Zarówno login jak i hasło to 'vyatta'.
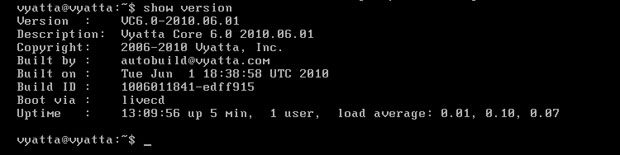
Obraz 1-1: Podsumowanie wersji
Na powyższym obrazie widać efekt działania polecenia 'show version', które informuje m. in. o dokładnej wersji systemu oraz o trybie uruchamiania.
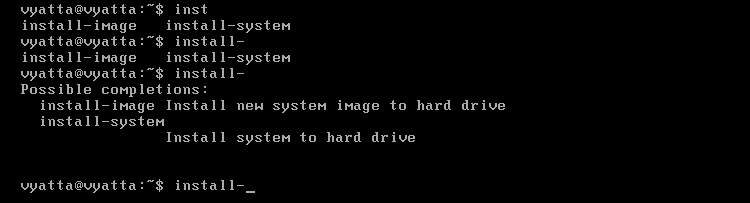
Aby zainstalować system na dysku należy wpisać polecenie 'install-system', a następnie potwierdzić klawiszem enter. Przy wpisywaniu polecenia można, a wręcz należy, posiłkować się tabulatorem. Pozwala on na uzupełnienie polecenia, jeśli jest jednoznaczne, a jeżeli istnieje więcej niż jedno dokończenie, system Vyatta wyświetli listę możliwych opcji [Obraz 1-2]. Po dwukrotnym wciśnięciu tabulatora lista zostanie rozszerzona o krótki opis.
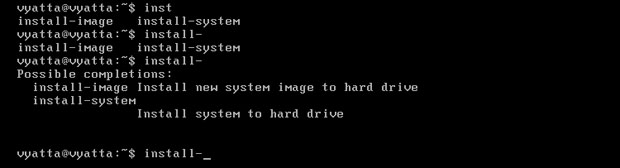
Obraz 1-2: Uzupełnianie polecenia tabulatorem
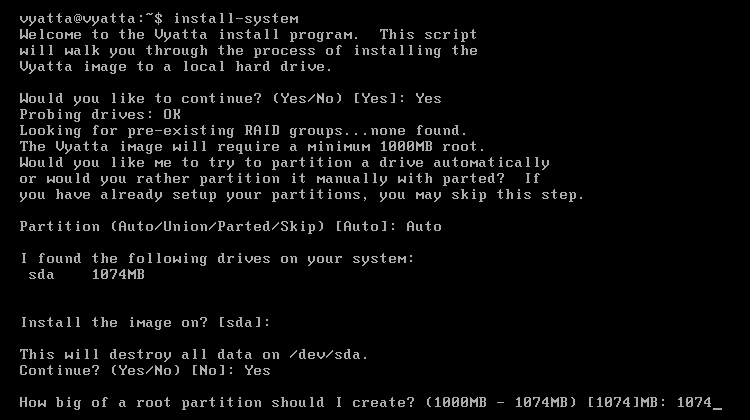
Po zatwierdzeniu polecenia instalator zapyta czy kontynuować; należy potwierdzić, a więc wpisać 'Yes'. Następnie zapyta o partycjonowanie, a że nie będzie to miało większego znaczenia, należy wpisać 'Auto'. Później system znajdzie dysk sda, co należy potwierdzić klawiszem enter, a następnie znowu potwierdzić pytanie o kontynuację. Na koniec należy ustalić rozmiar partycji na maksymalny i nacisnąć enter, a system rozpocznie instalację [Obraz 1-3].
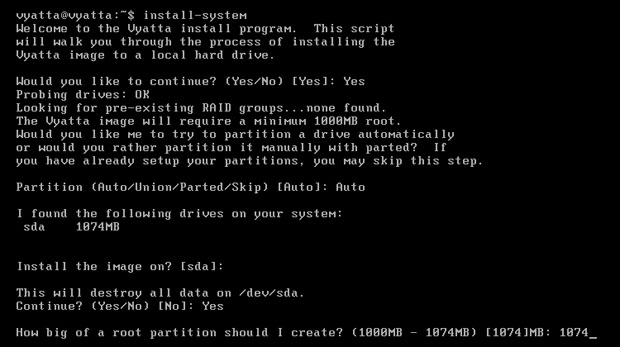
Obraz 1-3: Instalacja systemu Vyatta
Po chwili system znajdzie plik konfiguracyjny, co należy potwierdzić. Trzeba będzie jeszcze wpisać nowe hasło oraz potwierdzić enterem modyfikację części rozruchowej partycji.
Po tych wszystkich pytaniach i komunikatach operacja zostanie zakończona, a żeby uruchomić system z dysku należy jeszcze go zrestartować poleceniem 'reboot' i potwierdzić klawiszem enter.
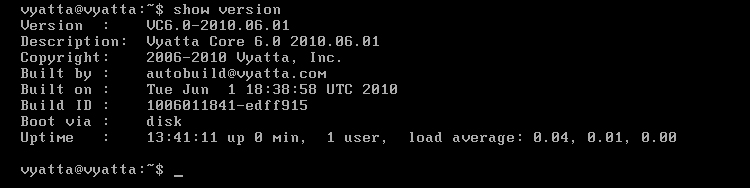
Po restarcie polecenie 'show version' powinno pokazać uruchomienie z dysku [Obraz 1-4].
Obraz 1-4: Podsumowanie wersji
Instalacja została ukończona. W celu przygotowania do kolejnych ćwiczeń należy wyłączyć system (polecenie 'shutdown') oraz skopiować go cztery razy, aby uzyskać pięć kopii, które można różnie nazwać.
2. Początkowa konfiguracja - omówienie.
Po uzyskaniu 5 osobnych maszyn wirtualnych, należy je załadować do programu VMware Workstation poleceniem "File/Open" oraz zmienić nazwy wedle uznania. Przy uruchamianiu maszyn, wyskoczy okienko, w którym należy zaznaczyć opcję "I copied it". Gdyby została zaznaczona druga propozycja, wystąpiłyby konflikty adresów MAC.
Przed przystąpieniem do działania konieczne będzie zapoznanie się z kilkoma zasadami postępowania oraz poleceniami systemu Vyatta:
- Aby przejąć kontrolę nad maszyną wirtualną trzeba na nią kliknąć; aby się uwolnić należy wcisnąć klawisze "CTRL + ALT".
- W systemie Vyatta istnieją dwa tryby: operacyjny i konfiguracyjny. Pierwszy z nich służy do wyświetlania informacji, statusów, czyszczenia cache rozmaitych usług i innych zadań koniecznych do określenia działania systemu. Natomiast drugi tryb służy do tworzenia, usuwania i modyfikowania konfiguracji oraz do jej wyświetlania.
- Po naciśnięciu klawisza tabulatora pokaże się lista poleceń możliwych do wykonania w danym trybie. W trybie operacyjnym najbardziej będzie przydatne polecenie 'show' oraz 'configure', którym to uzyskuje się dostęp do trybu konfiguracyjnego. Natomiast w trybie konfiguracyjnym najistotniejsze będą:
- 'show' - używane w celu wyświetlenia konfiguracji,
- 'set' - służące do tworzenia konfiguracji,
- 'edit' - przenosi do podanej gałęzi drzewa konfiguracji,
- 'delete' - służące do usuwania,
- 'commit' - służące do zapisywania zmian drzewa konfiguracji,
- 'discard' - używane do odrzucania zmian,
- 'exit' - służący do opuszczania trybu konfiguracji lub do powrotu do korzenia z gałęzi drzewa,
- 'save' - używane do zapisywania konfiguracji do pliku,
- 'load' - służące do wczytywania konfiguracji z pliku.
Będąc w trybie konfiguracyjnym, ponad nazwą konta użytkownika i maszyny widnieje napis "[edit]" lub "[edit gałąź]", gdzie gałąź, to nazwa aktualnie edytowanej gałęzi drzewa konfiguracji.
- Gdy wyświetlana jest konfiguracja, status lub coś innego kończącego się osobną linią ze znakiem dwukropka, oznacza to, że tekst wychodzi poza ekran i można nim sterować za pomocą klawiszy:
- strzałki - przesuwanie odpowiada kierunkom wskazywanym przez groty,
- enter - przesuwanie o linię w dół,
- spacja - przesuwanie o ekran w dół,
- "Q" - wyjście z trybu przesuwania.
- Domyślny użytkownik - vyatta, nie posiada praw superużytkownika root, więc aby wykonać niektóre polecenia wymagające tych uprawnień będzie używany program Sudo. Można używać konta użytkownika root, ale bezpieczniej jest tego nie robić.
- Do przerywania działania programów służy kombinacja klawiszy "CTRL + C".
- W celu nawigacji między wpisanymi poleceniami należy użyć klawiszy strzałek.
2.1. Założenia i cele.
Celem niniejszego ćwiczenia jest skonfigurowanie pięciu wirtualnych maszyn, aby miały dostęp do Internetu oraz konfiguracja dat i serwerów czasu na nich, a także zmiana nazw komputerów i haseł.
Do wykonania zadania niezbędna będzie podstawowa wiedza z zakresu konfiguracji sieci LAN oraz znajomość pojęć z nią związanych. Mogą także przydać się umiejętności poruszania się po systemach Linuksowych, a przynajmniej podstawowa znajomość języka angielskiego będzie ułatwiała zrozumienie wykonywanych poleceń.
2.2. Konfiguracja.
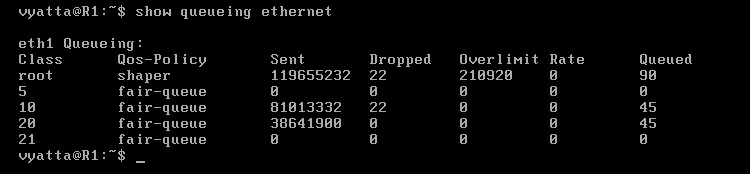
Na sam początek należy wyeliminować problem adresacji MAC powstały przy kopiowaniu maszyn wirtualnych. Po powieleniu maszyn, interfejs eth0 na każdej z nich został usunięty, prawdopodobnie przez konflikt adresów MAC. Na jego miejsce został dodany interfejs o kolejnym numerze z nowym adresem. W celu przywrócenia interfejsu eth0, na każdej z maszyn wystarczy go usunąć, zapisać zmiany i zrestartować system. Po ponownym uruchomieniu wczytana zostanie zapisana konfiguracja (zmiany zapisane poleceniem 'save plik', nie są automatycznie wczytywane i do wczytania trzeba użyć polecenia 'load plik'), interfejs eth1 nie będzie skonfigurowany, a eth0 stanie się dostępny do konfiguracji poleceniem 'set'. Na obrazie 2-1 pokazana jest część drzewa konfiguracji, dotycząca interfejsów, wywołana poleceniem 'show interfaces'.

Obraz 2-1: Konfiguracja interfejsów
Składnia użytych poleceń:
- 'delete interfaces ethernet <interfejs>' - usuwa podany interfejs z drzewa konfiguracji.
R2, R3, R4, Host:
configure
delete interfaces ethernet eth1
commit
save
exit
Każda zmiana konfiguracji przedstawiona w niniejszej publikacji będzie posiadała powyższą formę, tj. najpierw będzie omawiana składnia nowych poleceń, a następnie pogrubioną czcionką będą wypisane polecenia, kolejno wprowadzane do komputerów wypisanych ponad poziomą linią. Jako, że polecenia trybu konfiguracyjnego zostały już opisane, więc w kolejnej konfiguracji ich nie będzie, z wyjątkiem polecenia 'commit' oraz 'save' . 'Commit' będzie pozostawiane w celu przypomnienia o zapisaniu zmian, a 'save' pojawi się tylko w przypadku konieczności, która zostanie omówiona. Dodatkowo, gdy polecenia będą wykonywane w trybie konfiguracyjnym lub tryb będzie obojętny, nie będzie wspomniane jaki to tryb. W razie pomylenia trybu przy wprowadzaniu poleceń, w wielu przypadkach nie będzie działało uzupełnianie lub zostanie wyświetlony błąd.
Po usunięciu z konfiguracji interfejsu eth1 i wyjściu do trybu operacyjnego należy zrestartować system poleceniem 'reboot', a następnie skonfigurować interfejs eth0 na każdym komputerze do dostępu do Internetu. Oczywiście konieczne jest ustawienie karty sieciowej w tryb NAT i sprawdzenie adresu sieci łączącej z komputerem fizycznym. W WMvare Workstation trzeba kliknąć w menu "Edit/Virtual Network Editor", zaznaczyć kartę z połączeniem NAT (prawdopodobnie VMnet8) i odczytać na dole wartości "Subnet IP" oraz "Subnet mask". Są to adresy: sieci oraz jej maska.
Składnia użytych poleceń:
- 'set interfaces ethernet <interfejs> address <adres IP/maska>' - dopisuje podany adres i maskę do danego interfejsu.
- 'set system gateway-address <adres IP>' - ustawia bramę domyślną na podany adres.
- 'set system name-server <adres IP>' - ustawia serwer DNS na podany adres.
R1:
set interfaces ethernet eth0 address 192.168.223.3/24
R2:
set interfaces ethernet eth0 address 192.168.223.4/24
R3:
set interfaces ethernet eth0 address 192.168.223.5/24
R4:
set interfaces ethernet eth0 address 192.168.223.6/24
Host:
set interfaces ethernet eth0 address 192.168.223.7/24
R1, R2, R3, R4, Host:
set system gateway-address 192.168.223.2
set system name-server 8.8.8.8
set system name-server 8.8.4.4
commit
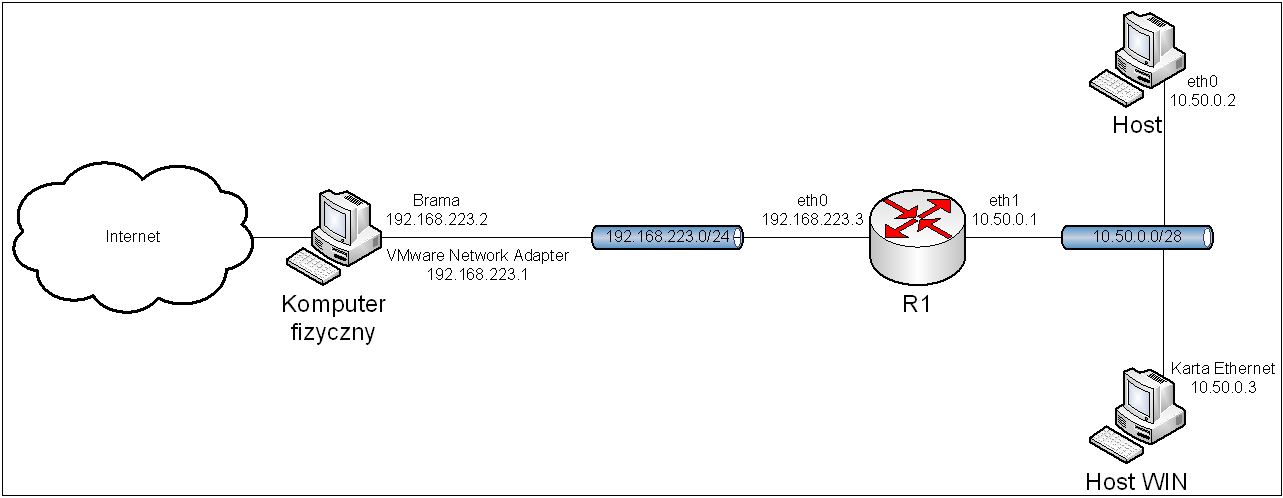
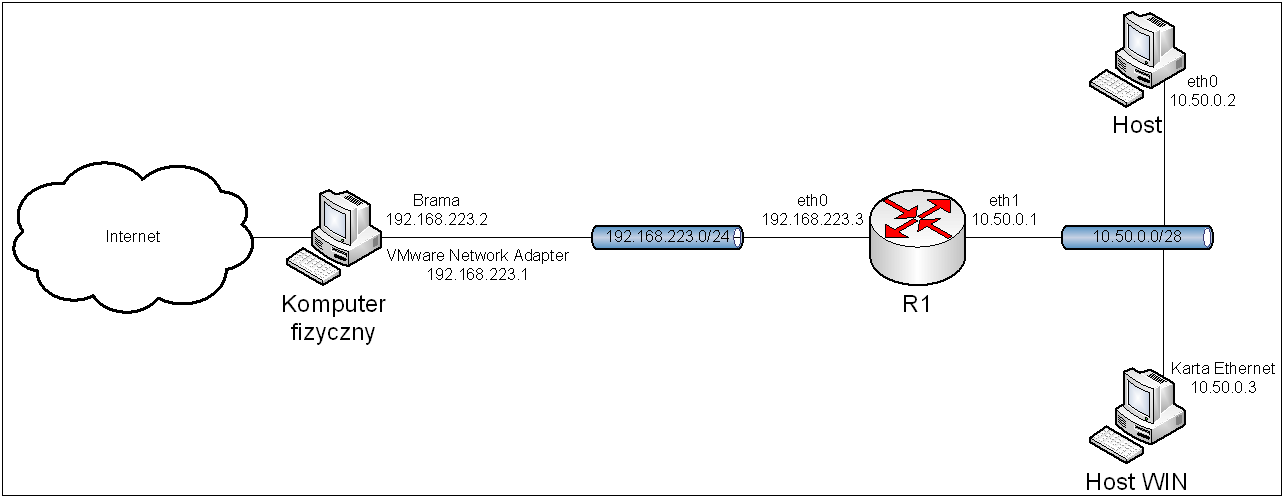
Po wykonaniu powyższych poleceń, komputery będą miały dostęp do Internetu, zgodnie z topologią przedstawioną na obrazie 2-2. Adresy serwerów DNS będą ustawione na serwery dostarczane przez Google. Brama domyślna ma adres 192.168.223.2, a 192.168.223.1 jest adresem karty w komputerze fizycznym.
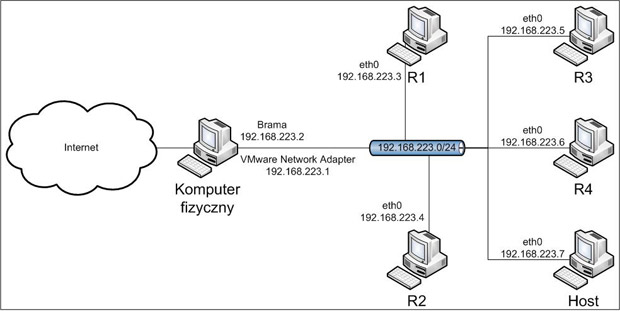
Obraz 2-2: Topologia powstała po konfiguracji interfejsów sieciowych
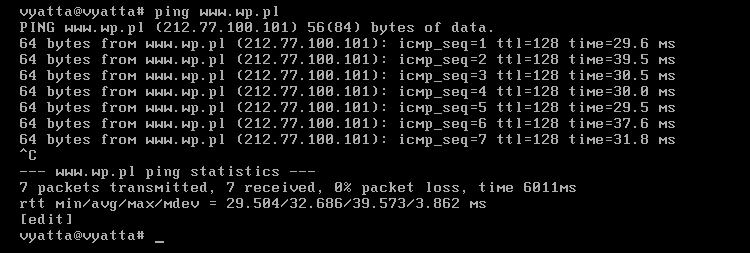
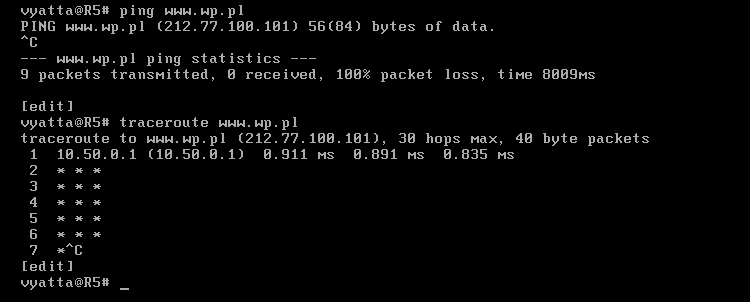
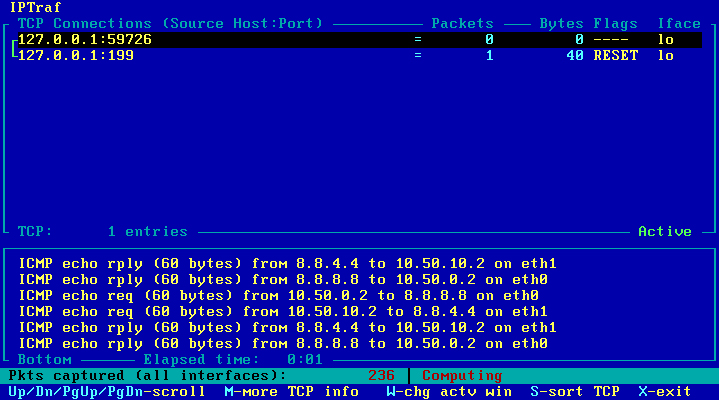
Dla pewności, na każdym z komputerów, programem Ping można sprawdzić czy rzeczywiście jest dostęp do Internetu i czy serwery DNS działają prawidłowo. Na obrazie 2-3 zaprezentowane jest jego działanie. Został uruchomiony poleceniem 'ping www.wp.pl' z komputera R1.
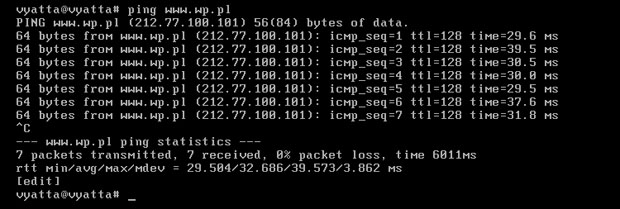
Obraz 2-3: Efekt działania programu Ping
Jak widać na powyższym obrazie, komputer jak i użytkownik nazywa się "vyatta", co widać w linii poleceń: "vyatta@vyatta". Czas to zmienić.
Składnia użytych poleceń:
- 'set system host-name <nazwa>' -ustanawia nazwę komputera.
R1:
set system host-name R1
commit
R2:
set system host-name R2
commit
R3:
set system host-name R3
commit
R4:
set system host-name R4
commit
Host:
set system host-name Host
commit
Drzewo konfiguracji się zmieni, ale nazwa jeszcze nie będzie widoczna, ponieważ trzeba się wylogować i zalogować ponownie. Aby to uczynić, należy wyjść z trybu konfiguracyjnego i ponownie wpisać 'exit', a następnie się zalogować. Na każdym komputerze powinna się zmienić nazwa, np.: na R1 będzie "vyatta@R1", co znaczy, że na maszynie R1 jest zalogowany użytkownik "vyatta".
W obu trybach, konfiguracyjnym oraz operacyjnym polecenie 'date' wyświetla bieżący czas oraz datę. Jednak prawdopodobnie będzie ona nieprawidłowa. Ale jeszcze przed ustaleniem daty, trzeba określić strefę czasową, co pokazuje poniższy przykład.
Składnia użytych poleceń:
- 'set date <data w formacie MMDDggmmRR>' -ustawia datę.
R1, R2, R3, R4, Host:
set system time-zone Europe/Warsaw
commit
Aby ustawić datę należy wpisać poniższe polecenie w trybie operacyjnym.
Składnia użytych poleceń:
- 'set date <data w formacie MMDDggmmRR>' -ustawia datę.
R1, R2, R3, R4, Host:
set date 1109131610
Ale kto będzie pilnował poprawności tej daty? Nikt. Dlatego lepszym wyborem będzie ustawienie serwera czasu, z którym data i czas będą automatycznie synchronizowane.
Składnia użytych poleceń:
- 'set system ntp-server <adres>' -ustawia serwer czasu.
R1, R2, R3, R4, Host:
set system ntp-server tempus1.gum.gov.pl
commit
Czas oraz data powinny być już synchronizowane z podanym serwerem. Powyższy adres odnosi się do atomowego zegara cezowego 5071A z Głównego Urzędu Miar.
Każdy z użytkowników zapewne będzie chciał zmienić hasło na takie, jakiego nikt nie zna. Poniżej znajduje się polecenie umożliwiające wykonanie zmiany.
R1, R2, R3, R4, Host:
set system login user vyatta authentication plaintext-password vyatta
commit
2.3. Aktualizacja
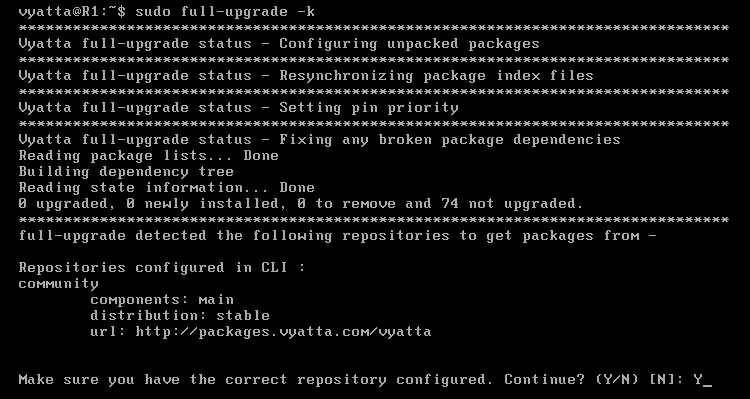
Aby zaktualizować system do najnowszej dostępnej wersji, na każdym z komputerów należy wpisać polecenie 'sudo full-upgrade -k', po czym system ją rozpocznie.
Od razu instalator zapyta o poprawność adresu z którego ma pobrać repozytorium [Obraz 2-4]. Należy potwierdzić wpisując 'Y'. Jeśli jednak adres okazałby się nieprawidłowy, będzie trzeba poszukać nowego na stronie domowej systemu Vyatta, tj. www.vyatta.com.
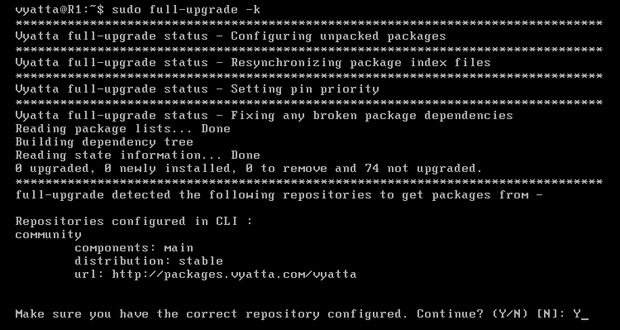
Obraz 2-4: Rozpoczęcie aktualizacji
Aktualizacja potrwa chwilę - zależnie od wydajności komputera fizycznego oraz od szybkości łącza i serwerów udostępniających pliki do aktualizacji. Po zakończeniu można sprawdzić wersję systemu poleceniem 'show version' w trybie operacyjnym [Obraz 2-5].
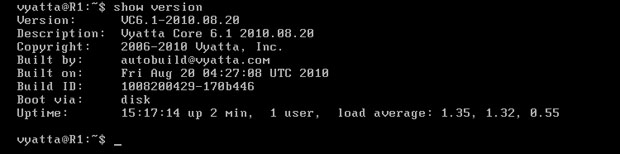
Obraz 2-5: Wersja systemu
Po aktualizacji wersja systemu to 6.1. Na tej wersji będzie przedstawiona reszta ćwiczeń.
Dobrze będzie zapisać na każdym komputerze zmiany poleceniem 'save', aby w razie ponownego uruchomienia zostały zachowane. Jak widać, system konfiguracji jest dość prosty oraz przejrzysty, więc nikomu nie powinien sprawiać problemów.
3. Maskarada.
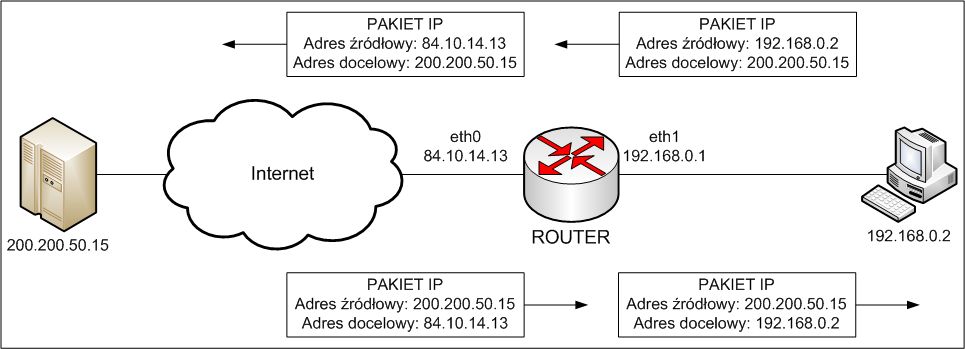
Maskarada jest szczególnym przypadkiem mechanizmu tłumaczenia adresów sieciowych (ang. Network Address Translation, NAT), gdyż używana jest w środowiskach, gdzie IP interfejsu wychodzącego w stronę Internetu jest zmienne.
Mając sieć prywatną, która uzyskuje dostęp przez jeden komputer-router, komputery wewnątrz niej nie mają pełnego kontaktu z Internetem, ponieważ pakiety powracające do nich gubią się, dlatego, że w nagłówku IP noszą adresy nieznane komputerom spoza sieci. Dla odległego komputera adres 192.168.0.2 może być adresem w jego sieci, i to tam skieruje odpowiedź, zamiast odesłać do komputera, skąd pochodzi. Aby były osiągalne, router musi zmieniać adresy pochodzenia (źródłowe) pakietów, podstawiając w miejsce adresów komputerów, swój własny adres. W ten sposób, komputery odpowiadające na zapytania maszyn z sieci prywatnej wiedzą, do którego routera mają skierować odpowiedź, a on z powrotem podmienia adres w nagłówku IP, tym razem docelowy, ze swojego na adresy komputerów w sieci prywatnej.
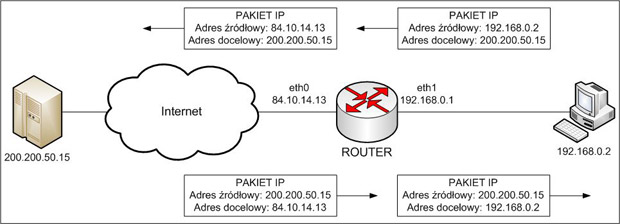
Obraz 3-1: Schemat działania maskarady
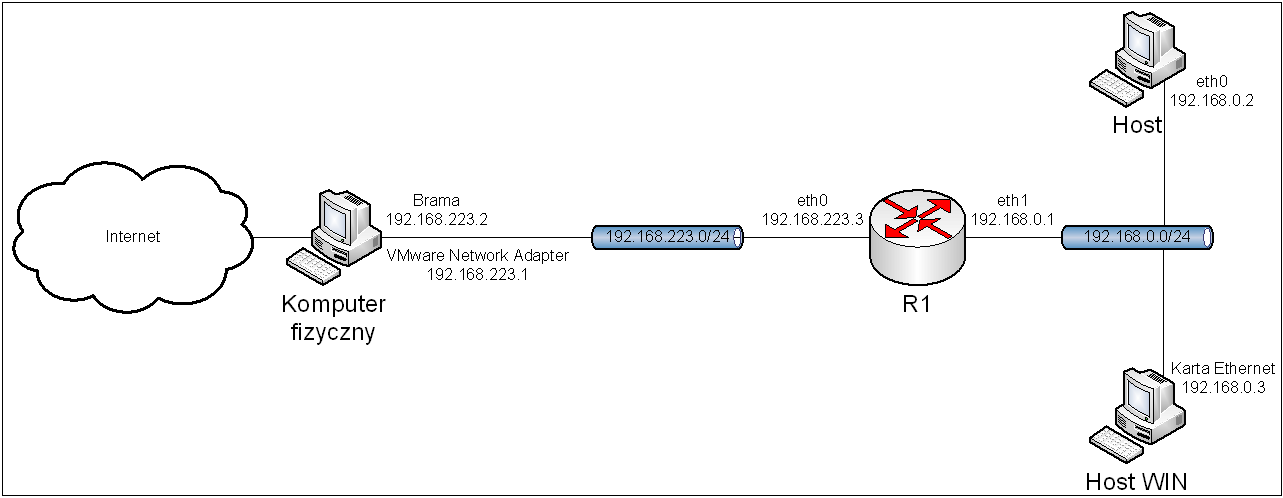
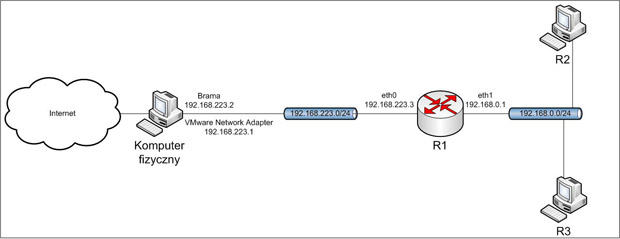
3.1. Topologia.
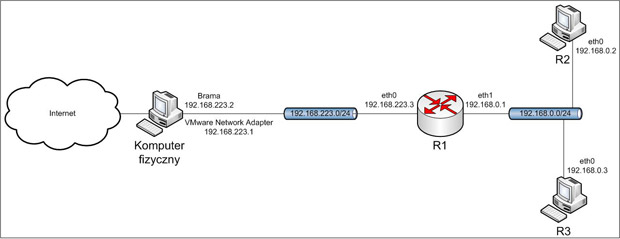
Obraz 3-1: Topologia sieci użytej w zadaniu
3.2. Przygotowanie wirtualnych sieci.
Przed uruchomieniem wirtualnych maszyn konieczne jest ustawienie ilości interfejsów sieciowych oraz sieci, z którymi będą się one łączyć. Poniżej są one wypisane dla komputerów, które będą uczestniczyć w ćwiczeniu.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
R2:
eth0 - VMnet2
R3:
eth0 - VMnet2
3.3. Cel oraz założenia.
Celem bieżącego ćwiczenia jest zapoznanie się z mechanizmem maskarady oraz konfiguracja prostej sieci.
Przydatna będzie znajomość nagłówka pakietu IP. Przed przystąpieniem do zadania zalecane jest zapoznanie się z ćwiczeniem "2. Początkowa konfiguracja i aktualizacja".
3.4. Konfiguracja.
Interfejs eth0 komputera R1oraz jego brama domyślna pozostają w niezmienionej formie, tj. są skonfigurowane tak samo jak w ćwiczeniu "2. Początkowa konfiguracja i aktualizacja". Natomiast jego interfejs eth1 będzie skonfigurowany do udostępniania połączenia innym komputerom, których interfejsy też zmienią konfigurację. Przy zmianie adresów interfejsów trzeba najpierw usunąć stary adres, ponieważ nie zostanie on zastąpiony przez nowy, tylko dodany jako drugi, przez co mogą występować konflikty. W każdej chwili można sprawdzić adres interfejsu poleceniem 'show', a dokładniej 'show interfaces'.
R1:
set interfaces ethernet eth1 address 192.168.0.1/24
commit
R2:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.2/24
set system gateway-address 192.168.0.1
commit
R3:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.3/24
set system gateway-address 192.168.0.1
commit
Komputery będą mieć już łączność ze sobą, co można sprawdzić programem Ping. Maszyna R1 będzie miała dostęp do Internetu, ale pozostałe dwa nie, co widać na obrazie 3-2.

Obraz 3-2: Polecenie 'ping 212.77.100.101' wykonane z komputera R3. Brak odpowiedzi
Pakiety wysyłane przez komputer R3 co prawda dochodzą do celu, jednak już nie wracają do niego, ponieważ ma on adres z puli prywatnej, nieznanej odpytywanemu komputerowi. On po prostu nie wie gdzie jest maszyna R3. Aby temu zapobiec, na interfejsie eth0 komputera R1 musi zostać skonfigurowana maskarada.
Składnia użytych poleceń:
- 'set service nat rule < numer> source address < adres sieci/maska>' -definiuje adres źródłowy (sieci), która ma być ukryta za maskaradą, dla reguły o podanym numerze.
- 'set service nat rule < numer> outbound-interface < interfejs>' -określa interfejs, na którym ma być dokonana translacja adresów.
- 'set service nat rule < numer> type masquerade' -określa typ NATa.
R1:
set service nat rule 1 source address 0.0.0.0/0
set service nat rule 1 outbound-interface eth0
set service nat rule 1 type masquerade
commit
Po powyższych zabiegach wszystkie komputery podłączone do R1 będą miały już kontakt ze światem zewnętrznym, nawet jakby były z innych sieci, ponieważ adres 0.0.0.0/0 znaczy tyle co każdy adres na każdej masce. Na obrazie 3-3 pokazany jest wynik polecenia 'ping 212.77.100.101' wykonanego z komputera R3.
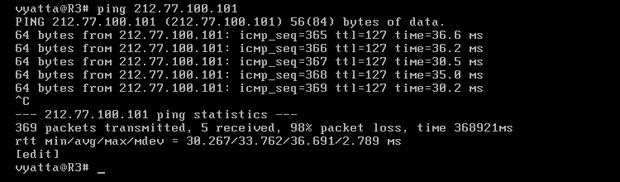
Obraz 3-3: Odpytywany adres zaczął odpowiadać
Tak jak w poprzednim ćwiczeniu, dobrze jest zapisać zmiany poleceniem 'save' do tego samego pliku (nadpisać go) lub wpisać 'save plik", aby zapisać do innego pliku. Można tą konfigurację potraktować jako pewną bazę, która przyda się do następnych ćwiczeń.
4. DHCP.
Dynamic Host Configuration Protocol jest protokołem umożliwiającym automatyczną dystrybucję danych konfiguracyjnych do komputerów w sieci. DHCP rozpowszechnia między innymi adresy IP, maskę podsieci, bramę domyślną oraz adres serwera DNS. Został opisany w dokumencie RFC 2131.
DHCP posługuje się kilkoma komunikatami:
- DHCPDISCOVER - żądanie broadcastowe (do wszystkich w sieci) używane w celu wyszukania dostępnych serwerów DHCP.
- DHCPOFFER - oferta konfiguracji przesyłana od serwera do klienta na żądanie DHCPDISCOVER.
- DHCPREQUEST - zatwierdzenie oferty serwera z podanymi parametrami lub przedłużenie dzierżawy.
- DHCPACK - paczka od serwera zawierająca uzgodnione parametry.
- DHCPNAK - odmowa przydzielenia parametrów (np.: klient nie należy już do sieci lub dostał dane konfiguracyjne od innego serwera).
- DHCPDECLINE - klient do serwera z wiadomością, że adres jest już w użyciu.
- DHCPRELEASE - zrzeczenie się dzierżawy przez klienta.
- DHCPINFORM - prośba klienta o parametry, lecz bez adresu IP.
Wymieniając się powyższymi komunikatami, serwery przydzielają klientom wszystkie niezbędne do połączenia z Internetem dane.
4.1. Topologia.
Obraz 4-1: Topologia sieci użytej w zadaniu
4.2. Przygotowanie wirtualnych sieci.
Jako, że topologia jest identyczna jak w ćwiczeniu "3. Maskarada", więc wirtualne sieci będą również tak samo skonfigurowane.
4.3. Cel oraz założenia.
Celem niniejszego ćwiczenia jest zapoznanie się protokołem DHCP i wdrożenie jego konfiguracji, łącznie ze statycznym mapowaniem adresów.
4.4. Konfiguracja.
Wejściową konfiguracją będzie ta z ćwiczenia poprzedniego, tj. "3. Maskarada", wczytana poleceniem 'load'. Będzie ona tylko modyfikowana w calu dynamicznego przydziału adresów.
Najpierw na komputerach R2 i R3 należy usunąć adres interfejsu sieciowego, bramę domyślną oraz adres serwera DNS.
R1, R2:
delete interfaces ethernet eth0 address
delete system gateway-address
delete system name-server
commit
Na komputerze R1 musi zostać włączony serwer DHCP, który będzie dynamicznie przydzielał adresy z pewnej, ustalonej puli. Będzie rozsyłał także adres bramy domyślnej oraz serwera DNS.
Składnia użytych poleceń:
- 'set service dhcp-server shared-network-name SIEC subnet <adres sieci/maska> start <adres IP> stop <adres IP>' -definiuje adres pule adresów dla danej sieci. Pula jest określona dwoma adresami - początkowym i końcowym.
- 'set service dhcp-server shared-network-name SIEC subnet <adres sieci/maska> default-router <adres IP>' -określa adres bramy domyślnej, który będzie rozsyłany klientom.
- 'set service dhcp-server shared-network-name SIEC subnet <adres sieci/maska> dns-server <adres IP>' -definiuje adres serwera DNS, który będzie rozsyłany klientom.
R1:
set service dhcp-server shared-network-name siec1 subnet 192.168.0.0/24 start 192.168.0.2 stop 192.168.0.100
set service dhcp-server shared-network-name siec1 subnet 192.168.0.0/24 default-router 192.168.0.1
set service dhcp-server shared-network-name siec1 subnet 192.168.0.0/24 dns-server 8.8.8.8
commit
Na koniec należy ustawić komputery R2 i R3, aby zaczęły korzystać z serwera.
R1, R2:
set interfaces ethernet eth0 address dhcp
commit
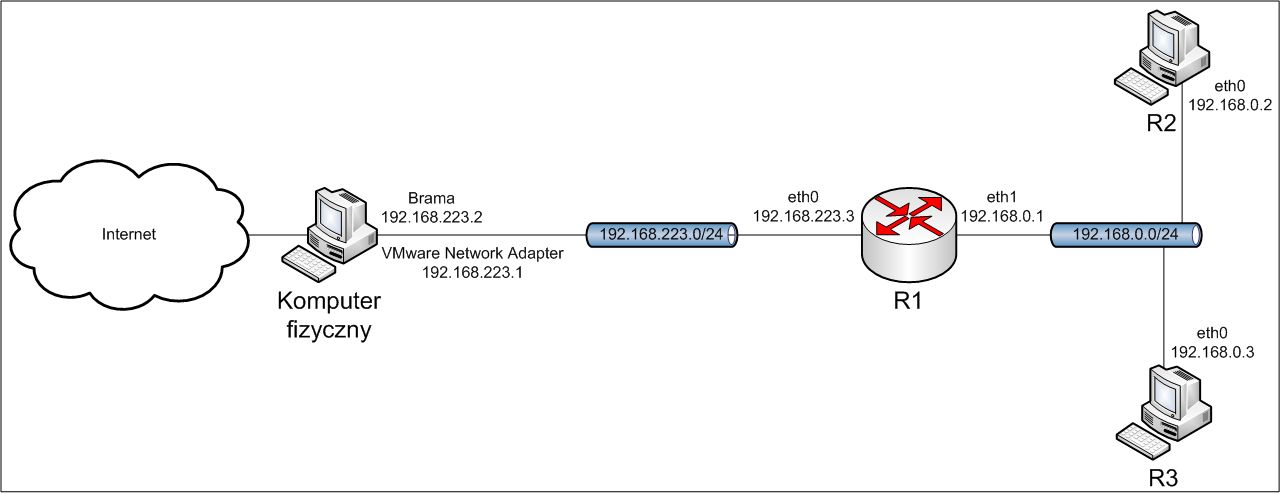
Poleceniem 'show dhcp leases' w trybie operacyjnym można wyświetlić dzierżawy adresów dla poszczególnych komputerów [Obraz 4-2]. Dzierżawy domyślnie wygasają po 24 godzinach.
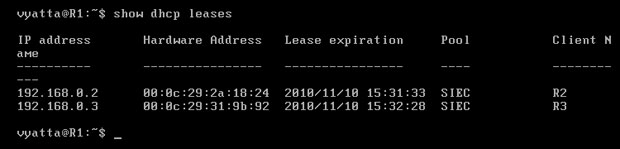
Obraz 4-2: Adresy dzierżawione przez serwer DHCP działający na maszynie R1
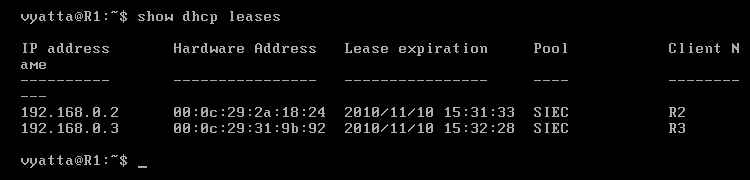
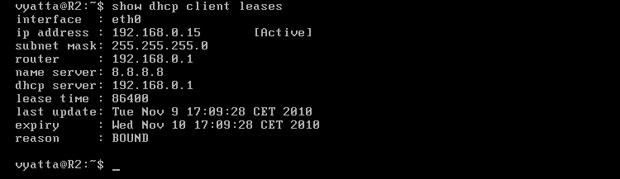
Każdy klient osobno może zobaczyć cechy swojej dzierżawy, m. in.: adres, maskę podsieci, adres routera będącego bramą domyślną oraz adres serwera DHCP [Obraz 4-3].
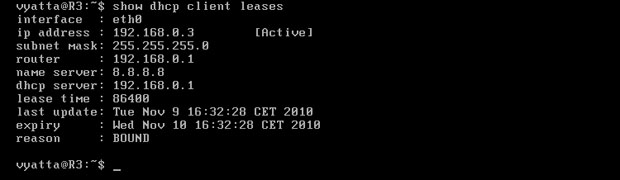
Obraz 4-3: Cechy dzierżawy na komputerze R3
Może zaistnieć potrzeba, abv serwer DHCP za każdym razem przypisywał określonemu urządzeniu ten sam adres IP (np. drukarce sieciowej). Można to osiągnąć dzięki statycznemu mapowaniu adresów. Poniższe polecenia sprawią, że komputer R2 będzie miał stały adres IP.
Składnia użytych poleceń:
- 'set service dhcp-server shared-network-name SIEC subnet <adres sieci/maska> static-mapping <nazwa> ip-address <adres IP>' -określa adres, który będzie przydzielany.
- 'set service dhcp-server shared-network-name SIEC subnet <adres sieci/maska> static-mapping <nazwa> mac-address <adres MAC>' -definiuje urządzenie, któremu będzie przydzielany adres z poprzedniego polecenia.
R1:
set service dhcp-server shared-network-name siec1 subnet 192.168.0.0/24 static-mapping MAPA ip-address 192.168.0.15
set service dhcp-server shared-network-name siec1 subnet 192.168.0.0/24 static-mapping MAPA mac-address 00:0c:29:2a:18:24
commit
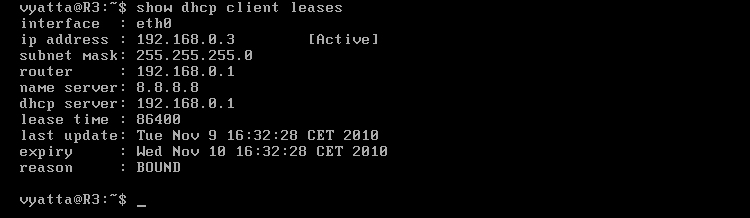
Po upłynięciu poprzedniej dzierżawy, maszyna R2, o adresie MAC 00:0c:29:2a:18:24, będzie miała przyznawany adres IP 192.168.0.15. Można także wymusić odnowienie dzierżawy, w trybie operacyjnym wpisując polecenie 'renew dhcp interface eth0' na komputerze R2 [Obraz 4-4].
Obraz 4-4: Dzierżawa z nowym adresem na komputerze R2
Jak widać, konfiguracja DHCP jest szybka i prosta. Trzeba tylko uważać, by nie popełnić błędu, ponieważ w razie niepoprawnej konfiguracji, cała sieć może zostać odcięta od Internetu.
5. Routing statyczny.
Routing, czyli trasowanie, jest procesem pozwalającym na przesyłanie informacji w sieciach składających się z wielu węzłów, zwanych routerami. W pakietach wysyłanych z komputera-nadawcy określony jest adres docelowy, który jest analizowany przez każdy router po drodze i przypasowywany do tablic routingu, w których powinna znajdować się informacja, którym interfejsem przesyłać pakiety, aby trafił do celu.
Trasowanie statyczne polega na ręcznym ustalaniu możliwych ścieżek do sąsiednich sieci i dopisywaniu ich do tablic routingu. Przy trasowaniu statycznym nie ma konieczności wymiany informacji o stanach łącz między routerami, jak ma to miejsce w przypadku protokołów routingu dynamicznego, więc jest to proces niezależny na każdym z routerów.
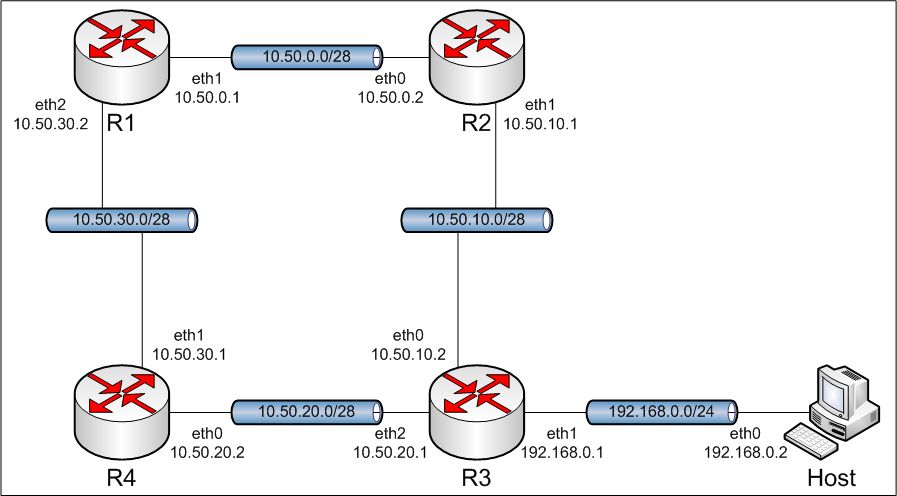
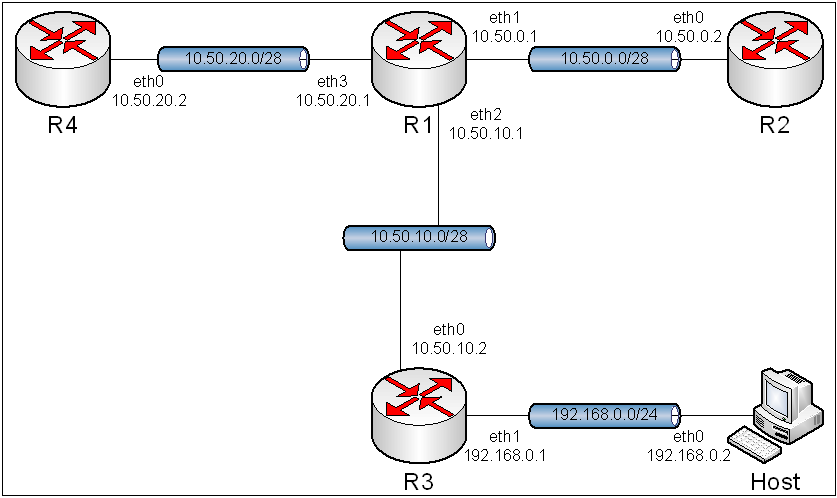
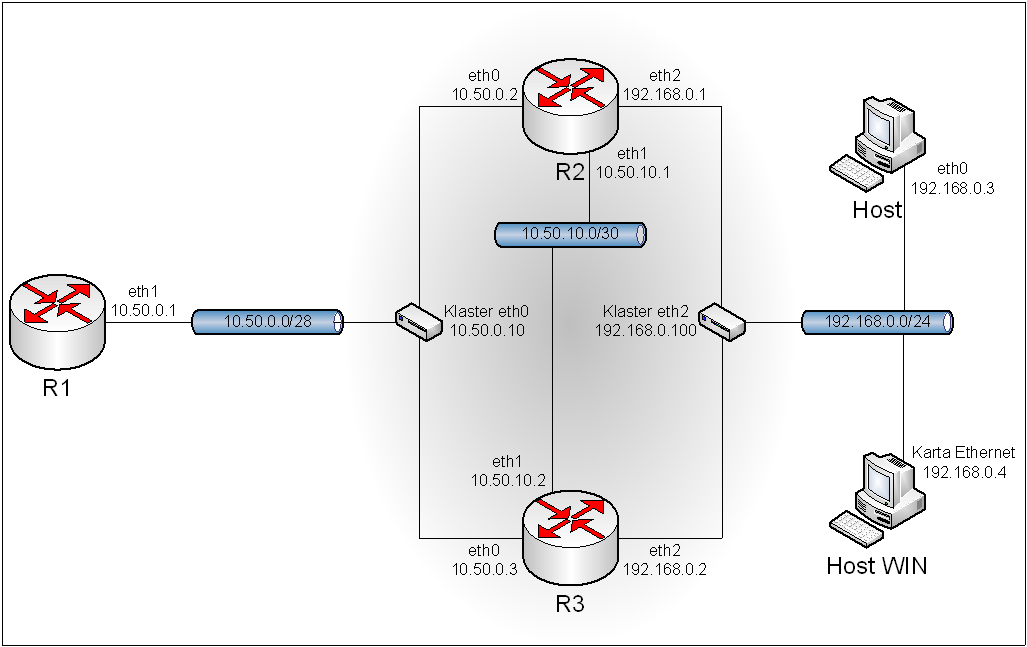
5.1. Topologia.
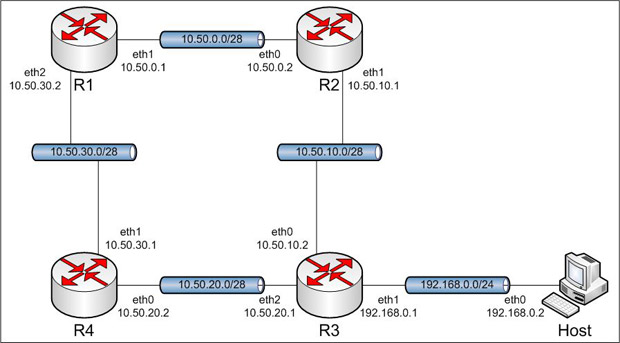
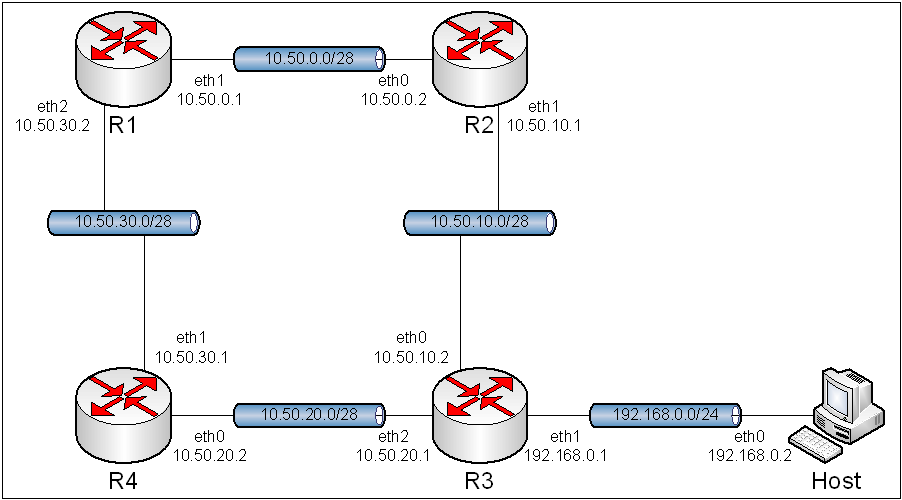
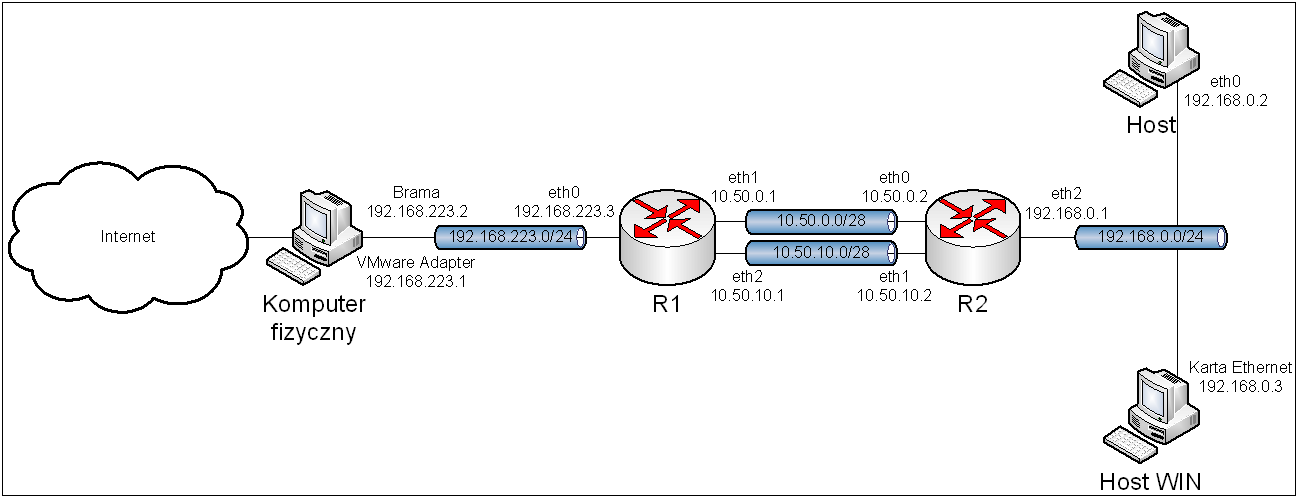
Obraz 5-1: Topologia sieci użytej w zadaniu
Z rysunku topologii została usunięta część mówiącą o połączeniu komputera R1 z Internetem, gdyż rysunek byłby zbyt duży, a co za tym idzie nieczytelny.
5.2. Przygotowanie wirtualnych sieci.
Topologia uległa znaczącej zmianie, więc przed uruchomieniem maszyn trzeba najpierw ustawić odpowiednie sieci.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
eth2 - VMnet5
R2:
eth0 - VMnet2
eth1 - VMnet3
R3:
eth0 - VMnet3
eth1 - VMnet6
eth2 - VMnet4
R4:
eth0 - VMnet4
eth1 - VMnet5
Host:
eth0 - VMnet6
5.3. Cel oraz założenia.
W niniejszym ćwiczeniu zostanie przeprowadzona konfiguracja ze statycznym ustalaniem tras, oraz z uwzględnieniem możliwości awarii jednego z interfejsów.
Zalecana jest znajomość poprzednich ćwiczeń oraz protokołu ICMP.
5.4. Konfiguracja.
Mimo, że na rysunku topologii nie ma mowy o tym mowy, to konfiguracja interfejsu eth0 maszyny R1 oraz bramy domyślnej i maskarady będzie taka sama jak w ćwiczeniu "3. Maskarada". Można ją przywrócić poleceniem 'load' dla komputerów R1, R2 i R3, oczywiście, jeśli została zapisana. Tym samym poleceniem, maszynom R4 i Host zostanie przywrócona konfiguracja z ćwiczenia "2. Początkowa konfiguracja i aktualizacja". Do ukończenia tego ćwiczenia nie jest wymagane połączenie z Internetem.
Poniższe polecenia dostosowują konfigurację do wymogów topologii.
R1:
delete interfaces ethernet eth1 address
set interfaces ethernet eth1 address 10.50.0.1/28
set interfaces ethernet eth2 address 10.50.30.2/28
commit
R2:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 10.50.0.2/28
set interfaces ethernet eth1 address 10.50.10.1/28
set system gateway-address 10.50.0.1
commit
R3:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 10.50.10.2/28
set interfaces ethernet eth1 address 192.168.0.1/24
set interfaces ethernet eth2 address 10.50.20.1/28
set system gateway-address 10.50.10.1
commit
R4:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 10.50.20.2/28
set interfaces ethernet eth1 address 10.50.30.1/28
set system gateway-address 10.50.20.1
commit
Host:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.2/24
set system gateway-address 192.168.0.1
commit
Każdy komputer powinien móc pingować wszystkie interfejsy sąsiedniej maszyny w kierunku przeciwnym do wskazówek zegara. Jest to możliwe dzięki mechanizmowi bramy domyślnej. Dzięki niemu pakiety kierowane z komputera R4 powinny dobrzeć do R1, ale odpowiedź nie powinna wrócić. I to będzie ćwiczenie właśnie o tym jak kierować ruchem za pomocą tras statycznych.
Teraz jest dobry moment, aby zapisać poleceniem 'save' konfigurację na każdej z maszyn, ponieważ przyda się ona w kolejnych ćwiczeniach jako konfiguracja wejściowa.
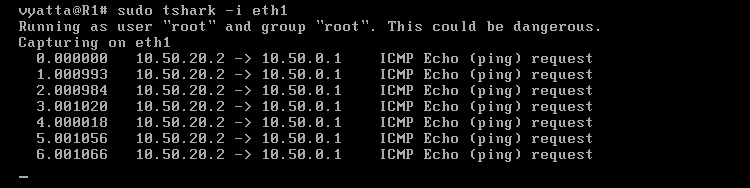
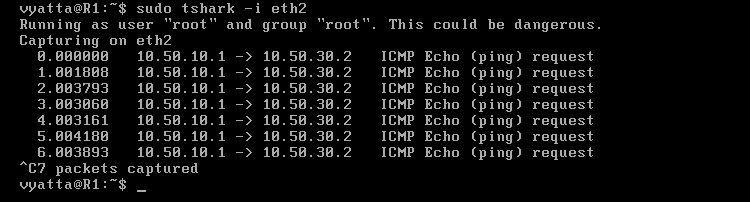
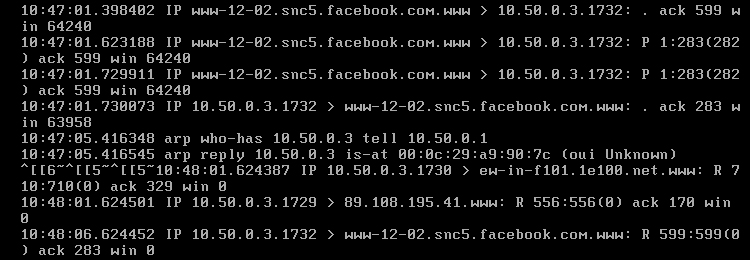
Na maszynie R1 poleceniem 'sudo tshark -i eth1' został uruchomiony sniffer, czyli program do podglądu ruchu sieciowego, o nazwie Tshark. Nasłuchuje na interfejsie eth1. Na komputerze R4 został uruchomiony program Ping poleceniem 'ping 10.50.0.1', a więc pakiety są kierowane do R1. [Obraz 5-2].
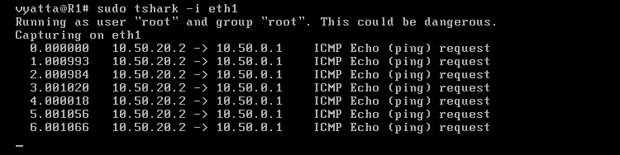
Obraz 5-2: Efekt działania sniffera
Jak widać na powyższym obrazie, żądanie echa ICMP Echo Request dociera do komputera R1, ale odpowiedzi nie widać. Wiadomość zwrotna, Echo Reply została skierowana na adres bramy domyślnej przez interfejs eth0, ponieważ maszyna R1 nie zna trasy do komputera o adresie 10.50.20.2.
Aby poinstruować router R1, co ma zrobić z pakietami od innych maszyn wystarczy wpisać poniższe polecenia.
Składnia użytych poleceń:
- 'set protocols static route next-hop ' -określa przez jaki adres ma zostać wykonany przeskok, aby osiągnąć daną sieć.
R1:
set protocols static route 10.50.10.0/28 next-hop 10.50.0.2
set protocols static route 10.50.20.0/28 next-hop 10.50.0.2
set protocols static route 192.168.0.0/24 next-hop 10.50.0.2
commit
W tym momencie router R1 będzie już wiedział którym interfejsem ma odpowiadać na zapytania ICMP generowane przez program Ping na komputerze R4, lecz R4 nie dostanie odpowiedzi, ponieważ maszyny R2 i R3 nadal nie wiedzą co robić z tymi pakietami i zwracają je z powrotem na adresy swoich bram domyślnych. Aby rozwiązać problem do końca, trzeba skonfigurować także trasy na komputerze R2.
R2:
set protocols static route 10.50.20.0/28 next-hop 10.50.10.2
set protocols static route 192.168.0.0/24 next-hop 10.50.10.2
commit
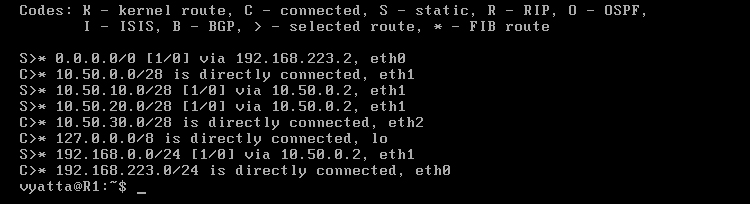
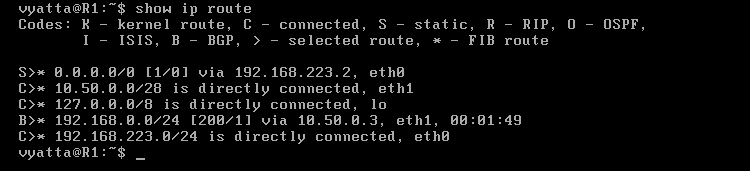
Komputery uzyskują dostęp do sieci 10.50.30.0/28 również dzięki bramom domyślnym, ponieważ bramy te prowadzą pakiety do routera R1, a ta sieć jest do niego bezpośrednio podłączona, co można zobaczyć wywołując tablicę routingu poleceniem 'show ip route' w trybie operacyjnym [Obraz 5-2].
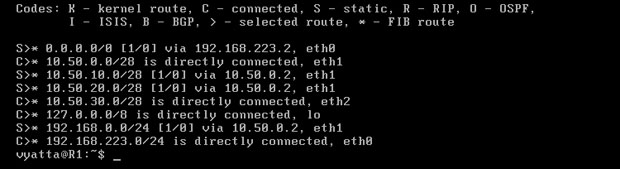
Obraz 5-3: Tablica routingu komputera R1
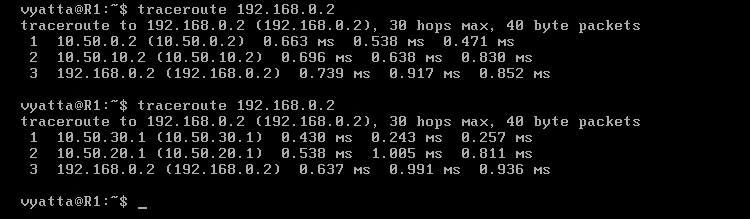
Istnieje bardzo użyteczny program do sprawdzania przebiegu trasy. Zwie się on Traceroute. Na obrazie 5-3 pokazane jest wywołanie go poleceniem 'traceroute 10.50.0.1' z komputera Host.

Obraz 5-4: Trasa z maszyny Host do R1
Powyższy obraz ukazuje trasę Host->R1, wraz adresami interfejsów wejściowych kolejnych komputerów po drodze. Dlaczego akurat interfejsy, którymi pakiety wchodzą do komputerów, a nie wychodzące? Ponieważ program Traceroute, tak samo jak Ping, korzysta z protokołu ICMP do diagnostyki. Odpytuje każdą maszynę po drodze, a ona odpowiadając mu komunikatem Echo Reply, korzysta właśnie z interfejsów skierowanych w stronę komputera pytającego.
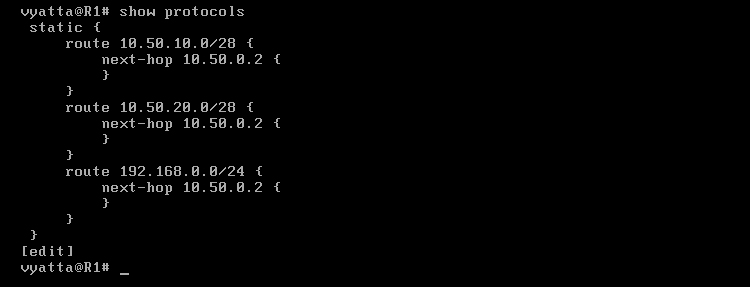
Dla przypomnienia przydatnego polecenia, na obrazie 5-4 zaprezentowana została gałąź drzewa konfiguracji dotycząca protokołów routera R1.
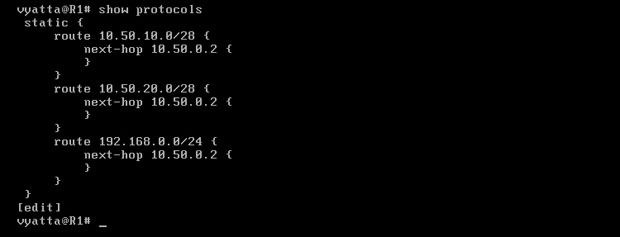
Obraz 5-5: Efekt działania polecenia 'show protocols'
5.5. Działanie w przypadku awarii węzła.
Zasymulowana zostanie awaria komputera R2, odłączając jego interfejs eth0.
R2:
delete interfaces ethernet eth0
commit
Komunikacja na trasach, w których udział brał usunięty interfejs zanikła. Aby ją przywrócić, należy usunąć wpisy o trasach i skonfigurować nowe.
R1:
delete protocols static
set protocols static route 10.50.10.0/28 next-hop 10.50.30.1
set protocols static route 10.50.20.0/28 next-hop 10.50.30.1
set protocols static route 192.168.0.0/24 next-hop 10.50.30.1
commit
R4:
set protocols static route 10.50.10.0/28 next-hop 10.50.20.1
set protocols static route 192.168.0.0/24 next-hop 10.50.20.1
commit
Przykładowe pakiety z routera R1 do komputera Host będą dochodzić, jednak znowu pojawi się problem z pakietami powracającymi, ponieważ bramy domyślne kierują je w stronę usuniętego interfejsu. Aby temu zaradzić, należy przekonfigurować bramy domyślne maszyn R2, R3 i R4 lub dodać na nich wpisy routingu statycznego. Mimo, że ćwiczenie to traktuje o routingu statycznym, zostanie wykonana opcja pierwsza - rekonfiguracja bram, ponieważ tak jest bardziej elegancko i nie dodaje się zbędnych wpisów do tablic routingu.
R2:
set system gateway-address 10.50.10.2
commit
R3:
set system gateway-address 10.50.20.2
commit
R4:
set system gateway-address 10.50.30.2
commit
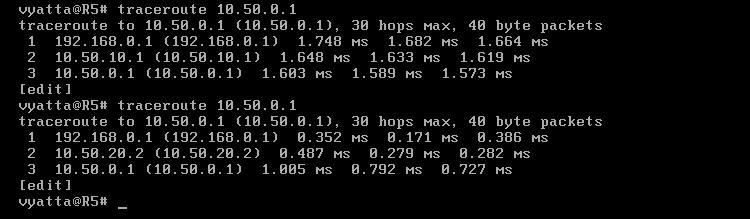
W tym momencie pakiety z komputera R1 do maszyny Host powinny już dochodzić, a trasa powinna być w pełni sprawna, co można sprawdzić poleceniem 'traceroute 192.168.0.2' [Obraz 5-5].

Obraz 5-6: Trasa R1->Host
Routing statyczny jest najprostszą formą trasowania, jednak ma on niewątpliwe zalety. Jest dostępny w każdej sytuacji, nie używa wielu zasobów, jest bardzo prosty i przewidywalny. Jednak jest on odpowiedni tylko dla małych sieci lub dołączania pojedynczych urządzeń do sieci z działającym protokołem routingu dynamicznego, ponieważ nie posiada możliwości automatycznej adaptacji, jak te protokoły.
6. OSPFv2.
Open Shortest Path First jest protokołem trasowania stanu łącza (ang. link-state) opartym o algorytm Dijkstry, który służy do znajdowania najkrótszej ścieżki w grafie. OSPF należy do kategorii IGP (ang. Interior Gateway Protocol), więc działa w obrębie systemu autonomicznego (ang. Autonomous System, AS). Został opisany w dokumencie RFC 2328.
Protokół ten dzieli sieć na obszary, z głównym zwanym area 0 (backbone area) do którego przyłączane są inne obszary. W danym segmencie routery posiadają taką samą bazę topologii sieci, zawierającą dane tylko o obszarze w którym się znajdują; dlatego też bazy te są mniejsze, co prowadzi do zmniejszenia użycia pasma w celu obsługi protokołu oraz izolowania niestabilności tylko do obszaru w którym wystąpiły. Pomiędzy obszarami, OSPF działa jak protokół wektora odległości (ang. distance-vector), wysyłając zsumaryzowane informacje o sieciach.
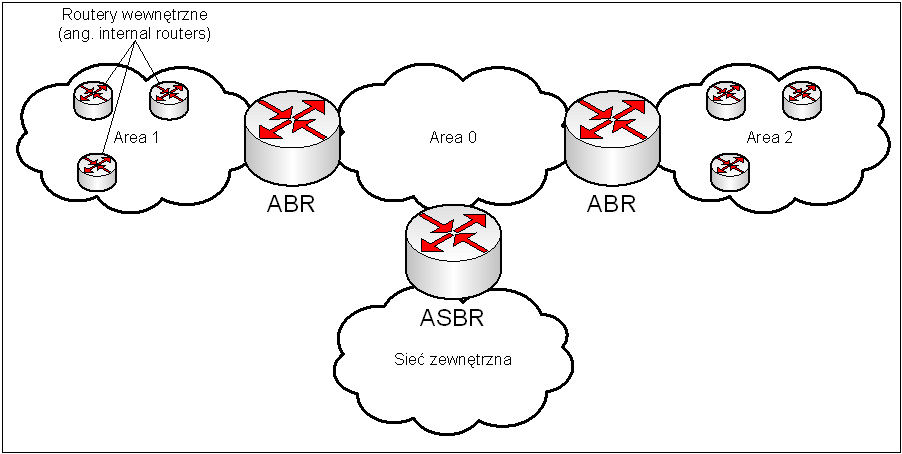
W protokole OSPF zdefiniowane są następujące typy routerów:
- Internal Router – znajduje się wewnątrz obszaru, ogranicza się do trasowania.
- Backbone Router – pracuje w obszarze zerowym.
- Area Border Router (ABR) – router graniczny, łączy obszary ze sobą (jednym z nich jest obszar zerowy). Posiada pełną wiedzę o topologiach obszarów do których jest przyłączony.
- Autonomous System Border Router (ASBR) – łączy się z sieciami o innym protokole routingu. Redystrybuuje trasy z innego protokołu oraz statyczne do OSPF-a.
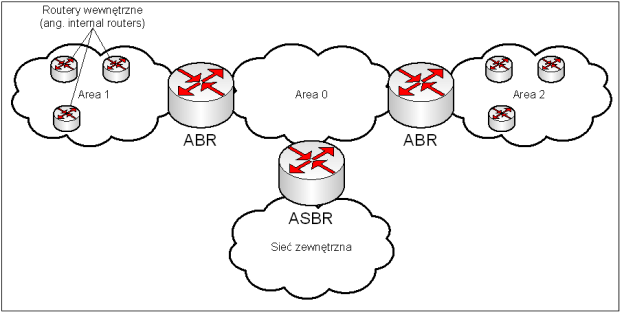
Obraz 6-1: Schemat roli routerów
Oprócz wymienionych powyżej routerów istnieją dwa typy wybierane spośród nich. Są to Designated Router (DR) oraz Backup Designated Router (BDR). Pierwszy z nich jest logicznym centrum danego obszaru – graniczy z każdym routerem w tym obszarze. Nie ma potrzeby, aby każdy router w obszarze wymieniał dane z każdym innym, więc to jego zadaniem jest wymiana informacji z resztą routerów w obszarze; jest on niejako routerem synchronizującym. Dzięki takiemu rozwiązaniu ruch w sieci zostaje zdecydowanie zredukowany. BDR jest natomiast routerem zapasowym. Gdy DR przestanie działać, BDR zostaje mianowany DR, a na nowy BDR jest wybierany, spośród reszty, router o najwyższym priorytecie. Jeśli wszystkie routery mają taki sam priorytet (domyślnie 1), wybrany zostaje ten o najwyższym router-id. Warto zadbać aby DR i BDR zostały najstabilniejsze routery.
W celu gromadzenia informacji o połączeniach routery wysyłają do siebie rozgłoszenia LSA (ang. Link State Advertisement), które są swoistą wiadomością o topologii. Istnieją następujące typy LSA:
- Hello – wysyłany okresowo w celu nawiązywania relacji sąsiedzkich.
- Database Description – opisuje bazę stanów łącz.
- Link State Request – gdy router stwierdzi, że informacje są zdezaktualizowane, żąda aktualniejszą bazę (lub jej część).
- Link State Update – w przypadku zmiany konfiguracji danego routera, router ten wysyła go jako multicast (w OSPF 224.0.0.5).
- Link State Acknowledgment – potwierdza otrzymane stany połączeń.
OSPF przy wyborze trasy uwzględnia:
- liczbę przeskoków (ang. hop) do celu
- opóźnienia w danych fragmentach sieci, najczęściej powodowane przez przeciążenia
- szybkość łącz pomiędzy systemami autonomicznymi
- koszt trasy, który ustala administrator
Protokół OSPF najczęściej jest używany do budowy dużych i skomplikowanych sieci. Cechuje się krótkim czasem zbieżności, wyborem najkorzystniejszych tras oraz niskim obciążeniem sieci, jednakże jego konfiguracja w dużych, wieloobszarowych sieciach może być dość skomplikowana.
6.1. Topologia.
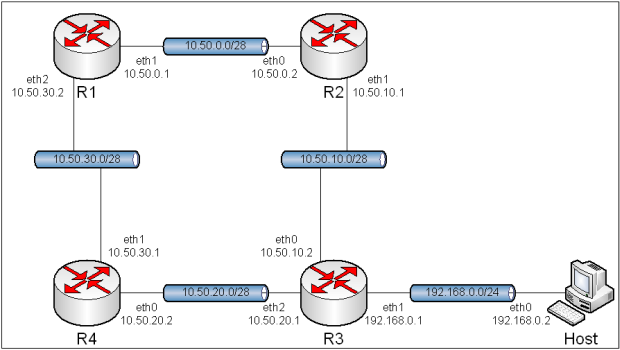
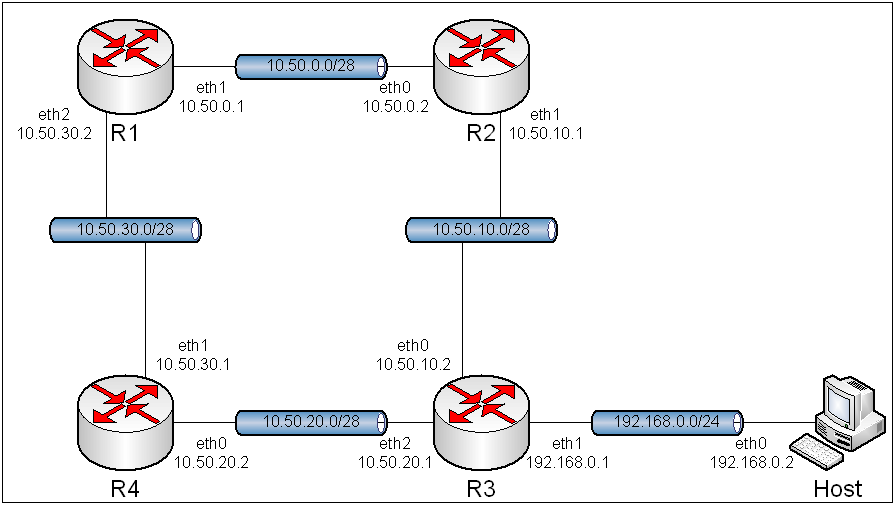
Obraz 6-2: Topologia sieci użytej w zadaniu
Topologia pozostała identyczna jak w poprzednim ćwiczeniu, tj. "5. Routing statyczny".
6.2. Przygotowanie wirtualnych sieci.
Wirtualne sieci zostały skonfigurowane dokładnie tak samo jak w ćwiczeniu "5. Routing statyczny".
6.3. Cel oraz założenia.
Celem niniejszego ćwiczenia jest konfiguracja sieci o topologii pokazanej na obrazie 6-2 przy użyciu protokołu routingu dynamicznego OSPF w wersji drugiej oraz ukazanie jej działania. Użytkownik powinien potrafić przeprowadzić konfigurację interfejsów sieciowych oraz powinien znać podstawy zasady funkcjonowania sieci opartej o technologię Ethernet.
Przed przystąpieniem do działu "6.4. Konfiguracja" użytkownik może zapoznać się z poprzednimi ćwiczeniami oraz z opisem komend w systemie Vyatta; ułatwi to późniejszą pracę.
6.4. Konfiguracja.
Interfejsy komputerów, ich bramy domyślne oraz maskarada zostały skonfigurowane jak w ćwiczeniu "5. Routing statyczny". Wystarczy więc przywrócić wcześniej zapisany stan.
Konfiguracja routingu dla niewielkiej sieci, opartej o jeden obszar (ang. area), jest bardzo prosta – wystarczy poinstruować routery o jakich sieciach mają informować.
Składnia użytych poleceń:
- 'set protocols ospf parameters router-id < ipv4>' - określa identyfikator routera w formacie ipv4; ale nie musi się pokrywać z adresami interfejsów.
- 'set protocols ospf area < identyfikator obszaru> network < adres sieci/maska>' - przyłącza do wskazanego obszaru sieć o podanym adresie.
- 'set protocols ospf redistribute connected' - nakazuje rozgłaszanie także innych, bezpośrednio podłączonych tras.
R1:
set protocols ospf parameters router-id 10.50.0.1
set protocols ospf area 0.0.0.0 network 10.50.0.0/28
set protocols ospf area 0.0.0.0 network 10.50.30.0/28
set protocols ospf redistribute connected
commit
R2:
set protocols ospf parameters router-id 10.50.10.1
set protocols ospf area 0.0.0.0 network 10.50.0.0/28
set protocols ospf area 0.0.0.0 network 10.50.10.0/28
set protocols ospf redistribute connected
commit
R3:
set protocols ospf parameters router-id 10.50.20.1
set protocols ospf area 0.0.0.0 network 10.50.10.0/28
set protocols ospf area 0.0.0.0 network 10.50.20.0/28
set protocols ospf area 0.0.0.0 network 192.168.0.0/24
set protocols ospf redistribute connected
commit
R4:
set protocols ospf parameters router-id 10.50.30.1
set protocols ospf area 0.0.0.0 network 10.50.20.0/28
set protocols ospf area 0.0.0.0 network 10.50.30.0/28
set protocols ospf redistribute connected
commit
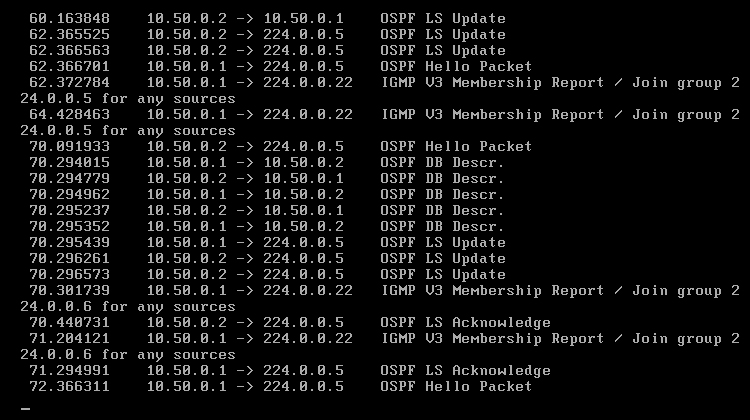
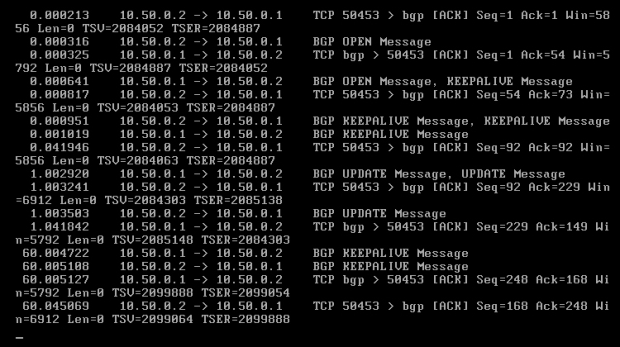
Komputery powinny mieć już łączność, co można łatwo sprawdzić pingując je. W każdej chwili można włączyć kolejny terminal (lewy "ALT + F2" lub kolejne, do "F6") i na nim, za pomocą Tshark-a, podejrzeć jak przebiega wymiana informacji pomiędzy routerami [Obraz 6-3]. Wszystkie pakiety OSPF, które obraz ten pokazuje, zostały opisane w teorii do niniejszego działu; zaś pakiety IGMP służą do administrowania grupami multicastowymi.
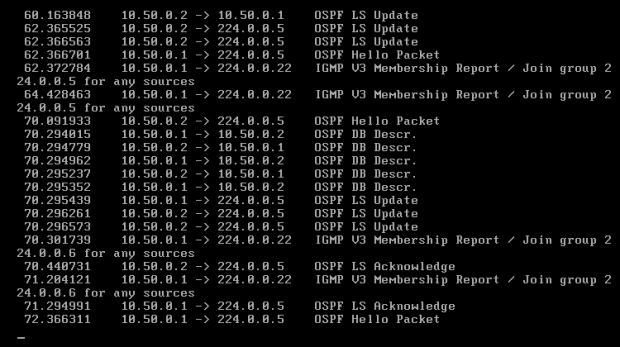
Obraz 6-3: Wymiana informacji między routerami
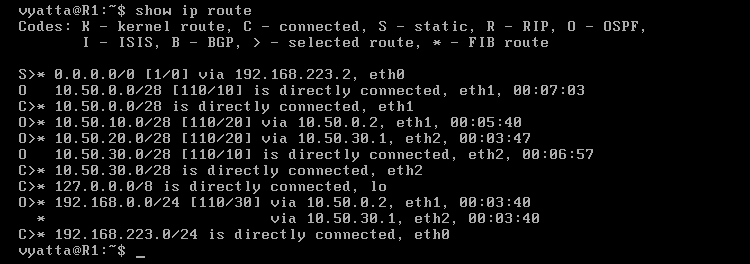
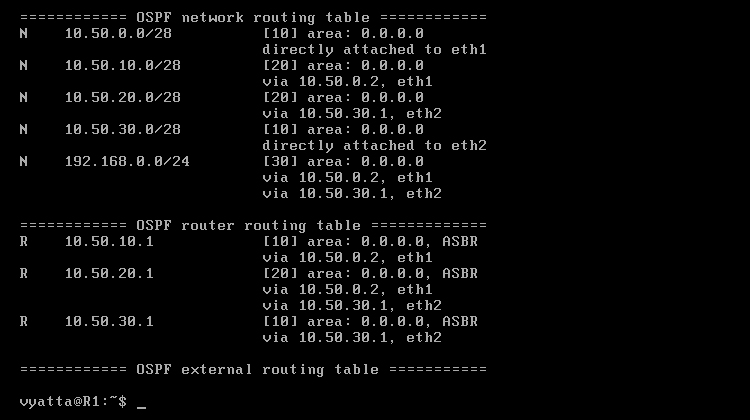
Obraz 6-4 ukazuje tablicę routingu komputera R1, wywołaną poleceniem 'show ip route' w trybie operacyjnym. Trasy oznaczone literą "O" są dostarczane przez protokół OSPF.
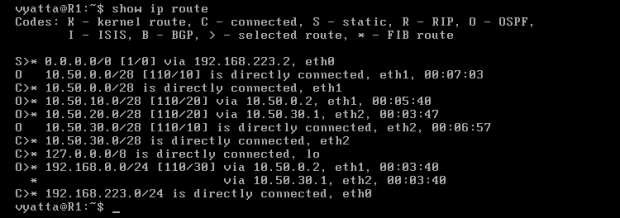
Obraz 6-4: Tablica routingu maszyny R1
Po wywołaniu komendy 'show ip ospf route' pokazuje się tabela routingu OSPF na której zobaczyć można informacje o sieciach, które router R1 posiada oraz informacje o routerach z tych sieci [Obraz 6-5].
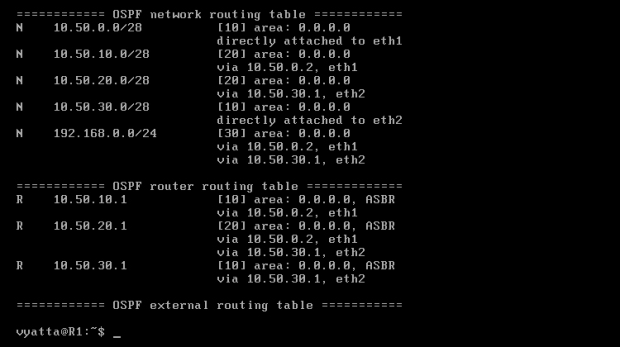
Obraz 6-5: Tablica routingu OSPF komputera R1
Jak da się zauważyć, w części "OSPF external routing table" nic się nie znajduje. Aby to zmienić można usunąć wpis o rozgłaszaniu sieci 192.168.0.0/24 z komputera R3:
R3:
delete protocols ospf area 0.0.0.0 network 192.168.0.0/30
commit
Po ponownym wywołaniu polecenia 'show ip ospf route' na komputerze R1 w części dotyczącej zewnętrznych tras powinna się pokazać sieć 192.168.0.0/24. Wynika to z tego, że owa sieć została usunięta z naszego obszaru 0.0.0.0 i dzięki poleceniu 'set protocols ospf redistribute connected' jest rozgłaszana jako sieć zewnętrzna. W przypadku usunięcia w ten sposób, na przykład, sieci 10.50.20.0/28 z ustawień rozgłaszania komputerów R3 i R4, stała by się ona siecią obcą, zewnętrzną, nie biorącą udziału w rozgłaszaniu w obszarze 0.0.0.0. Wtedy, co prawda, pozostałby dostęp do komputerów przyłączonych do tej sieci, ale chcąc skontaktować komputery R4 i Host pakiety byłyby przekazywane trasą R4–>R1–>R2–>R3–>Host.
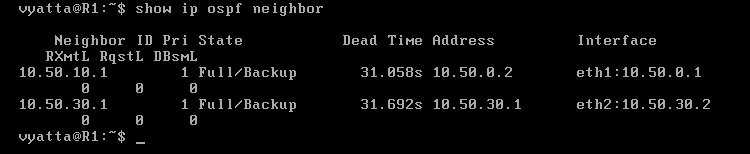
Na obrazie 6-6 pokazani są sąsiedzi R1 (polecenie 'show ip ospf neighbor').
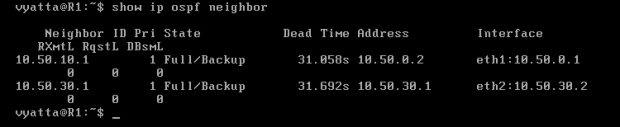
Obraz 6-6: Sąsiedzi komputera R1
6.5. Działanie w przypadku awarii węzła.
Aby sprawdzić jak zachowuje się protokół OSPF w przypadku utraty połączenia z którymś węzłem sieci, można wywołać sztuczną awarię poprzez odłączenie interfejsu jednego z komputerów na trasie przesyłu pakietów. Do sprawdzenia trasy przydatny będzie program Traceroute.
Usunięty zostanie interfejs eth0 komputera R2.
R2:
delete interfaces ethernet eth0
commit
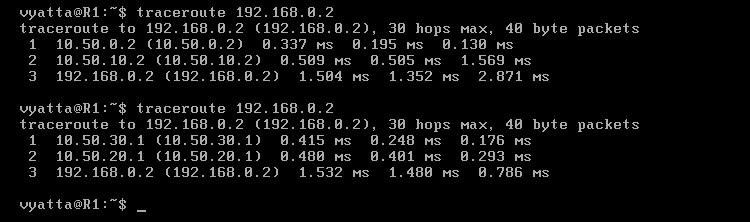
Po wykonaniu tej czynności powinno się sprawdzić trasę raz jeszcze. Na obrazie 6-7 pokazane są dwa wywołania polecenia 'treceroute 192.168.0.2' z komputera R1 – przed i po usunięciu interfejsu eth0 maszyny R2. Preferowana trasa przed usunięciem powyższego interfejsu to R1->R2->R3->Host, natomiast po wyłączeniu tego interfejsu trasa zmienia bieg na R1->R4->R3->Host.
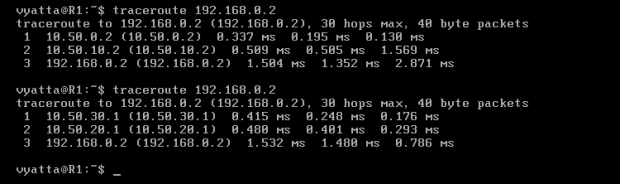
Obraz 6-7: Trasa z R1 do Hosta w czasie poprawnej pracy oraz w czasie awarii jednego interfejsu
W czasie awarii polecenie 'show ip ospf neighbor' na routerze R1 powinno pokazać utratę sąsiada R2. Jak widać, OSPF zmienia trasę automatycznie i bardzo szybko. Nie trzeba zmieniać żadnych wpisów, jak miało to miejsce przy konfiguracji statycznej.
6.6. Wprowadzenie kosztów.
Aby OSPF preferował daną trasę należy zmienić jej koszt na odpowiednio wyższy lub obniżyć koszt trasy przeciwnej. Koszt trasy jest sumą kosztów interfejsów przez które pakiet wychodzi z maszyn po drodze. Dzięki temu, w pewnym sensie, możemy filtrować ruch w zależności od kierunku przepływu pakietów, ponieważ koszt tej samej trasy w obie strony może być inny.
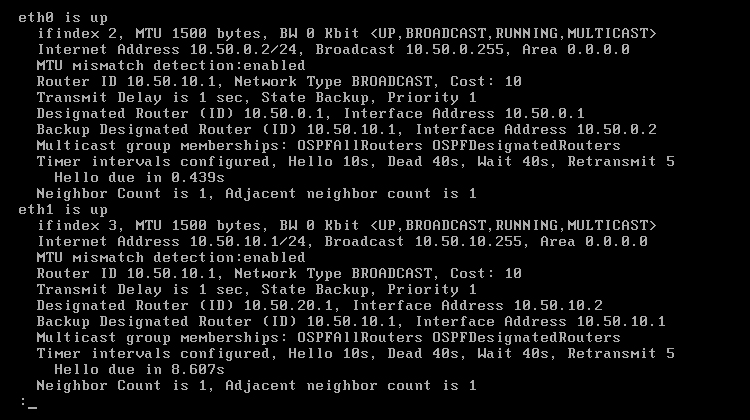
Domyślny koszt dla pojedynczego interfejsu wynosi 10. Wartość tę można sprawdzić komendą 'show ip ospf interface' w trybie operacyjnym. Polecenie wyświetli wynik dla wszystkich interfejsów na danej maszynie, jak na obrazie 6-8. Koszt jest wypisany na końcu 4 linii danych interfejsu.
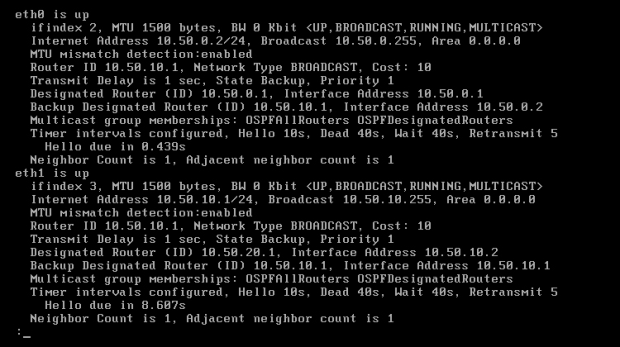
Obraz 6-8: Właściwości interfejsów w protokole OSPF
Przed przystąpieniem do zmian, należy przywrócić interfejs eth0 komputera R2.
R2:
set interfaces ethernet eth0 address 10.50.0.2/28
commit
Dla ułatwienia trasy zostaną oznaczone umownymi nazwami. Niech ścieżka R1->R2->R3->Host nazywa się trasą północną, a ścieżka R1->R4->R3->Host trasą południową. Trasa południowa ma służyć jako zapasowa, przydatna w razie przeciążenia lub awarii ścieżki północnej.
W celu obliczenia kosztu trasy północnej w kierunki R1->Host, trzeba zsumować koszty interfejsów, przez które pakiety wychodzą z maszyn w stronę Hosta, więc eth1 z R1, eth1 z R2 oraz eth1 z R3, co daje koszt równy 30. Analogicznie, dla trasy południowej koszt wynosi również 30. Więc, aby to ta trasa stała się ścieżką domyślną, trzeba zmniejszyć jej koszt przynajmniej o 1 lub zwiększyć o 1 koszt trasy północnej.
Dobrze na początek sprawdzić trasę z R1 do Hosta poleceniem 'traceroute 192.168.0.2', ponieważ poniższy przykład zakłada, że protokół OSPF preferuje trasę północną. Jeśli jest inaczej, wystarczy wykonać poniższe operacje na przeciwnych maszynach (leżących na trasie południowej).
Teraz można już przystąpić do zmiany kosztu interfejsu leżącego na trasie. Będzie to dodanie wartości 5 do kosztu eth1 komputera R2.
R2:
set interfaces ethernet eth1 ip ospf cost 15
commit
Po ponownym wykonaniu polecenia 'traceroute 192.168.0.2' na maszynie R1 widać zmianę preferowanej trasy. Pakiety są przesyłane ścieżką południową [Obraz 6-9].
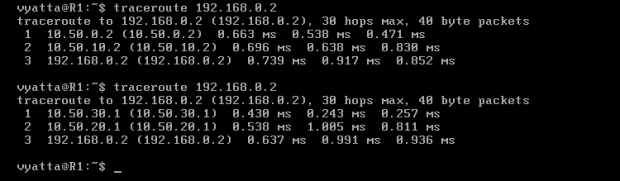
Obraz 6-9: Polecenie 'traceroute 192.168.0.2' na komputerze R1 przed i po zmianie kosztów
Zmiana odniosła skutek w kierunku R1->Host. W kierunku odwrotnym (Host->R1) protokół OSPF nadal preferuje ścieżkę północną, więc żeby w tą stronę pakiety były wysyłane również trasą południową, trzeba zmienić koszty w drugą stronę. Zmiana kosztu interfejsu eth2 komputera R3:
R3:
set interfaces ethernet eth2 ip ospf cost 1
commit
Znowu przydatne będzie polecenie 'traceroute', a dokładniej 'traceroute 10.50.0.1' z maszyny Host. Pokaże ono, że nadal preferowana jest trasa północna. Dlaczego? Koszt trasy północnej jest równy 30 (Host, eth0 = 10; R3, eth0 = 10; R2, eth0 = 10), a koszt trasy południowej wynosi 31 (Host, eth0 = 10, R3, eth2 = 1, R4, eth1 = 10, R1, eth1 = 10). Jak da się zauważyć, w obliczeniach został uwzględniony interfejs eth1 komputera R1, gdyż przy przejściu pakietu trasą południową jest on interfejsem wyjściowym dla komputera R1. Jednak sprawdzając interfejs eth2 maszyny R1 z komputera Host poleceniem 'traceroute 10.50.0.1' uzyskamy zamierzony efekt i preferowana będzie trasa południowa, gdyż ostatnim interfejsem wyjściowym na trasie będzie eth1 komputera R4.
Aby pakiety przebiegały tą samą, południowa trasą z komputera Host do R1, trzeba dodatkowo zwiększyć kosz trasy północnej, co najmniej o 2.
R3:
set interfaces ethernet eth0 ip ospf cost 12
commit
Obraz 6-10 pokazuje wykonanie polecenia 'traceroute 10.50.0.1' przed zmianą kosztów oraz po niej. Cel został osiągnięty, pakiety są przesyłane trasą południową.
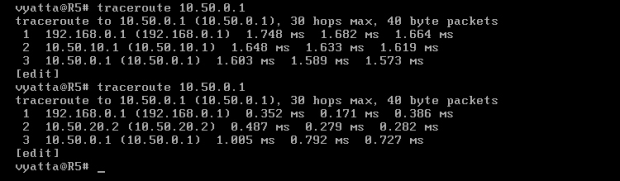
Obraz 6-10: Polecenie 'traceroute 10.50.0.1' na komputerze Host przed i po zmianie kosztów
OSPF jest bardzo sprawnym i szybkim protokołem routingu oraz pozwala na bezproblemowe zarządzanie dużymi sieciami, pod warunkiem poprawnej konfiguracji, a ta, w bardziej skomplikowanych sieciach, może być dość trudna i sprawiać pewne kłopoty.
Nie należy zapisywać zmian poleceniem 'save', gdyż zapis z poprzedniego ćwiczenia będzie przydatny w zadaniu następnym. W razie konieczności zapisania zmian, powinno się użyć polecenia 'save plik'.
7. RIPv2.
Routing Information Protocol w wersji drugiej jest protokołem wektora odległości (ang. distance-vector), należącym do kategorii IGP (ang. Interior Gateway Protocol). Opisano go w RFC 2453.
W tym protokole każdy router tworzy tablicę, w której znajdują się informacje o odległości do innych routerów (metryki), na podstawie których odbywa się routing - RIP preferuje trasy o najmniejszej metryce. Routery okresowo (domyślnie 30 sekund) lub w przypadku zmian w topologii wymieniają się metrykami z sąsiadami przy pomocy wiadomości z żądaniem (ang. request) i odpowiedzi (ang. response), po czym uaktualniają swoje dane. W przypadku systemu Vyatta miarą odległości jest przeskok (ang. hop) do kolejnego routera; więc router tworząc metrykę dla siebie samego uzupełni ją cyfrą 0, dla sąsiada wpisze cyfrę 1, a dla routera, do którego musi wykonać dwa lub więcej przeskoków, wpisze wartość dopiero po otrzymaniu danych o dalszych routerach od swojego sąsiada.
W metryce danego routera może pojawić się liczba 16, oznaczająca nieskończoność. Wartość ta informuje o największej wadzie protokołu RIP - limicie przeskoków do 15. Wprowadzony został on, aby zapobiegać powstawaniu skomplikowanych pętli routingu. Pakiety nie są wysyłane na adres z liczbą 16 w metryce.
RIP wybiera nieoptymalne ścieżki, pozwala tylko na 15 przeskoków, dość długo zajmuje mu osiągnięcie zbieżności, przez co jest podatny na pętle routingu, ale dzięki swojej prostocie i łatwości konfiguracji jest chętnie używany przez administratorów niewielkich sieci.
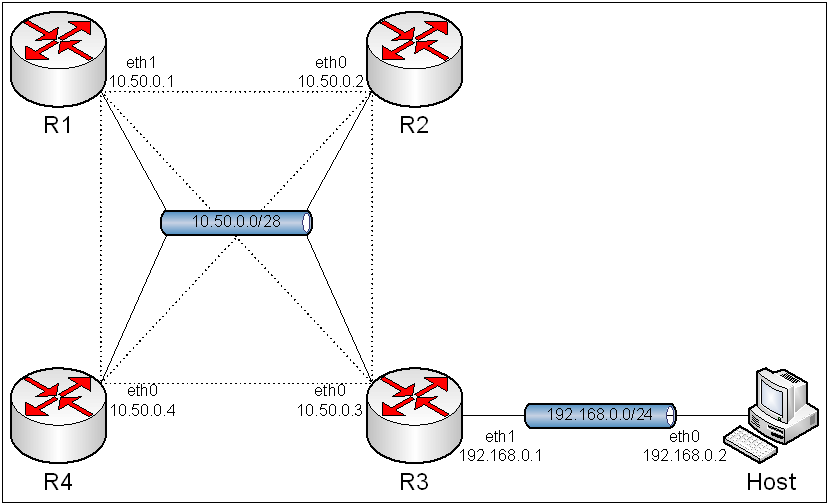
7.1. Topologia.
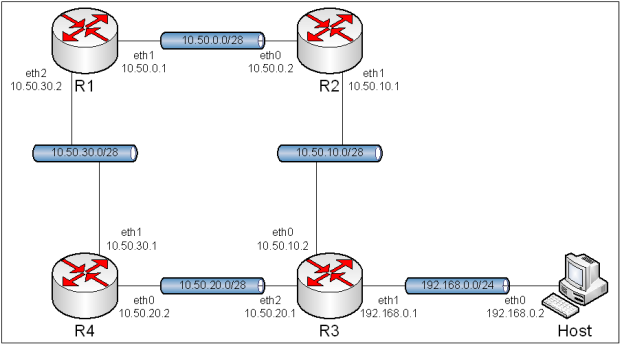
Obraz 7-1: Topologia sieci użytej w zadaniu
Topologia pozostała identyczna jak w poprzednim ćwiczeniu, tj. "5. Routing statyczny".
7.2. Przygotowanie wirtualnych sieci.
Wirtualne sieci zostały skonfigurowane tak samo jak w ćwiczeniu "5. Routing statyczny".
7.3. Cel oraz założenia.
Celem tego ćwiczenia jest konfiguracja trasowania dynamicznego RIP, w sieci z topologią znaną już z poprzednich ćwiczeń.
Aby zrozumieć niektóre, przytoczone tu wypowiedzi oraz polecenia, konieczne może okazać się zapoznanie z wcześniejszymi ćwiczeniami.
7.4. Konfiguracja.
Interfejsy komputerów, ich bramy domyślne oraz maskarada zostały skonfigurowane jak w ćwiczeniu "5. Routing statyczny". Wystarczy przywrócić wcześniejszy zapis poleceniem 'load'.
Przed przystąpieniem do konfiguracji dobrze jest na drugiej konsoli włączyć Tshark-a, który przyda się do podglądania przesyłanych pakietów.
Składnia użytych poleceń:
- 'set protocols rip network < adres sieci/maska>' - określa sieć, która ma być rozgłaszana.
- 'set protocols rip redistribute connected' - nakazuje rozgłaszanie także innych, bezpośrednio podłączonych tras.
R1:
set protocols rip network 10.50.0.0/28
set protocols rip network 10.50.30.0/28
set protocols rip network 192.168.223.0/24
set protocols rip redistribute connected
commit
R2:
set protocols rip network 10.50.0.0/28
set protocols rip network 10.50.10.0/28
set protocols rip redistribute connected
commit
R3:
set protocols rip network 10.50.10.0/28
set protocols rip network 192.168.0.0/24
set protocols rip network 10.50.20.0/28
set protocols rip redistribute connected
commit
R4:
set protocols rip network 10.50.20.0/28
set protocols rip network 10.50.30.0/28
set protocols rip redistribute connected
commit
RIP powinien już wiedzieć, którędy ma przekazywać pakiety. Tshark prezentuje co się dzieje [Obraz 7-2].
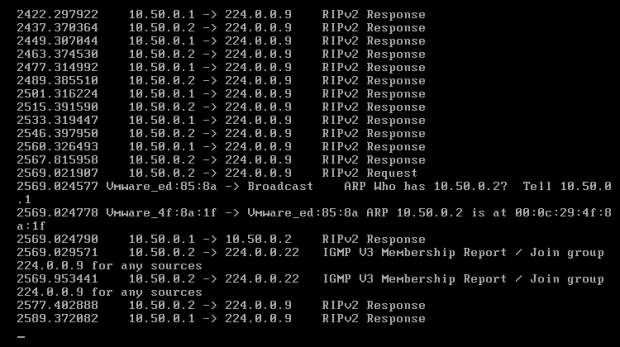
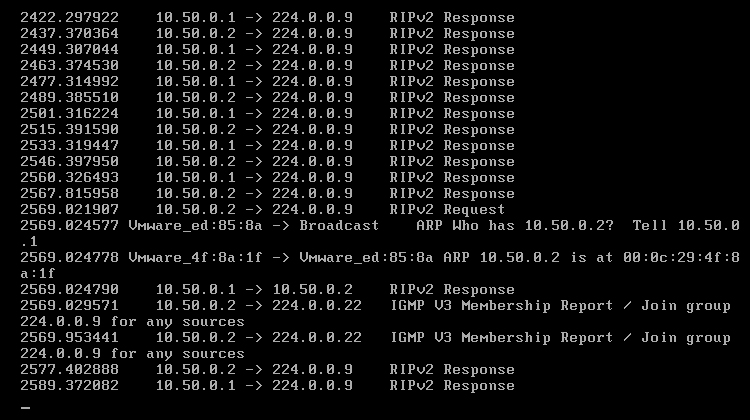
Obraz 7-2: Wymiana informacji między routerami
Jak widać na powyższym obrazie, RIP posiada grupę multicastową o adresie 224.0.0.9, na którą przesyła żądania (RIPv2 Request) oraz odpowiedzi (RIPv2 Response). W podglądzie pojawiają się też pakiety IGMP służące do zarządzania grupami multicastowymi.
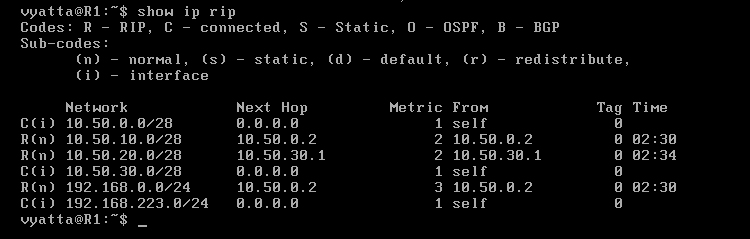
Komputery powinny już odpowiadać na wzajemne pingi. Obraz 7-3 ukazuje tablicę routingu maszyny R1 wywołaną poleceniem 'show ip rip'.
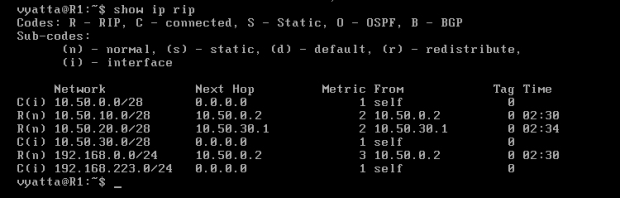
Obraz 7-3: Tablica routingu RIP
Na obrazie tym widać informacje takie jak: sieć, adres interfejsu, przez który nastąpi kolejny przeskok oraz metrykę wyrażoną w przeskokach.
7.5. Wprowadzenie polityki routingu.
Konfigurując routing w systemie Vyatta można zażyczyć sobie, aby informacje o niektórych komputerach lub sieciach nie były rozgłaszane, na przykład z powodu poufności danych. Aby osiągnąć taki skutek, trzeba określić politykę routingu na jednym lub kilku komputerach. W przypadku topologii z obrazu 7-1, celem będzie uczynienie sieci 192.168.0.0/24 niedostępnej dla pozostałych. Polityka routingu będzie konfigurowana w oparciu o listy kontroli dostępu (ang. Access Control List, ACL).
Składnia użytych poleceń:
- 'set policy access-list < numer listy> rule < numer> action deny' - tworzy regułę dla podanej listy z akcją odrzuć.
- 'set policy access-list < numer listy> rule < numer> destination any' - określa cel reguły.
- 'set policy access-list < numer listy> rule < numer> source inverse-mask < maska odwrócona>' - definiuje maskę.
- 'set policy access-list < numer listy> rule < numer> source network < adres sieci>'- definiuje sieć dla której reguła będzie zastosowana.
- 'set protocols rip distribute-list access-list out < numer listy>'- określa listę, która będzie użyta w celu filtrowania wychodzących pakietów RIP.
R3:
set policy access-list 100 rule 1 action deny
set policy access-list 100 rule 1 destination any
set policy access-list 100 rule 1 source inverse-mask 0.0.0.255
set policy access-list 100 rule 1 source network 192.168.0.0
set protocols rip distribute-list access-list out 100
commit
Po chwili, w której RIP odświeży stan tablic, można spróbować pingować Hosta. Efekt powinien być taki, jak na obrazie 7-4.

Obraz 7-4: Próba żądania odpowiedzi od Hosta z komputera R1
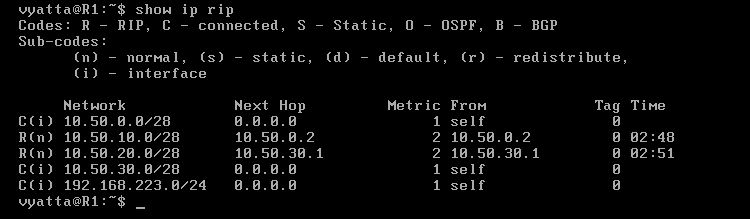
Jak widać, kontakt zanikł. Co więc znajduje się w tablicy routingu maszyny R1? Odpowiedź zawiera obraz 7-5.
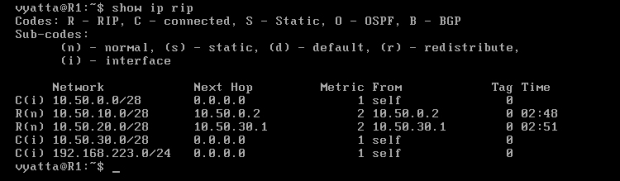
Obraz 7-5: Tablica routingu RIP komputera R1
Jak widać, wpis informujący o sieci 192.168.0.0/24 został usunięty, więc jest ona nieosiągalna. Przedstawione filtrowanie dotyczy rozgłoszeń routingu, więc komputer Host będzie wysyłał pakiety do reszty komputerów, lecz one nie będą wiedziały gdzie skierować odpowiedź.
Jak już zostało wspomniane, RIP jest prostym protokołem, więc nie trzeba poświęcać mu zbyt dużo uwagi. Jednak mimo swoich wad, dzięki prostocie w konfiguracji, RIP nadal znajduje zastosowanie w małych sieciach i jeszcze długo tak pozostanie.
8. BGP-4.
Protokół BGP (ang. Border Gateway Protocol) w wersji 4 należy do kategorii protokołów trasowania zewnętrznego (ang. Exterior Gateway Protocol, EGP). Działa w warstwie 4, korzystając z protokołu TCP na porcie 179, a zatem zapewnia niezawodność, dzięki połączeniowemu trybowi pracy. Opisano go w RFC 4271.
BGP dzieli się na dwa standardy: wewnętrzny (ang. internal BGP, iBGP), nawiązujący relacje sąsiedztwa z routerami wewnątrz systemu autonomicznego (AS) oraz zewnętrzny (ang. external BGP, eBGP), który nawiązuje relacje między AS.
iBGP służy do routowania wewnątrz systemu autonomicznego, który jest pewną grupą sieci zarządzaną przez jeden podmiot oraz mającą wspólną politykę trasowania. Gdy w danym AS jest więcej niż jeden router BGP, to jego wewnętrzna forma pomaga przedostać się pakietom przez ten system autonomiczny, a następnie dzięki eBGP jest kierowana do kolejnego AS. Korzystając z iBGP trzeba mieć na uwadze, że każdy z routerów wewnętrznych musi mieć kontakt z każdym innym - jest to forma zapobiegania pętlom routingu.
Jednak mówiąc o BGP, zazwyczaj ma się na myśli eBGP, czyli standard zewnętrzny. Routery eBGP znajdują się na brzegach systemów autonomicznych, a zatem wyznaczają trasę tworząc listę AS po drodze do celu. Zewnętrzny BGP posiada zabezpieczenie przeciw pętlom routingu polegające na odrzucaniu rozgłoszeń w których jest numer systemu autonomicznego w którym on sam się znajduje.
Dla BGP zdefiniowane są następujące atrybuty:
- ORIGIN - opisuje pochodzenie rozgłoszenia; z wewnątrz AS (IGP, wartość 0), z zewnątrz (EGP, wartość 1) lub niepełne, czyli ścieżka pochodzi z redystrybucji (wartość 2).
- AS_PATH - jest to wspomniana wcześniej lista systemów autonomicznych do celu.
- NEXT_HOP - określa adres następnego przeskoku.
- MULTI_EXIT_DISC - informuje o preferowanej trasie w przypaku, gdy istnieje więcej niż jedna trasa do sąsiedniego AS. Przybiera formę czterech oktetów cyfr.
- LOCAL_PREFERENCE - atrybut podobny do powyższego, jednak jest rozgłaszany tylko w sesji iBGP.
- ATOMIC_AGGREGATE - pozwala na rozgłaszanie jednego prefiksu zamiast kilku.
- AGGREGATOR - identyfikator routera, który wykonał agregację.
Algorytm wyboru trasy sprawdza porównuje atrybuty w pewnej kolejności, a gdy znajdzie pierwszą różnicę, to wybiera daną trasę:
- LOCAL_PREFERENCE - preferowana wyższa wartość.
- długość AS_PATH - pożądana krótsza lista systemów autonomicznych.
- ORIGIN - preferowana niższa wartość.
- MULTI_EXIT_DISC - pożądana niższa wartość.
- typ sąsiada - preferowana trasa nauczona przez eBGP, przed iBGP.
- metryka IGP - pożądana ścieżka z niższą wartością.
- identyfikator BGP- preferowana niższa wartość identyfikatora routera.
- adres IP sąsiada - pożądany niższy IP.
Przy komunikacji BGP używa następujących typów wiadomości:
- OPEN - po nawiązaniu połączenia TCP, jest pierwszą wiadomością przesyłaną przez każdą stronę. Zestawia sesję BGP.
- UPDATE - służy rozgłaszania informacji o routingu.
- KEEPALIVE - utrzymuje sesję BGP.
- NOTIFICATION - jest wysyłana po wykryciu błędu. Po przesłaniu tej wiadomości, sesja BGP jest natychmiast zrywana.
Protokół BGP jest podatny na zjawisko zwane route flapping, które jest sytuacją, gdy trasa jest rozgłaszana i odrzucana na przemian bez końca. Wysyłana jest wtedy nadmiarowa ilość rozgłoszeń, co zapycha łącza oraz obciąża procesory routerów. W systemie Vyatta zawarty jest mechanizm flap damping redukujący to zjawisko na zasadzie ograniczania rozgłoszeń, jednak może dość do całkowitego zaniechania ich rozsyłania, a wtedy wymagana jest interwencja administratora.
Do innych wad BGP należy zaliczyć długi czas zbieżności, podatność na sabotaże mogące odciąć od Internetu wiele ludzi oraz duże tablice routingu. Pełna tablica routera podłączonego do Internetu może się ładować nawet kilka godzin. A niedoświadczeni administratorzy mogą nieopatrznie rozsyłać niepotrzebne rozgłoszenia daleko w Internet, narażając swoją sieć na ataki z zewnątrz. Ze względu na dużą ilość danych w tablicy routingu w większych sieciach oraz proces wyboru trasy, routery służące do obsługi ruchu BGP potrzebują dość dużo pamięci RAM i mocnego procesora, a co za tym idzie, są droższe.
Niewątpliwie jednak bez protokołu BGP nie byłoby dzisiejszego Internetu. Protokół ten, co prawda jest dość skomplikowany, ale jest podstawą jego działania, gdyż zapewnia niezawodność oraz nadmiarowość tras prowadzących do celów na całym globie, a żaden inny protokół routingu nie poradziłby sobie z tak wielką i zróżnicowaną siecią.
8.1. Cel oraz założenia.
Celem niniejszego ćwiczenia jest poznanie protokołu BGP w wersji czwartej oraz praca z nim w różnych konfiguracjach.
Użytkownik powinien zapoznać się z teorią przygotowaną do ćwiczenia, a w razie niezrozumienia działania protokołu lub jego części powinien zapoznać się z bibliografią dla tego działu. Niezbędna może okazać się znajomość poprzednich ćwiczeń.
8.2. iBGP - Full Mesh.
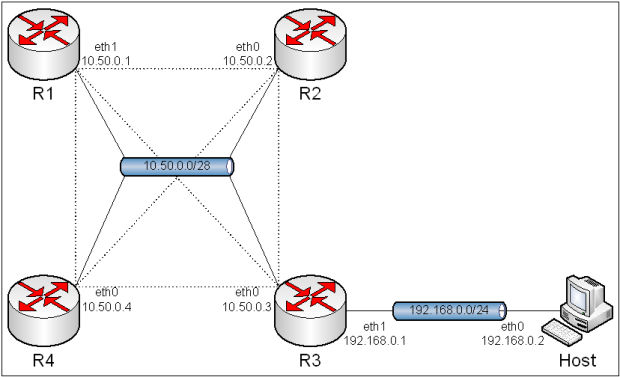
Obraz 8-1: Topologia pełnej sieci
Tak jak w poprzednich ćwiczeniach, na obrazie topologii nie ma informacji o połączeniu z Internetem, ale w rzeczywistości będzie ono skonfigurowane. Na kolejnych obrazach w tym ćwiczeniu także jej nie będzie.
8.2.1. Przygotowanie wirtualnych sieci.
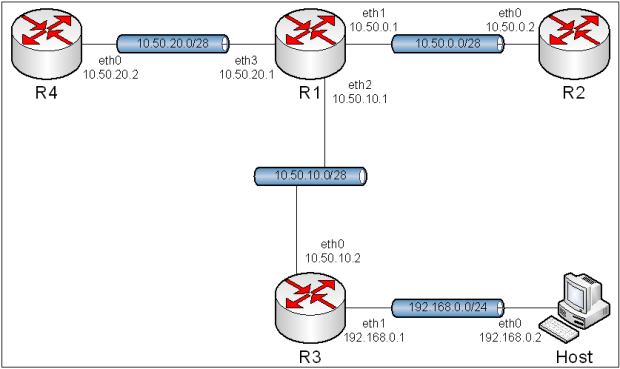
Jako, że topologia się zmieniła, zachodzi potrzeba zmian w konfiguracji wirtualnych sieci. Poniżej wypisane są poszczególne interfejsy maszyn oraz przypisane im wirtualne sieci.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
R2:
eth0 - VMnet2
R3:
eth0 - VMnet2
eth1 - VMnet6
R4:
eth0 - VMnet2
Host:
eth0 - VMnet6
8.2.2. Konfiguracja.
Konfiguracja oparta o pełną sieć (ang. full mesh) zapewnia kontakt każdego routera z każdym innym, co jest konieczne w iBGP do uniknięcia pętli routingu. Jest rzadko używana, zazwyczaj w bardzo małych sieciach.
Dobrym rozwiązaniem jest wczytanie konfiguracji zapisanej w ćwiczeniu "5. Routing statyczny" poleceniem 'load'. Jednak dwa interfejsy trzeba przekonfigurować.
R3:
delete interfaces ethernet eth0
set interfaces ethernet eth0 address 10.50.0.3/28
commit
R4:
delete interfaces
set interfaces ethernet eth0 address 10.50.0.4/28
commit
Następnie należy skonfigurować protokół BGP, zgodnie ze składnią:
- 'set protocols bgp < numer AS> neighbor < identyfikator routera> remote-as < numer AS>' - określa numer systemu autonomicznego routera-sąsiada o podanym identyfikatorze w formacie ipv4.
- 'set protocols bgp < numer AS> neighbor < identyfikator routera> update-source < adres IP>' - określa adres IP będący źródłem aktualizacji routingu dla sąsiedniego routera.
- 'set protocols bgp < numer AS> parameter router-id < ipv4>' - określa identyfikator routera w formacie ipv4.
- 'set protocols bgp < numer AS> network < adres sieci>' - definiuje adres rozgłaszaną sieć.
R1:
set protocols bgp 100 neighbor 10.50.0.2 remote-as 100
set protocols bgp 100 neighbor 10.50.0.2 update-source 10.50.0.1
set protocols bgp 100 neighbor 10.50.0.3 remote-as 100
set protocols bgp 100 neighbor 10.50.0.3 update-source 10.50.0.1
set protocols bgp 100 neighbor 10.50.0.4 remote-as 100
set protocols bgp 100 neighbor 10.50.0.4 update-source 10.50.0.1
set protocols bgp 100 parameter router-id 10.50.0.1
commit
R2:
set protocols bgp 100 neighbor 10.50.0.1 remote-as 100
set protocols bgp 100 neighbor 10.50.0.1 update-source 10.50.0.2
set protocols bgp 100 neighbor 10.50.0.3 remote-as 100
set protocols bgp 100 neighbor 10.50.0.3 update-source 10.50.0.2
set protocols bgp 100 neighbor 10.50.0.4 remote-as 100
set protocols bgp 100 neighbor 10.50.0.4 update-source 10.50.0.2
set protocols bgp 100 parameter router-id 10.50.0.2
commit
R3:
set protocols bgp 100 neighbor 10.50.0.1 remote-as 100
set protocols bgp 100 neighbor 10.50.0.1 update-source 10.50.0.3
set protocols bgp 100 neighbor 10.50.0.2 remote-as 100
set protocols bgp 100 neighbor 10.50.0.2 update-source 10.50.0.3
set protocols bgp 100 neighbor 10.50.0.4 remote-as 100
set protocols bgp 100 neighbor 10.50.0.4 update-source 10.50.0.3
set protocols bgp 100 parameter router-id 10.50.0.3
set protocols bgp 100 network 192.168.0.0/24
commit
R4:
set protocols bgp 100 neighbor 10.50.0.1 remote-as 100
set protocols bgp 100 neighbor 10.50.0.1 update-source 10.50.0.4
set protocols bgp 100 neighbor 10.50.0.2 remote-as 100
set protocols bgp 100 neighbor 10.50.0.2 update-source 10.50.0.4
set protocols bgp 100 neighbor 10.50.0.3 remote-as 100
set protocols bgp 100 neighbor 10.50.0.3 update-source 10.50.0.4
set protocols bgp 100 parameter router-id 10.50.0.4
commit
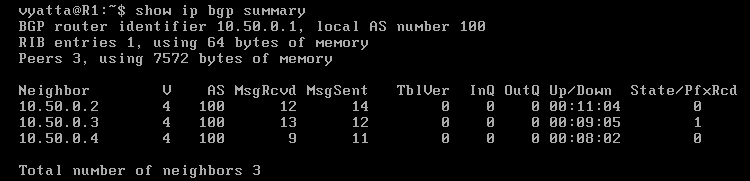
Wpisując polecenie 'show ip bgp summary' w trybie operacyjnym, można zobaczyć krótkie podsumowanie działania BGP zawierające przede wszystkim informacje o sąsiadach [Obraz 8-2].
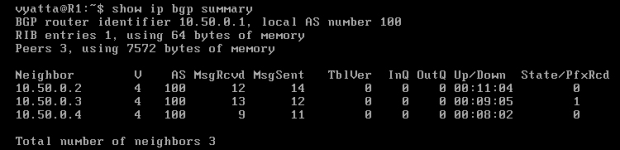
Obraz 8-2: Podsumowanie BGP
Na obrazie 8-3 ukazane jest wykonanie komendy 'show ip route', wyświetlające tablicę routingu. Protokół BGP informuje, że sieć 192.168.0.0/24 jest osiągalna poprzez adres 10.50.0.3.
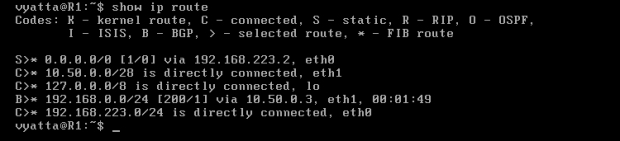
Obraz 8-3: Tablica routingu komputera R1
Jak widać konfiguracja internal BGP nie jest trudna, ani skomplikowana. Jednak implementacja tego protokołu routingu jako samodzielnego, mija się z celem, gdyż do takich zadań zostały stworzone protokoły RIP oraz OSPF.
8.3. iBGP - Route Reflector.
Obraz 8-4: Topologia sieci z użyciem propagatora tras
8.3.1. Przygotowanie wirtualnych sieci.
Ponownie zachodzi potrzeba zmian w konfiguracji wirtualnych sieci.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
eth2 - VMnet3
eth3 - VMnet4
R2:
eth0 - VMnet2
R3:
eth0 - VMnet3
eth1 - VMnet6
R4:
eth0 - VMnet4
8.3.2. Konfiguracja.
Konfiguracja sieci z użyciem routera będącego propagatorem tras (ang. route reflector) jest sporo korzystniejsza niż wykorzystanie pełnej sieci (ang. full mesh), ponieważ nie ma potrzeby, aby każdy łączył się z każdym, a wystarczy, że jeden router będzie węzłem, swoistym zwierciadłem, zestawiającym sesje z resztą routerów. W rezultacie zamiast topologii pełnej sieci zostanie otrzymana topologia gwiazdy, co przy większej sieci nie pozostaje bez znaczenia.
Konieczna była ponowna konfiguracja wirtualnych sieci, więc dobrym sposobem na rozpoczęcie pracy będzie wczytanie zapisanego stanu z ćwiczenia "5. Routing statyczny" polecenim 'load'.
R1:
delete interfaces ethernet eth2
set interfaces ethernet eth1 address 10.50.0.1/28
set interfaces ethernet eth2 address 10.50.10.1/28
set interfaces ethernet eth3 address 10.50.20.1/28
commit
Następnie należy przystąpić do konfiguracji protokołu BGP. Dodatkowo na drugiej konsoli komputera R1 można uruchomić program Tshark poleceniem 'tshark -i eth1'.
Składnia użytych poleceń:
- 'set protocols bgp < numer AS> neighbor < identyfikator routera> remote-as route-reflector-client' - przypisuje router o podanym identyfikatorze jako klienta route reflectora, tym samym router lokalny staje się route reflectorem.
R1:
set protocols bgp 100 neighbor 10.50.0.2 remote-as 100
set protocols bgp 100 neighbor 10.50.0.2 route-reflector-client
set protocols bgp 100 neighbor 10.50.0.2 update-source 10.50.0.1
set protocols bgp 100 neighbor 10.50.10.2 remote-as 100
set protocols bgp 100 neighbor 10.50.10.2 route-reflector-client
set protocols bgp 100 neighbor 10.50.10.2 update-source 10.50.10.1
set protocols bgp 100 neighbor 10.50.20.2 remote-as 100
set protocols bgp 100 neighbor 10.50.20.2 route-reflector-client
set protocols bgp 100 neighbor 10.50.20.2 update-source 10.50.20.1
set protocols bgp 100 network 10.50.0.0/28
set protocols bgp 100 network 10.50.10.0/28
set protocols bgp 100 network 10.50.20.0/28
set protocols bgp 100 parameter router-id 10.50.0.1
commit
R2:
set protocols bgp 100 neighbor 10.50.0.1 remote-as 100
set protocols bgp 100 neighbor 10.50.0.1 update-source 10.50.0.2
set protocols bgp 100 network 10.50.0.0/28
set protocols bgp 100 parameters router-id 10.50.0.2
commit
R3:
set protocols bgp 100 neighbor 10.50.0.1 remote-as 100
set protocols bgp 100 neighbor 10.50.0.1 update-source 10.50.10.2
set protocols bgp 100 network 10.50.10.0/28
set protocols bgp 100 network 192.168.0.0/24
set protocols bgp 100 parameters router-id 10.50.10.2
commit
R4:
set protocols bgp 100 neighbor 10.50.0.1 remote-as 100
set protocols bgp 100 neighbor 10.50.0.1 update-source 10.50.20.2
set protocols bgp 100 network 10.50.20.0/28
set protocols bgp 100 parameters router-id 10.50.20.2
commit
Polecenie 'traceroute 192.168.0.2' wykonane z komputera R4 potwierdza poprawność wykonanej konfiguracji - pakiety są przesyłane kolejno przez routery R4->R1->R3->Host [Obraz 8-5].

Obraz 8-5: Wykonanie polecenia traceroute 192.168.0.2'
Wcześniej uruchomiony Tshark może pokazać co się dzieje na łączach - jak przebiega wymiana informacji oraz utrzymanie sesji BGP [Obraz 8-6].
Obraz 8-6: Wymiana informacji przez BGP
Tak samo jak konfiguracja sieci full mesh, konfiguracja z użyciem route reflectora nie jest zbyt skomplikowana. Trzeba tylko poinformować routery, że mają być klientami w stosunku do jednej, nadrzędnej maszyny. Efektem wykorzystania propagatora tras jest spora oszczędność pasma, szczególnie w większych sieciach - routery nie muszą zapinać sesji z każdym innym, wystarczy z jednym.
W powyższym przypadku można było uniknąć rozgłaszania tylu podsieci, tworząc tylko jedną, główną - jak w przypadku konfiguracji pełnej sieci, gdzie nie było sensu tworzyć dwóch dodatkowych sieci na krzyż, gdyż niepotrzebnie skomplikowałoby to obraz topologii. Jednak nie można unikać zmienności i podziału, więc na potrzeby niniejszych ćwiczeń będą stosowane zróżnicowane topologie, dające nieco pracy routerom i użytkownikom.
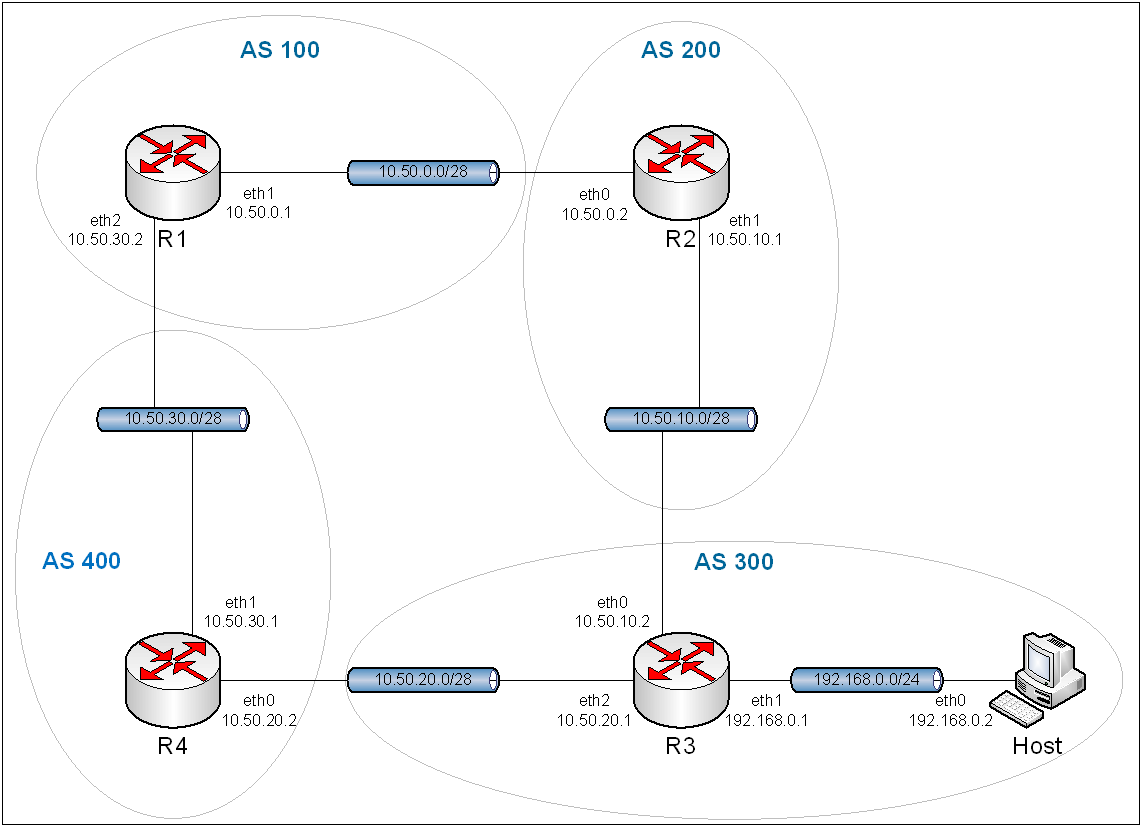
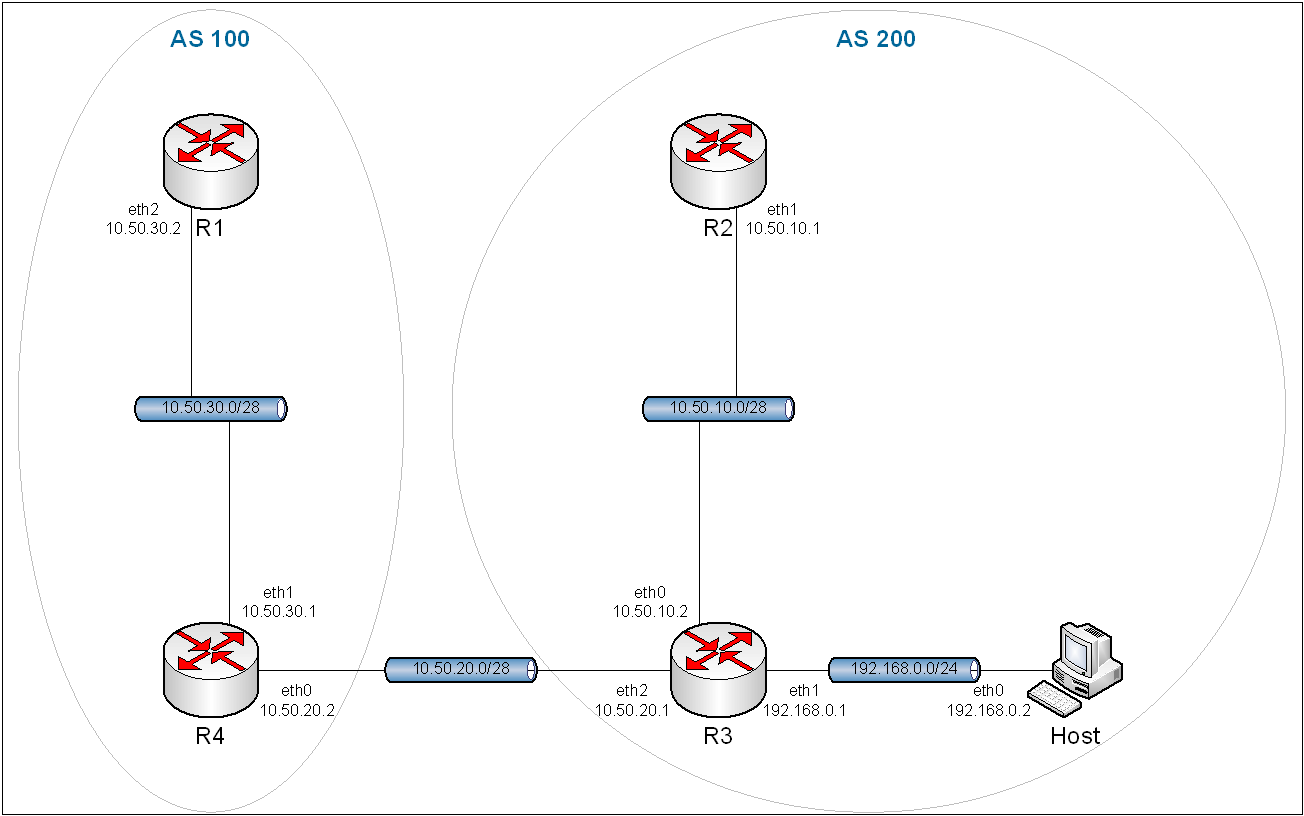
8.4. eBGP.
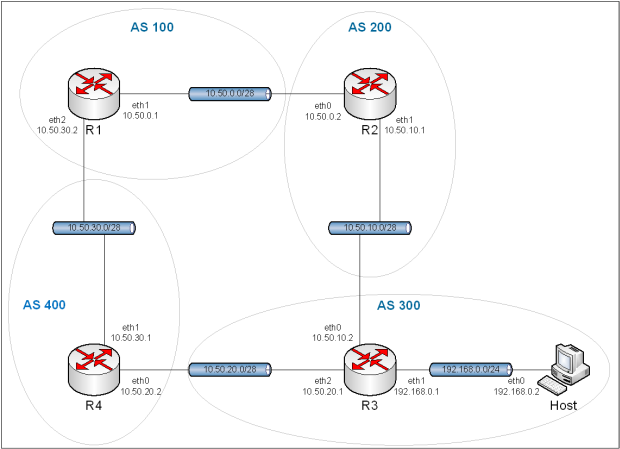
Obraz 8-7: Topologia sieci z wykorzystaniem eBGP
8.4.1. Przygotowanie wirtualnych sieci.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
eth2 - VMnet5
R2:
eth0 - VMnet2
eth1 - VMnet3
R3:
eth0 - VMnet3
eth1 - VMnet6
eth2 - VMnet4
R4:
eth0 - VMnet4
eth1 - VMnet5
Host:
eth0 - VMnet6
8.4.2. Konfiguracja.
Ćwiczenie należy rozpocząć od wczytania konfiguracji zapisanej w ćwiczeniu "5. Routing statyczny". Topologia jest taka sama, więc nie trzeba wprowadzać żadnych zmian.
Podstawowa konfiguracja eBGP jest trochę krótsza niż dwie poprzednie iBGP, jednak działanie protokołu jest zgoła odmienne. Routery już nie muszą mieć kontaktu z każdym innym, a działają na podstawie jednostek organizacyjnych zwanych systemami autonomicznymi. Niniejsza konfiguracja jest mała jak to możliwe; służyć ma tylko ukazaniu działania sieci. W Internecie każdy pojedynczy system autonomiczny zawiera w sobie dużą ilość komputerów, jak i routerów oraz jest podzielony na mniejsze podsieci, zarządzane protokołami wewnętrznego routingu.
R1:
set protocols bgp 100 neighbor 10.50.0.2 remote-as 200
set protocols bgp 100 neighbor 10.50.30.1 remote-as 400
set protocols bgp 100 network 10.50.0.0/28
set protocols bgp 100 parameter router-id 10.50.0.1
commit
R2:
set protocols bgp 200 neighbor 10.50.0.1 remote-as 100
set protocols bgp 200 neighbor 10.50.10.2 remote-as 300
set protocols bgp 200 network 10.50.10.0/28
set protocols bgp 200 parameter router-id 10.50.10.1
commit
R3:
set protocols bgp 300 neighbor 10.50.10.1 remote-as 200
set protocols bgp 300 neighbor 10.50.20.2 remote-as 400
set protocols bgp 300 network 10.50.20.0/28
set protocols bgp 300 network 192.168.0.0/24
set protocols bgp 300 parameter router-id 10.50.20.1
commit
R4:
set protocols bgp 400 neighbor 10.50.20.1 remote-as 300
set protocols bgp 400 neighbor 10.50.30.2 remote-as 100
set protocols bgp 400 network 10.50.30.0/28
set protocols bgp 400 parameter router-id 10.50.30.1
commit
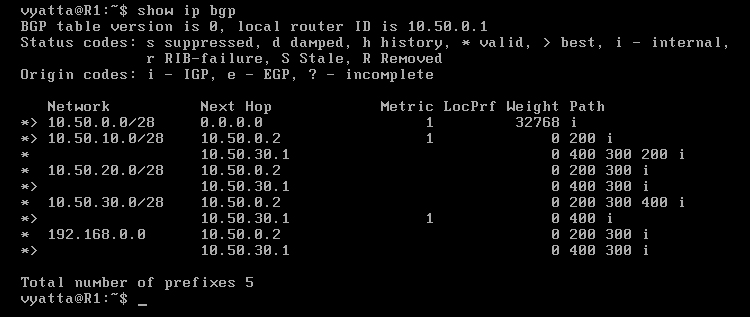
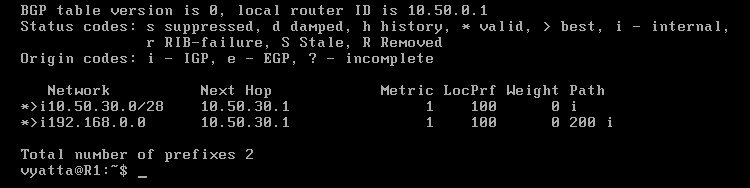
Po wyświetleniu tablicy routingu BGP komputera R1 poleceniem 'show ip bgp' (w trybie operacyjnym), pokazanej na obrazie 8-8, można zobaczyć sieci i wyznaczone do nich trasy, reprezentowane przez ciąg systemów autonomicznych, przez które kolejno będą poruszać się pakiety. Te oznaczone znakiem większości (">") są ścieżkami preferowanymi, po których będą poruszać się pakiety.
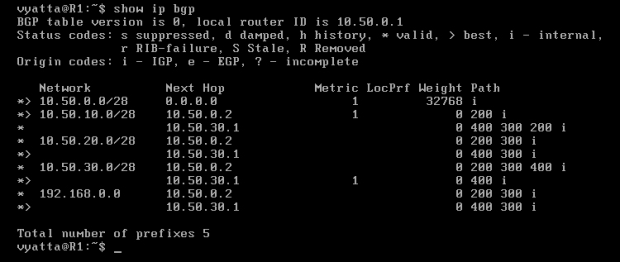
Obraz 8-8: Tablica routingu BGP komputera R1
8.4.3. Wprowadzenie lokalnych preferencji.
Jak widać na powyższym obrazie, komputer R1 chcąc dostać się do maszyny Host preferuje trasę przez router R4. Administrator może sprawić, aby pakiety opuszczające system autonomiczny były przesyłane inną ścieżką, w tym przypadku przez R2. W tym celu trzeba zmienić atrybut o nazwie LOCAL_PREFERENCE (pol. lokalna preferencja). Jako, że w niniejszej topologii każdy router jest w osobnym systemie autonomicznym, nie ma możliwości eksportowania (rozgłaszania) preferencji lokalnej do sąsiadów, jak ma to miejsce, gdy są w tym samym AS.
Na początek należy skonfigurować politykę routowania dla obu tras.
Składnia użytych poleceń:
- 'set policy route-map < nazwa mapy> rule < numer> action permit' - tworzy regułę w mapie routingu o podanej nazwie z akcją zezwalaj. Określenie akcji jest obowiązkowe.
- 'set policy route-map < nazwa mapy> rule < numer> set local-preference < wartość>' - ustanawia preferencję lokalną o wpisanej wartości.
R1:
set policy route-map LOC-PREF rule 1 action permit
set policy route-map LOC-PREF rule 1 set local-preference 200
set policy route-map LOC-PREF-DOWN rule 1 action permit
set policy route-map LOC-PREF-DOWN rule 1 set local-preference 100
commit
Następnie należy wprowadzić politykę w użytek.
R1:
set protocols bgp 100 neighbor 10.50.0.2 route-map import LOC-PREF
set protocols bgp 100 neighbor 10.50.0.2 route-map import LOC-PREF-DOWN
commit
Na koniec należy zresetować sesje z sąsiadami w celu odświeżenia tablicy routingu. Należy wykonać to poleceniami 'clear ip bgp 10.50.0.2' oraz 'clear ip bgp 10.50.30.1' w trybie operacyjnym.
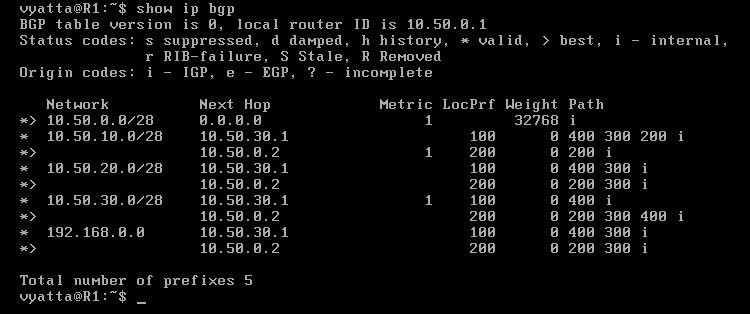
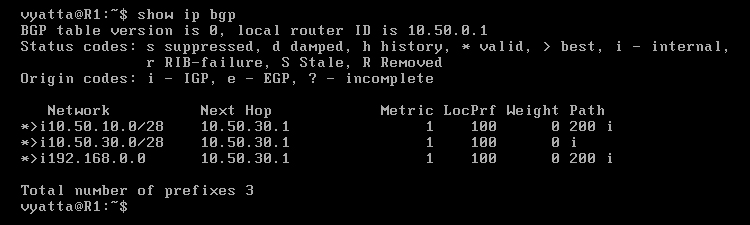
Tablica routingu routera R1 ukazuje zmiany [Obraz 8-9]. W kolumnie "LocPrf" pojawiły się ustawione preferencje, a trasy oznaczone znakiem większości zmieniły się na inne, ponieważ atrybut LOCAL_PREFERENCE ma pierwszeństwo przed innymi.
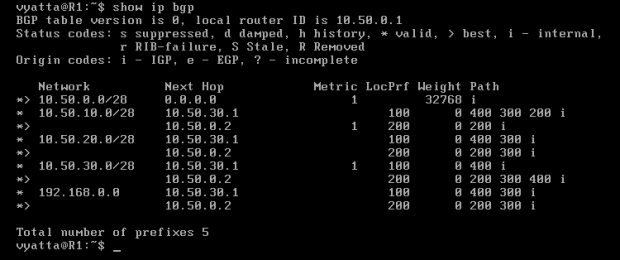
Obraz 8-9: Tablica routingu BGP
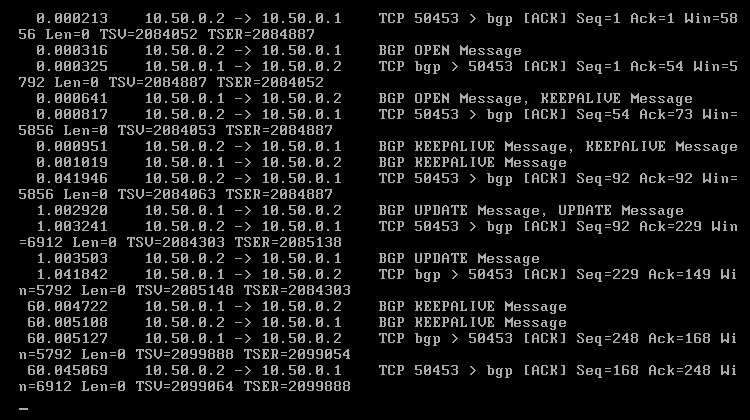
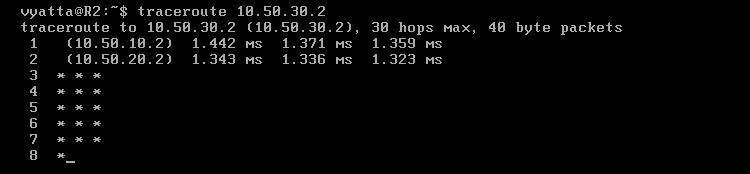
Polecenie 'traceroute 192.168.0.2' wykonane z komputera R1 potwierdza zmiany, które zaszły. Preferowana ścieżka zmieniła swój bieg i teraz pakiety są przesyłane przez maszynę R2 [Obraz 8-10].

Obraz 8-10: Przebieg trasy R1->Host
Podobny efekt można uzyskać używając atrybutu MULTI_EXIT_DISC, jednak jest on niżej w hierarchii algorytmu wyboru trasy, więc zadziałałby tylko dla tras o takiej same długości AS_PATH, a nie dla wszystkich. Innym kryterium koniecznym do działania MULTI_EXIT_DISC jest ustawienie pochodzenia pakietów na EGP, co można uczynić korzystając z mapy routingu.
8.4.4. Filtrowanie rozgłoszeń.
Protokół BGP pozwala na filtrowanie rozgłoszeń pochodzących z innych routerów lub wysyłanych do innych routerów. Są sytuacje, gdy niektóre trasy nie są pożądane do przesyłania pewnych pakietów, zaś inne ścieżki są dedykowane tylko dla określonego ruchu. Za przykład można podać taki oto scenariusz: dwie firmy życzą sobie wymieniać informacje między sobą, lecz nie za pomocą internetu, ponieważ koszt łącza dzierżawionego od dostawcy jest wysoki. Firmy te decydują się utworzyć połączenie pomiędzy sieciami, przez które będzie kierowany cały ruch między nimi. O taki stan rzeczy może zadbać BGP, rozgłaszając prefiksy każdej z tych sieci.
Topologia powyższego przykładu została przedstawiona na obrazie 8-11. Poniżej znajduje się konfiguracja.
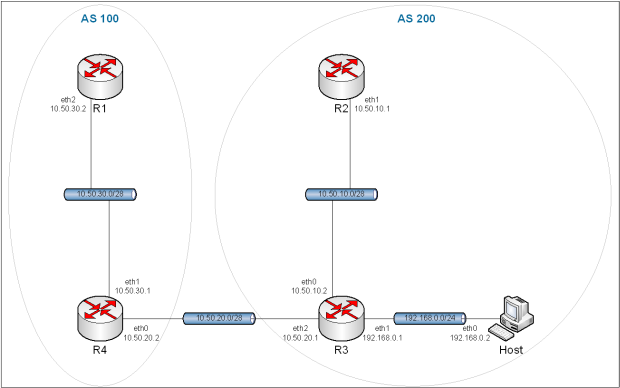
Obraz 8-11: Topologia dwóch połączonych sieci
Aby nie trudzić się z usuwaniem zbędnych elementów konfiguracji, poleceniem 'load' wystarczy ponownie załadować zapisaną wcześniej konfigurację. Usunięte zostaną interfejsy eth1 routera R1 oraz eth0 komputera R2, a także bramy domyślne wszystkich komputerów, prócz maszyny Host, ze względu na problemy w obserwacji, które mogą sprawiać.
R1:
delete interfaces ethernet eth1
delete system gateway-address
set protocols bgp 100 neighbor 10.50.30.1 remote-as 100
set protocols bgp 100 neighbor 10.50.30.1 update-source 10.50.30.2
set protocols bgp 100 parameter router-id 10.50.0.1
commit
R2:
delete interfeces ethernet eth0
delete system gateway-address
set protocols bgp 200 neighbor 10.50.10.2 remote-as 200
set protocols bgp 200 neighbor 10.50.10.2 update-source 10.50.10.1
set protocols bgp 200 parameter router-id 10.50.10.1
commit
R3:
delete system gateway-address
set protocols bgp 200 neighbor 10.50.10.1 remote-as 200
set protocols bgp 200 neighbor 10.50.10.1 update-source 10.50.10.2
set protocols bgp 200 neighbor 10.50.20.2 remote-as 100
set protocols bgp 200 network 10.50.10.0/28
set protocols bgp 200 network 192.168.0.0/24
set protocols bgp 200 parameter router-id 10.50.20.1
commit
R4:
delete system gateway-address
set protocols bgp 100 neighbor 10.50.20.1 remote-as 200
set protocols bgp 100 neighbor 10.50.30.2 remote-as 100
set protocols bgp 100 neighbor 10.50.30.2 update-source 10.50.30.1
set protocols bgp 100 network 10.50.30.0/28
set protocols bgp 100 parameter router-id 10.50.30.1
commit
Jednak po wpisaniu powyższych linii nie wszystkie sieci będą osiągalne. Maszyna R1 nie będzie mogła pingować sieci 10.50.10.2/28 oraz 192.168.0.0./24, a router R2 nie będzie mógł pingować sieci 10.50.30.0/28. Wszystkiemu winne są wpisy z tablicy routingu informujące o następnym skoku do adresu IP niedostępnego bezpośrednio - komputery po prostu nie posiadają wiedzy, którym kolejnym węzłem sieci mają wysyłać pakiety i przez to są wysyłane na adres bramy domyślnej.
Na obrazie 8-12 pokazana jest tablica routingu komputera R1 z takimi właśnie wpisami, kierującymi na adres IP 10.50.20.1.
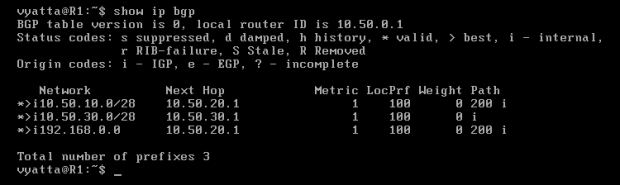
Obraz 8-12: Tablica routingu BGP z niepożądanymi wpisami
Aby zapobiec powyższej sytuacji, trzeba poinformować komputery, które węzły mają umieścić w tablicach routingu.
R3:
set protocols bgp 200 neighbor 10.50.10.1 nexthop-self
commit
R4:
set protocols bgp 200 neighbor 10.50.30.2 nexthop-self
commit
Na koniec, w trybie operacyjnym na komputerze R4, poleceniem 'clear ip bgp 10.50.20.1', należy zresetować sesję z sąsiadem.
Powyższe polecenia informują komputery R3 oraz R4, aby w wysyłanych aktualizacjach routingu do komputerów określonych po słowie 'neighbor' (pol. sąsiad) jako adres następnego przeskoku wpisały same siebie. Po odebraniu aktualizacji router R2 (10.50.30.2) dodaje wpis o następnym skoku z adresem 10.50.10.2, a R1 dodaje wpis z adresem 10.50.30.1 [Obraz 8-13].
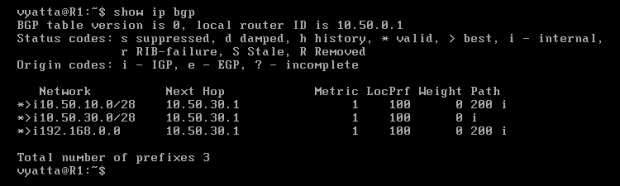
Obraz 8-13: Tablica routingu BGP komputera R1 z poprawionymi wpisami
W rezultacie sieci wcześniej nieosiągalne stały się dostępne, a sieć odwzorowuje topologię z obrazu 8-11.
Teraz można przejść do filtrowania rozgłoszeń. Cel jest następujący: tylko sieć 192.168.0.0/24 z AS 200 powinna być rozgłaszana do systemu autonomicznego numer 100. Stan taki można osiągnąć wprowadzając do konfiguracji komputera R3 mapy routingu dla rozgłoszeń wychodzących lub analogicznie mapy dla rozgłoszeń przychodzących do konfiguracji routera R4. Poniższy przykład pokaże pierwszą z opcji.
Składnia użytych poleceń:
- 'set policy prefix-list < nazwa listy> rule < numer> action permit' - tworzy regułę w liście prefiksów o podanej nazwie z akcją zezwalaj. Określenie akcji jest obowiązkowe.
- 'set policy prefix-list < nazwa listy> rule < numer> prefix < adres sieci>' - do danej reguły przypisuje podany adres sieci.
- 'set policy route-map < nazwa mapy> rule < numer> action permit' - tworzy regułę dla podanej mapy z akcją zezwalaj. Określenie akcji jest obowiązkowe.
- 'set policy route-map < nazwa mapy> rule < numer> action deny' - tworzy regułę dla podanej mapy z akcją odrzuć.
- 'set policy route-map < nazwa mapy> rule < numer> match ip address prefix-list < nazwa listy prefiksów>' - przypasowuje adresy sieci z listy prefiksów o wpisanej nazwie.
- 'set protocols bgp < numer AS> neighbor < identyfikator routera> route-map export < nazwa mapy>' - włącza do działania stworzoną wcześniej mapę routingu sąsiada o podanym identyfikatorze. Słowo 'export' oznacza rozgłoszenia wychodzące.
R3:
set policy prefix-list PREFIXES rule 1 action permit
set policy prefix-list PREFIXES rule 1 prefix 192.168.0.0/24
set policy route-map MAP rule 1 action permit
set policy route-map MAP rule 1 match ip address prefix-list PREFIXES
set policy route-map MAP rule 2 action deny
set protocols bgp 200 neighbor 10.50.20.2 route-map export MAP
commit
Trzeba pamiętać o zresetowaniu sesji z sąsiadem (w trybie operacyjnym), poleceniem 'clear ip bgp 10.50.20.2' na routerze R3.
Finalnie rozgłoszenia o sieci 10.50.10.0/28 nie powinny być wysyłane do routera R4, a co za tym idzie, żaden komputer z AS 100, nie będzie miał dostępu do tej sieci (nie będą o niej wiedzieć), jak i żaden komputer z sieci 10.50.10.0/28 nie będzie potrafił osiągnąć maszyn z systemu autonomicznego nr 100 (będzie do nich wysyłał pakiety, ale komputery z AS 100 nie będą wiedziały gdzie odpowiedzieć).
Na obrazie 8-14 pokazana jest tablica routingu komputera R1 po operacji filtrowania rozgłoszeń. Natomiast obraz 8-15 przedstawiona jest próba wyznaczenia trasy z maszyny R2 do R1.

Obraz 8-14: Tablica routingu BGP komputera R1
Obraz 8-15: Próba wyznaczenia trasy Host->R1
Rozgłoszenia można także blokować na podstawie numeru systemu autonomicznego. W stosunku do powyższego przykładu zmian będzie niewiele, a dla odmiany blokowane będą rozgłoszenia przychodzące.
Składnia użytych poleceń:
- 'delete protocols bgp < numer AS> neighbor < identyfikator routera> route-map' - wyłącza mapę routingu.
- 'delete policy' - usuwa politykę routingu.
- 'set policy as-path-list < nazwa listy> rule < numer> action permit' - tworzy regułę dla podanej listy numerów systemów autonomicznych z akcją zezwalaj. Określenie akcji jest obowiązkowe.
- 'set policy as-path-list < nazwa listy> rule < numer> regex < wartość>' - dopisuje podanej listy numer AS.
- 'set policy route-map < nazwa mapy> rule < numer> match match as-path < nazwa listy>' - przypasowuje numery AS z listy o podanej nazwie.
R3:
delete protocols bgp 200 neighbor 10.50.20.2 route-map
delete policy
commit
R4:
set policy as-path-list LIST rule 1 action permit
set policy as-path-list LIST rule 1 regex 200
set policy route-map MAP rule 1 action deny
set policy route-map MAP rule 1 match as-path LIST
set policy route-map MAP rule 2 action permit
set protocols bgp 100 neighbor 10.50.20.1 route-map import MAP
commit
Na komputerze R4 należy zresetować sesję poleceniem 'clear ip bgp 10.50.20.1'.
Z komputerów w AS 100 zostały usunięte wpisy o sieciach 10.50.10.0/28 oraz 192.168.0.0/24, gdyż pasują one do wzoru z listy systemów autonomicznych przeznaczonych do odrzucenia. W AS 200 wpisy z adresem sieci 10.50.30.0/28 znajdują się nadal, jednak może być problem z kontaktem. Jak pokazano na obrazie 8-16, pakiety z komputera R2 dochodzą do R1, ale router R1 nie odpowiada na nie, gdyż pochodzą one z sieci w AS 200, a on nie zna trasy do niej.
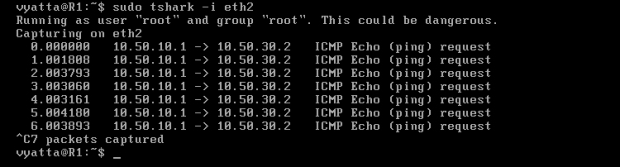
Obraz 8-16: Żądanie echa wysyłane z komputera R2 do R1
Filtrowanie rozgłoszeń umożliwia odpowiednie zarządzanie ruchem między systemami autonomicznymi. Przytaczając raz jeszcze przykład dwóch firm, można oczekiwać, że część przynajmniej jednej z firmowych sieci nie powinna być dostępna dla drugiej ze względu na poufność, co zostało osiągnięte.
Protokół BGP pozwala na prostą, jak i bardzo skomplikowaną administrację sieciami, a przez swoje możliwości stał się trzonem dzisiejszego Internetu, choć z powodu swojej złożoności jest protokołem dość trudnym i, niejednokrotnie, powodującym problemy na skalę międzynarodową.
9. Firewall.
Firewall, czyli zapora sieciowa ma za zadanie zapobiegać włamaniom do systemów komputerowych, chronić przed różnymi atakami, również tymi mającymi za zadanie przeciążyć system lub urządzenie oraz filtrować ruch w poszukiwaniu innych zagrożeń i reagować na nie.
Zapora w systemie Vyatta jest oparta o filtr pakietów - każdy pakiet przechodzący przez określony interfejs jest przypasowywany do reguł w ustalonej kolejności. Gdy pakiet będzie odpowiadał regule, wykonywana jest określona akcja, gdy nie będzie pasował, podejmowana jest akcja domyślna, która jest określona na drop [Obraz 9-1].
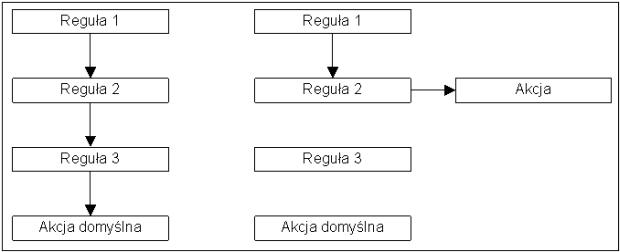
Obraz 9-1: Podejmowanie decyzji przez zaporę
Jest kilka akcji do wyboru, w systemie Vyatta są to:
- Accept - pakiet jest przepuszczany przez interfejs.
- Drop - pakiet jest odrzucany.
- Reject - pakiet jest odrzucany, resetuje połączenie TCP.
- Inspect - pakiet jest przekazywany do inspekcji IPS (ang. Intrusion Prevention System).
Akcja reject różni się od drop tym, że resetuje połączenie TCP, a to daje sygnał nadawcy wiadomości, że jego pakiet został odrzucony, co jest często niepożądane. Bezpieczniej jest, aby myślał, że pakiet nie dotarł do nikogo; wtedy firewall nie zostaje narażony na atak. Należy pamiętać aby nie zostawić żadnej pustej reguły z akcją accept, ponieważ system potraktuje to jako zezwolenie na wpuszczenie każdego pakietu.
W systemie Vyatta można zdefiniować kilka instancji firewalla, z których na każdy interfejs można ustawić 3, w różnych kierunkach:
- In - jest to ruch przychodzący, ale nie skierowany do routera na którym jest firewall.
- Out - ruch wychodzący, ale nie pochodzący od routera.
- Local - ruch przychodzący, skierowany do routera.
Każdy pakiet może mieć określony stan:
- NEW -pakiet, który nie był wcześniej zaobserwowany przez jądro systemu.
- ESTABLISHED - połączenie ustanowione. Znane pakiety UDP i ICMP także są oznaczane tym stanem, mimo, że należą do protokołów bezpołączeniowych.
- RELATED - połączenie powiązane. Są to pakiety obsługujące połączenie będące w stanie ESTABLISHED. Może być na przykład częścią połączenia FTP, które działa na kilku portach.
- INVALID - pakiet niezidentyfikowany lub niepoprawny.
Firewall konfigurowany w niniejszym ćwiczeniu jest to tylko przykładową, podstawową zaporą z odblokowanymi usługami, które akurat były potrzebne. Ukazuje możliwości oraz sposób konfiguracji w systemie Vyatta. Nie zabezpiecza komputerów przed wszystkimi atakami!
9.1. Topologia.
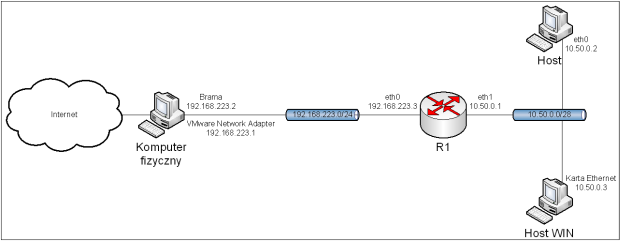
Obraz 9-1: Topologia sieci użytej w zadaniu
Komputer Host działa pod kontrolą systemu Vyatta, natomiast Host WIN pod kontrolą systemu Windows XP.
9.2. Przygotowanie wirtualnych sieci.
Przy nowej topologii muszą także zajść zmiany w konfiguracji wirtualnych sieci. Poniżej zostały wypisane interfejsy maszyn oraz odpowiadające im sieci.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
Host:
eth0 - VMnet2
Host WIN:
Karta Ethernet - VMnet2
9.3. Cel oraz założenia.
Celem tego zadania jest nauka konfiguracji zapory sieciowej z mieszanymi scenariuszami zagrożeń.
Aby móc w pełni wykorzystać to ćwiczenie, niezbędna jest przynajmniej podstawowa wiedza z zakresu funkcjonowania protokołów sieciowych takich jak: TCP, IP, UDP, DNS, HTTP, HTTPS, ARP, ICMP oraz SSH. Przydatna może okazać się także wiedza z poprzednich ćwiczeń.
9.4. Konfiguracja.
Na początek, poleceniem 'load', należy załadować konfigurację zapisaną w ćwiczeniu "5. Routing statyczny", a następnie poprawić część konfiguracji.
Host:
delete interfaces
set interfaces ethernet eth0 address 10.50.0.2/28
set system gateway-address 10.50.0.1
commit
Analogicznie, na komputerze Host WIN należy wprowadzić adres 10.50.0.3.
W tym miejscu należy zapisać konfigurację poleceniem 'save', ponieważ będzie ona przydatna jako konfiguracja bazowa w następnych ćwiczeniach.
Aby zacząć konfigurować poszczególne reguły firewalla, najpierw trzeba określić co należy blokować lub odblokować oraz na jakim porcie dany ruch jest przesyłany. Za przykład niech posłuży obraz 9-2. Tym razem dane będą podglądane za pomocą innego snifferera, o nazwie Tcpdump, który został wywołany poleceniem 'sudo tcpdump -i eth1'.
Obraz 9-2: Ruch HTTP oraz ARP na routerze R1
Na obrazie tym widoczne są pakiety HTTP oraz ARP przesyłane z komputera Host WIN (10.50.0.3) oraz do niego. To co interesuje w nim najbardziej, to porty po jakich się poruszają. Po adresie komputera lub nazwie domeny jest określony port, przykładowo linia z danymi "www-12-02.snc5.facebook.com.www > 10.50.0.3.1732" informuje o przesłaniu pakietu z domeny facebook.com na porcie protokołu HTTP (o czym informuje port ".www", czyli 80) do komputera Host na port 1732, więc portem źródłowym będzie 80, a docelowym 1732.
Przy wpisywaniu pierwszej reguły, dany firewall będzie miał określoną domyślną politykę na "drop", więc jeśli pakiet nie będzie pasował do żadnej z nich, zostanie odrzucony. Gdy, po zaznajomieniu się z ruchem przesyłanym przez komputer R1, wiadomo już jake protokoły i porty należy odblokować, można przystąpić do konfiguracji. Na początek niech odblokowany zostanie protokół HTTP (protokół TCP, port 80), aby na komputerach Host oraz Host WIN można było surfować po Internecie, lecz żeby stało się to możliwe, konieczne jest odblokowanie usługi DNS, która działa w protokole UDP na porcie 53.
Dobrym zwyczajem jest zostawianie odstępu liczbowego między regułami na wypadek konieczności dopisania w późniejszym terminie innej, gdzieś pomiędzy.
Składnia użytych poleceń:
- 'set firewall name < nazwa> rule < numer> action accept' - określa nazwę firewalla, numer reguły oraz akcję jaka ma zostać podjęta.
- 'set firewall name < nazwa> rule < numer> source port < adres>' -definiuje port pochodzenia pakietu dla określonej reguły. Port może być nazwą, numerem lub zakresem. Można także użyć odwrotności oraz wpisywać porty w liście, oddzielone przecinkami.
- 'set firewall name < nazwa> rule < numer> protocol udp' - określa protokół paketu.
- 'set interfaces ethernet < interfejs> firewall out name < nazwa>' - przypisuje firewall o określonej nazwie do danego interfejsu jako "out".
R1:
set firewall name FIREWALL-OUT rule 10 action accept
set firewall name FIREWALL-OUT rule 10 protocol udp
set firewall name FIREWALL-OUT rule 10 source port 53
set firewall name FIREWALL-OUT rule 20 action accept
set firewall name FIREWALL-OUT rule 20 protocol tcp
set firewall name FIREWALL-OUT rule 20 source port 80
set interfaces ethernet eth1 firewall out name FIREWALL-OUT
commit
Jednak po wykonaniu tych kroków, nie wszystkie strony będą się ładować. Problemy będą dotyczyć stron łączących się poprzez protokół HTTPS, ponieważ wykorzystuje on do zapewnienia bezpieczeństwa transmisji protokół SSL, działający porcie 443 protokołu TCP, który nadal jest blokowany [Obraz 9-3].
Obraz 9-3: Zablokowany protokół HTTPS
W celu odblokowania, należy wpisać do konfiguracji poniższe linie. Teraz już nie trzeba przypisywać firewalla do interfejsu, ponieważ nadal ma działać w tym miejscu i w ten sposób, a tylko zakres jego pracy jest zmieniany.
R1:
set firewall name FIREWALL-OUT rule 30 action accept
set firewall name FIREWALL-OUT rule 30 protocol tcp
set firewall name FIREWALL-OUT rule 30 source port 443
commit
Program ping z wewnątrz nie osiągnie żadnego zewnętrznego celu, a traceroute zatrzyma się na routerze R1, ponieważ blokowane są pakiety protokołu ICMP, z których te programy korzystają [Obraz 9-4].
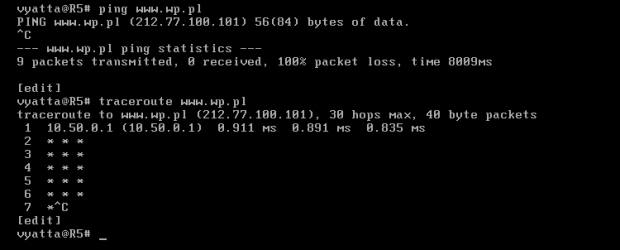
Obraz 9-4: Próba kontaktu poprzez ping i traceroute
Jako, że mogą się przydać w celu diagnostycznym, można je odblokować, jednak zostanie to zrobione tylko dla komputera Host, maszyna Host WIN powinna nadal nie mieć możliwości odbierania pakietów ICMP.
Składnia użytych poleceń:
- 'set firewall name < nazwa> rule < numer> icmp type-name echo-reply' -definiuje adres pochodzenia pakietu dla określonej reguły. Adres może być adresem komputera, sieci lub zakresem. Można także użyć odwrotności oraz wpisywać porty w liście, oddzielone przecinkami.
- 'set firewall name < nazwa> rule < numer> destination address < adres>' - określa adres docelowy. Adres może być adresem IP, adresem sieci lub zakresem. Można użyć także odwrotności.
R1:
set firewall name FIREWALL-OUT rule 40 action accept
set firewall name FIREWALL-OUT rule 40 protocol icmp
set firewall name FIREWALL-OUT rule 40 icmp type-name echo-reply
set firewall name FIREWALL-OUT rule 40 destination address 10.50.0.2
commit
Efekt został osiągnięty, lecz w trochę niewłaściwy sposób. Pakiety ICMP będą nadal wysyłane przez maszynę Host WIN oraz odbierane przez komputer docelowy, co udowadnia Tshark działający na interfejsie eth0 routera R1 [Obraz 9-5], lecz pakiety Echo Reply nie wrócą, ponieważ będą blokowane na interfejsie eth1. Aby niepotrzebnie nie generować ruchu, pakiety ICMP Echo Request powinny być wycięte na interfejsie eth1 komputera R1, ale w kierunku "in". Całą operacją pokazuje kolejny przykład.

Obraz 9-5: Przepływ pakietów ICMP przez interfejs eth0 routera R1
Patrząc na powyższy obraz może dziwić adres 192.168.223.3 zamiast 10.50.0.3. Przypominając zasadę działania maskarady (NAT): pakiety kierowane z komputera Host WIN (10.50.0.3), są maskowane przez adres interfejsu eth0 maszyny R1 (192.168.223.3), więc wracając, zachodzi sytuacja odwrotna i adresy są z powrotem tłumaczone na poprawne.
Aby było bardziej elegancko, zostanie usunięta część reguły nr 40, zezwalająca tylko na adres 10.50.0.2, więc odblokowane zostaną wszystkie pakiety powrotne, czyli Echo Reply. Odwrotnie niż w firewallu w kierunku "out", w tym domyślną akcją będzie akceptacja pakietów, a zablokowane zostaną tylko pakiety ICMP Echo Request kumputera Host WIN.
R1:
delete firewall name FIREWALL-OUT rule 40 destination
set firewall name FIREWALL-IN default-action accept
set firewall name FIREWALL-IN rule 10 action drop
set firewall name FIREWALL-IN rule 10 protocol icmp
set firewall name FIREWALL-IN rule 10 icmp type-name echo-request
set firewall name FIREWALL-IN rule 10 source address 10.50.0.3
set interfaces ethernet eth1 firewall in name FIREWALL-IN
commit
Po wykonaniu powyższych operacji, pakiety ping docierające do routera R1 z komputera Host WIN będą odrzucane od razu na interfejsie eth1, a przy tym nie będzie konieczności dublowania reguł zezwalających na określony ruch w kierunku "in", dzięki domyślnej akcji określonej na akceptację.
Przydatny może się okazać także bezpieczny protokół SSH, który można wykorzystać w celu zdalnego logowania do komputera lub przesyłania danych. Zostanie on odblokowany tylko dla maszyny Host, a żeby użyć go w systemie Vyatta, trzeba uruchomić daemona SSH.
R1:
set service ssh
set firewall name FIREWALL-OUT rule 50 action accept
set firewall name FIREWALL-OUT rule 50 protocol tcp
set firewall name FIREWALL-OUT rule 50 destination port 22
set firewall name FIREWALL-OUT rule 50 destination address 10.50.0.2
commit
Obraz 9-6 przedstawia logowanie do Hosta z komputera fizycznego przy pomocy programu Putty. Aby przeprowadzić takie logowanie lub w jakikolwiek inny sposób osiągnąć maszynę Host z komputera fizycznego, niezbędne jest dodanie następującego wpisu routingu na nim: 'route add 10.50.0.0 mask 255.255.255.240 192.168.223.3'.
Obraz 9-6: Logowanie do komputera Host przy pomocy Putty
Komputery w sieci działają z wyznaczonymi usługami i są zabezpieczane na wypadek niepowołanego dostępu, jednak nadal nie są bezpieczne. Aby podnieść poziom bezpieczeństwa, zostaną zablokowane pakiety o stanie NEW z flagą TCP inną niż SYN, co zostanie dopisane jako pierwsza reguła w firewallu, ponieważ pakiety te mogą nieść potencjalne zagrożenie i muszą być wykluczone zanim któraś z następnych reguł je dopuści. Dodatkowo zostaną dopisane połączenia oznaczone jako ESTABLISHED i RELATED, gdyż są to połączenia nawiązane z maszyn wewnątrz sieci. Zostaną one dodane na koniec, aby dopuszczane były tylko pakiety sprawdzone już przez poprzednie reguły.
Składnia użytych poleceń:
- 'set firewall name < nazwa> rule < numer> state new enable' - określa stan filtrowanych pakietów.
- 'set firewall name < nazwa> rule < numer> tcp flags !SYN' -definiuje ustawione flagi pakietu. Mogą być odwrotnością.
R1:
set firewall name FIREWALL-OUT rule 5 action drop
set firewall name FIREWALL-OUT rule 5 protocol tcp
set firewall name FIREWALL-OUT rule 5 state new enable
set firewall name FIREWALL-OUT rule 5 tcp flags !SYN
set firewall name FIREWALL-OUT rule 60 action accept
set firewall name FIREWALL-OUT rule 60 protocol tcp
set firewall name FIREWALL-OUT rule 60 state established enable
set firewall name FIREWALL-OUT rule 60 state related enable
commit
Lokalnie, router R1 również musi być zabezpieczony, dlatego dla niego też będzie działał firewall z domyślną akcją odrzucania pakietów. A potrzebne do jego funkcjonowania usługi należy odblokować. Oczywiście na początek trzeba dać mu dostęp do usługi DNS, a także umożliwić wysyłanie pakietów ICMP Echo Reply oraz odbieranie pakietów Echo Request, jednak, aby zapobiec powodzi pakietów ICMP (ang. ping flood), mogącej zapchać łącze lub przeciążyć słaby router, należy ograniczyć ich ilość w danym okresie czasowym. Dodatkowo odbieranie pakietów ICMP Echo Request będzie logowane do pliku.
Składnia użytych poleceń:
- 'set firewall name < nazwa> rule < numer> limit rate 2/second' - określa ilość przyjmowanych zapytań w czasie.
- 'set firewall name < nazwa> rule < numer> burst < liczba>' -definiuje maksymalną ilość zapytań w serii na okres czasu określony poprzednim poleceniem.
R1:
set firewall name FIREWALL-LOCAL rule 10 action accept
set firewall name FIREWALL-LOCAL rule 10 protocol udp
set firewall name FIREWALL-LOCAL rule 10 source port 53
set firewall name FIREWALL-LOCAL rule 20 action accept
set firewall name FIREWALL-LOCAL rule 20 protocol icmp
set firewall name FIREWALL-LOCAL rule 20 icmp type-name echo-reply
set firewall name FIREWALL-LOCAL rule 30 action accept
set firewall name FIREWALL-LOCAL rule 30 protocol icmp
set firewall name FIREWALL-LOCAL rule 30 icmp type-name echo-request
set firewall name FIREWALL-LOCAL rule 30 limit rate 2/second
set firewall name FIREWALL-LOCAL rule 30 limit burst 3
set firewall name FIREWALL-LOCAL rule 30 log enable
set interfaces ethernet eth0 firewall local name FIREWALL-LOCAL
commit
Podgląd pliku log można uruchomić wpisując polecenie 'show log' w trybie operacyjnym. Aby obejrzeć tylko końcową część należy wpisać 'show log tail'. W podglądzie można oglądać na żywo dodawane wpisy, a aby wyjść z niego, należy nacisnąć klawisze "CTRL + C", a następnie "Q". Na obrazie 9-7 pokazany jest wynik działania tego polecenia - odebrane zostały 4 pakiety od komputera fizycznego.
Obraz 9-7: Pakiety ICMP zapisane w pliku log
Z protokołów odblokowany zostanie jeszcze tylko SSH oraz dodane będzie zabezpieczenie takie jak w przypadku sieci, tj. blokowanie pakietów NEW ze stanem innym niż SYN oraz dopuszczone zostaną połączenia oznaczone jako ESTABLISHED i RELATED.
R1:
set firewall name FIREWALL-LOCAL rule 40 action accept
set firewall name FIREWALL-LOCAL rule 40 protocol tcp
set firewall name FIREWALL-LOCAL rule 40 destination port 22
set firewall name FIREWALL-LOCAL rule 5 action drop
set firewall name FIREWALL-LOCAL rule 5 protocol tcp
set firewall name FIREWALL-LOCAL rule 5 state new enable
set firewall name FIREWALL-LOCAL rule 5 tcp flags !SYN
set firewall name FIREWALL-LOCAL rule 50 action accept
set firewall name FIREWALL-LOCAL rule 50 protocol tcp
set firewall name FIREWALL-LOCAL rule 50 state established enable
set firewall name FIREWALL-LOCAL rule 50 state related enable
commit
W trybie operacyjnym w każdej chwili poleceniem 'show firewall' można wyświetlić stan firewalla. Na obrazie 9-8 jest pokazany stan firewalla lokalnego dla komputera R1
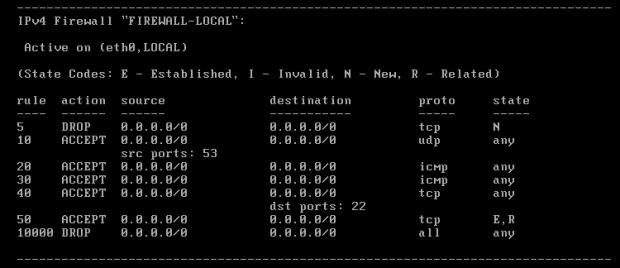
Obraz 9-8: Stan firewalla
Stan z detalami można wyświetlić poleceniem 'show firewall detail' w trybie operacyjnym lub podejrzeć konfigurację poleceniem 'show firewall' w trybie konfiguracyjnym.
Tak skonfigurowany firewall jest już przyzwoitym zabezpieczeniem, lecz nadal nie idealnym. Konfiguracja firewalla może przebiegać latami i zmieniać się w zależności od nowych zagrożeń oraz stanu wiedzy administratora, który go obsługuje.
10. IPS i filtrowanie ruchu webowego.
IPS.
System zapobiegania włamaniom (ang. Intrusion Prevention System, IPS) jest zabezpieczeniem sieci przed wrogimi atakami mającymi na celu m. in. przejęcie danych czy uniemożliwienie działania (DoS, ang. Denial of Service).
W systemie Vyatta, IPS bazuje na otwartym oprogramowaniu Snort, który działając w czasie rzeczywistym analizuje ruch sieciowy w poszukiwaniu charakterystycznych oznak danych ataków oraz złośliwych kodów, a następnie zapobiega im.
Web Filtering.
Filtrowanie ruchu webowego jest narzędziem, przy pomocy którego firmy, jak również użytkownicy indywidualni mogą blokować niepożądany ruch, dzięki czemu można zwiększyć produktywność w firmach, nie zezwalając użytkownikom na korzystanie z zajmujących serwisów, a w domach można chronić pociechy przed treściami dla dorosłych oraz tymi niosącymi przemoc.
10.1. Topologia.
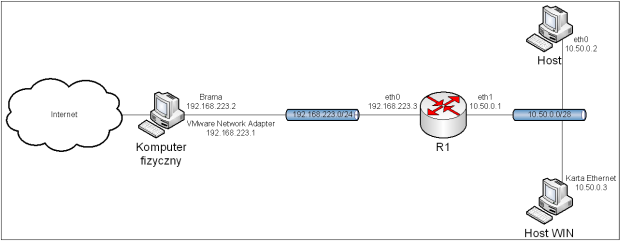
Obraz 10-1: Topologia sieci użytej w zadaniu
Komputer Host działa pod kontrolą systemu Vyatta, natomiast Host WIN pod kontrolą systemu Windows XP.
10.2. Przygotowanie wirtualnych sieci.
Wirtualne sieci zostały skonfigurowane identycznie jak w ćwiczeniu "9. Firewall".
10.3. Cel oraz założenia.
Celem niniejszego ćwiczenia jest konfiguracja systemu zapobiegania włamaniom, który wspomagać będzie firewall oraz filtrowanie ruchu webowego.
Aby w pełni wykorzystać możliwości zabezpieczeń przed intruzami, przydatna będzie konfiguracja zapory sieciowej.
10.4. Konfiguracja IPS.
Przed rozpoczęciem pracy należy wczytać zapisany stan sieci poleceniem 'load', gdyż topologia jest identyczna jak w ćwiczeniu "9. Firewall".
Poniższa konfiguracja dotyczy ograniczonej, darmowej wersji usługi, aby uzyskać wersję pełną trzeba wykupić Vyatta PLUS. Korzystając z wersji podstawowej uaktualnienia zagrożeń pojawiają się z 30 dniowym opóźnieniem.
Przed przystąpieniem do konfiguracji zaleca się rejestrację w serwisie snort.org w celu uzyskania kodu "oink", niezbędnego do automatycznej aktualizacji baz zagrożeń.
Składnia użytych poleceń:
- 'set content-inspection traffic-filter preset all' - określa rodzaj filtrowanego ruchu.
- 'set content-inspection ips actions priority-1 drop' - definiuje akcję dla ruchu oznaczonego priorytetem 1.
- 'set content-inspection ips actions other pass' - definiuje akcję dla inego ruchu.
- 'set content-inspection ips auto-update oink-code < kod>' - określa kod przyznany z serwisu snort.org.
- 'set content-inspection ips auto-update update-hour 12' - definiuje godzinę automatycznej aktualizacji.
- 'set content-inspection ips modify-rules internal-network 10.50.0.0/28' - określa sieć domową, która będzie chroniona.
R1:
set content-inspection traffic-filter preset all
set content-inspection ips actions priority-1 drop
set content-inspection ips actions priority-2 alert
set content-inspection ips actions priority-3 alert
set content-inspection ips actions other pass
set content-inspection ips auto-update oink-code 8f8735edd95b1279c98e72ee00d79c15ad54d2a9
set content-inspection ips auto-update update-hour 12
set content-inspection ips modify-rules internal-network 10.50.0.0/28
commit
Klasyfikacja priorytetów znajduje się w pliku "classification.config", który można wyświetlić poleceniem 'cat /etc/snort/classification.config'.
Na obrazie 10-2 przedstawione jest podsumowanie działania IPS, obejmujące liczbę wystąpień zagrożeń z podziałem na klasy lub sygnatury. Wywołano je poleceniem 'show ips summary' na komputerze R1, w trybie operacyjnym.
Obraz 10-2: Podsumowanie działania IPS
Raz skonfigurowana usługa IPS będzie chroniła sieć od potencjalnych zagrożeń bez konieczności ingerowania w nią, a w połączeniu z firewallem pozwala na kompleksową ochronę.
10.5. Konfiguracja filtrowania ruchu webowego.
W pierwszym scenariuszu zostanie zablokowany dostęp z sieci 10.50.0.0/28 do domeny allegro.pl oraz do stron skategoryzowanych na czarnej liście jako reklamy oraz treści dla dorosłych. Aby baza czarnej listy była dostępna, na samym początku trzeba ją zaktualizować poleceniem 'update webproxy blacklists' w trybie operacyjnym. Blokada będzie działała w godzinach 9-17 i w tym czasie próba wejścia na określone domeny skończy się przekierowaniem na adres witryny firmowej.
Składnia użytych poleceń:
- 'set service webproxy listen-address < adres IP>' - określa adres interfejsu, na którym będzie nasłuchiwany ruch.
- 'set service webproxy url-filtering squidguard local-block allegro.pl' - definiuje blokowaną domenę.
- 'set service webproxy url-filtering squidguard block-category ads' -ustala blokowaną kategorię na reklamy.
- 'set service webproxy url-filtering squidguard redirect-url http://firmowa.pl' - określa przekierowanie.
- 'set service webproxy url-filtering time-period < nazwa> days all time < zakres>' - określa zakres czasowy działania filtra.
R1:
set service webproxy listen-address 10.50.0.1
set service webproxy url-filtering squidguard local-block allegro.pl
set service webproxy url-filtering squidguard block-category ads
set service webproxy url-filtering squidguard block-category porn
set service webproxy url-filtering squidguard redirect-url http://firmowa.pl
set service webproxy url-filtering squidguard time-period OKRES days all time 09:00-17:00
commit
W kolejnym scenariuszu działanie będzie odwrotne, tj. domyślnie cały ruch webowy będzie blokowany, a dopuszczona zostanie tylko domena witryny firmowej.
Składnia użytych poleceń:
- 'set service webproxy url-filtering squidguard default-action block' -definiuje domyślną akcję.
- 'set service webproxy url-filtering squidguard local-ok firmowa.pl' - definiuje dozwoloną domenę.
R1:
delete service webproxy
set service webproxy listen-address 10.50.0.1
set service webproxy url-filtering squidguard default-action block
set service webproxy url-filtering squidguard local-ok firmowa.pl
set service webproxy url-filtering squidguard redirect-url http://firmowa.pl
set service webproxy url-filtering time-period OKRES days all time 09:00-17:00
commit
Jak widać konfiguracja filtra webowego jest prosta i szybka, a skutki są natychmiastowe. Należy tylko uważać, by nie przesadzić, bo może się zdarzyć, że część zawartości witryny leży w innej domenie, a wycięcie ruchu do zbyt wielu domen może być uciążliwe dla użytkowników w sieci.
11. Load Balancing i Failover.
Load Balancing.
Jest to technika równoważenia obciążenia na dwa lub więcej łącz. Obciążenie jest rozkładane po równo na każdy z podłączonych interfejsów, chyba, że określone są wagi. W razie awarii na jednym z łącz, jest ono wykluczane z puli, aż do ustąpienia niesprawności.
Failover.
Jest trybem pracy dającym możliwość przełączania się na inny zasób w razie wystąpienia awarii. Gdy jedno z łącz lub węzłów przestanie odpowiadać, ruch automatycznie jest przełączany na drugi węzeł lub łącze. W podstawowej wersji wystarczą dwa łącza, aby go włączyć.
Istnieje jeszcze failover z zachowaniem stanu łącza, który może takie przełączenie wykonać niezauważalnie, nie powodując zerwania trwającego połączenia. Przykładowo prowadząc rozmowę VoIP, zwykły failover zerwie połączenie, a opcja z zachowaniem stanu łącza powinna zapewnić stałe jego trwanie, a zatem rozmowa powinna toczyć się dalej bez przeszkód. Dzieje się tak dlatego, ponieważ istnieją dwa węzły – jeden jest zapasowy. Działają one równolegle i są połączone ze sobą w celu wymiany informacji o stanie działania oraz połączenia. Gdy węzeł zapasowy stwierdzi, że jego sąsiad nie pracuje poprawnie, przejmuje jego ruch. W razie naprawy węzła głównego, przy włączonej pewnej opcji, o której będzie mowa poniżej, ruch automatycznie zaczyna płynąć przez niego.
11.1. Cel oraz założenia.
Celem ćwiczenia jest zapoznanie się z konfiguracją równoważenia obciążenia oraz failover w dwóch odmianach oraz zrozumienie ich działania, a także konieczności istnienia w niektórych sieciach.
11.2. Load Balancing i Failover.
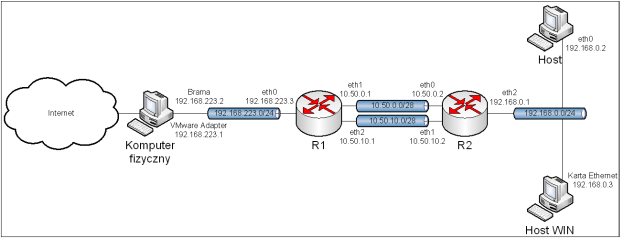
Obraz 11-1: Topologia sieci użytej w zadaniu
11.2.1. Przygotowanie wirtualnych sieci.
R1:
eth0 – NAT (VMnet8)
eth1 – VMnet2
eth2 – VMnet3
R2:
eth0 – VMnet2
eth1 – VMnet3
eth2 – VMnet4
Host:
eth0 – VMnet4
Host WIN:
Karta Ethernet – VMnet4
11.2.2. Konfiguracja.
Przed rozpoczęciem zostanie zainstalowany program Iptraf. Tak jak Tshark i Tcpdump, jest on snifferem. Jednak w odróżnieniu od nich, posiada interfejs graficzny oraz pokazuje zestawienie ilości pakietów na poszczególnych interfejsach, co będzie przydatne w niniejszym ćwiczeniu.
Aby go zainstalować, konieczne jest dopisanie adresu repozytorium do pliku "/etc/apt/sources.list", oraz pobranie aktualnej listy aplikacji, a następnie ściągnięcie programu Iptraf z tego repozytorium. Wszystkie poniższe polecenia będą wykonywane w trybie operacyjnym.
R2:
sudo chmod 666 /etc/apt/sources.list
sudo echo "deb http://ftp.pl.debian.org/debian/ stable main non-free contrib" >> /etc/apt/sources.list
sudo apt-get update
sudo apt-get install iptraf
Teraz należy przywrócić stan sieci poleceniem 'load'. Na komputerze R1 oraz Host zostanie przywrócony stan z ćwiczenia "9. Firewall", a na R2 z ćwiczenia "5. Routing statyczny". Wystarczy wprowadzić kilka poprawek.
R1:
set interfaces ethernet eth2 address 10.50.10.1/28
set protocols static route 192.168.0.0/24 next-hop 10.50.0.2
commit
R2:
delete interfaces ethernet eth1 address
set interfaces ethernet eth1 address 10.50.10.2/28
set interfaces ethernet eth2 address 192.168.0.1/24
commit
Host:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.2/24
set system gateway-address 192.168.0.1
commit
W opcjach protokołu TCP/IP na komputerze Host WIN należy wprowadzić adres 192.168.0.3 z maską 255.255.255.0 oraz bramę domyślną z adresem 192.168.0.1.
Na tą chwilę korzystając z Internetu na komputerach Host lub Host WIN, ruch będzie kierowany poprzez sieć 10.50.0.0/28, ponieważ komputer R2 ma ustawioną domyślną bramę na komputer z tej sieci. Scenariusz obejmie podstawowe równoważenie obciążenia, które będzie rozkładane na sieci 10.50.0.1/28 i 10.50.10.0/28, a następnie zostanie rozszerzony o kilka przydatnych funkcji.
Składnia użytych poleceń:
- 'set load-balancing wan interface-health < interfejs> nexthop < adres IP>' – określa adres kolejnego przeskoku dla sprawdzenia stanu.
- 'set load-balancing wan rule 10 interface < interfejs>' – definuje interfejs(y) na którym(których) będzie wykonywany load balancing.
- 'set load-balancing wan rule 10 inbound-interface < interfejs>' – określa interfejs, którym będzie dostarczany ruch do równoważenia.
R2:
set load-balancing wan interface-health eth0 nexthop 10.50.0.1
set load-balancing wan interface-health eth1 nexthop 10.50.10.1
set load-balancing wan rule 10 interface eth0
set load-balancing wan rule 10 interface eth1
set load-balancing wan rule 10 inbound-interface eth2
commit
Równoważenie ruchu powinno już działać, co można sprawdzić programem Iptraf zainstalowanym wcześniej. Należy wywołać go poleceniem 'sudo iptraf', nacisnąć jakikolwiek klawisz i wybrać opcję "Genereal interface statistics". Jest to podgląd na statystyki pakietów przepływających przez komputer R2. Ruch można wygenerować z maszyny Host lub Host WIN. Obraz 11-2 pokazuje przykładowe statystyki
Obraz 11-2: Podgląd ilości pakietów przepływających przez komputer R2
Dla łącz przez obie sieci zostaną ustawione adresy różnych serwerów, które będą pingowane w celu sprawdzenia działania tych łącz.
Składnia użytych poleceń:
- 'set load-balancing wan interface-health < interfejs> failure-count < liczba>' – określa liczbę nieudanych sprawdzeń stanu, po którum interfejs zostanie wyłączony z równoważenia obciążenia.
- 'set load-balancing wan interface-health < interfejs> test < numer> target < adres IP>' – określa adres, który będzie sprawdzany w celu wykrycia awarii łącza.
- 'set load-balancing wan interface-health < interfejs> test < numer> type < typ>' – definiuje typ testu.
R2:
set protocols static route 8.8.8.8/32 next-hop 10.50.0.1
set protocols static route 8.8.4.4/32 next-hop 10.50.10.1
set load-balancing wan interface-health eth0 failure-count 8
set load-balancing wan interface-health eth0 test 10 target 8.8.8.8
set load-balancing wan interface-health eth0 test 10 type ping
set load-balancing wan interface-health eth1 failure-count 8
set load-balancing wan interface-health eth1 test 10 target 8.8.4.4
set load-balancing wan interface-health eth1 test 10 type ping
commit
Po powyższej konfiguracji, co kilka sekund przy użyciu protokołu ICMP są sprawdzane oba łącza, co można sprawdzić programem Iptraf, wybierając opcję "IP traffic monitor" [Obraz 11-3]. W razie awarii któregoś z łącz, ruch automatycznie będzie płynął tylko tym drugim. To już jest na pewien sposób failover.
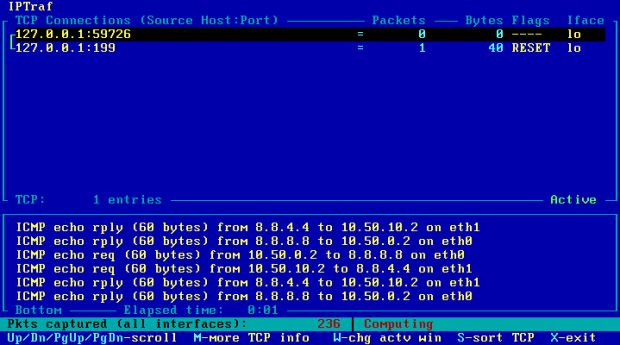
Obraz 11-3: Podgląd ruchu przepływającego przez komputer R2
Do konfiguracji można także wprowadzić wagi, dzięki którym ruch będzie dzielony na oba interfejsy nierówno.
Składnia użytych poleceń:
- 'set load-balancing wan rule < numer> interface < interfejs> weight < liczba>' – określa wagę łącza.
R2:
delete load-balancing wan rule 10
set load-balancing wan rule 10 interface eth0 weight 2
set load-balancing wan rule 10 interface eth1 weight 8
set load-balancing wan rule 10 inbound-interface eth2
commit
Iptraf pokazuje rozbieżność – to przez sieć 10.50.10.0/28 jest przesyłana większość ruchu [Obraz 11-4].
Obraz 11-4: Podgląd ilości pakietów przepływających przez komputer R2
W razie awarii na którymś krańcu sieci 10.50.10.0/28, ruch po chwili będzie kierowany przez sieć 10.50.0.0/28 [Obraz 11-5]. Awaria zostanie zasymulowana przez usunięcie adresu z interfejsu eth1 komputera R2.
R2:
delete interfaces ethernet eth1 address
commit
Obraz 11-5: Podgląd ilości pakietów przepływających przez komputer R2
Jak widać failover działa z pewnym opóźnieniem, ale nie na tyle dużym żeby był to problem. Związek z tym ma ilość sprawdzeń łącza pakietami ICMP. Chwilę po przywróceniu do poprawnego działania interfejsu eth2 komputera R2 pakiety będą znowu przesyłane przez sieć preferowaną, czyli 10.50.10.0/28.
11.3. Failover z zachowaniem stanu łącza.
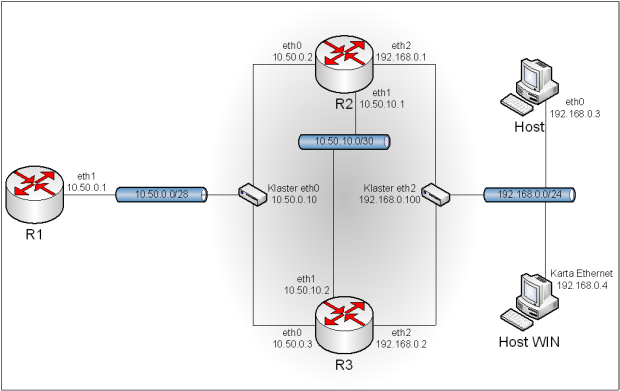
Obraz 11-6: Topologia sieci użytej w zadaniu
Połączenie z komputerem fizycznym i Internetem zostało usunięte z powodu zbyt dużego rozmiaru obrazu, jednak w konfiguracji się znajdzie.
11.3.1. Przygotowanie wirtualnych sieci.
R1:
eth0 – NAT (VMnet8)
eth1 – VMnet2
R2:
eth0 – VMnet2
eth1 – VMnet3
eth2 – VMnet4
R3:
eth0 – VMnet2
eth1 – VMnet3
eth2 – VMnet4
Host:
eth0 – VMnet4
Host WIN:
Karta Ethernet – VMnet4
11.3.2. Konfiguracja.
Po załadowaniu zapisanego stanu trzeba będzie uczynić kilka zmian.
R1:
set protocols static route 192.168.0.0/24 next-hop 10.50.0.10
commit
R2:
delete interfaces ethernet eth1 address
set interfaces ethernet eth1 address 10.50.10.1/30
set interfaces ethernet eth2 address 192.168.0.1/24
commit
R3:
delete interfaces
set interfaces ethernet eth0 address 10.50.0.3/28
set interfaces ethernet eth1 address 10.50.10.2/30
set interfaces ethernet eth2 address 192.168.0.2/24
set system gateway-address 10.50.0.1
commit
Host:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.3/24
set system gateway-address 192.168.0.100
commit
Jak widać powyżej bramy komputerów Host oraz Host WIN muszą być skierowane na wirtualny adres, który będzie adresem klastra, a na maszynie R1 musi istnieć wpis routingu statycznego kierujący na wirtualny adres z drugiej strony klastra. Dodatkowo na maszynie Host WIN trzeba zmienić adres na 192.168.0.4.
Wykonanie failover z zachowaniem stanu łącza jest trochę bardziej pracochłonne niż wykonanie bezstanowego failover, ale daje jedną, sporą korzyść – w razie awarii komputera, przez który przepływa ruch, nie jest zrywane bieżące połączenie, a zatem przy pobieraniu jakiegoś pliku praktycznie nie da się zauważyć tej awarii.
Najpierw zostanie utworzony firewall, który będzie dbał o to, by w tym samym czasie tylko przez jeden komputer przepływał ruch. Firewall będzie identyczny na komputerach R2 i R3.
R2, R3:
set firewall name DO_SIECI default-action drop
set firewall name DO_SIECI rule 10 action accept
set firewall name DO_SIECI rule 10 state established enable
set firewall name DO_SIECI rule 20 action accept
set firewall name DO_SIECI rule 20 destination address 192.168.0.0/24
set firewall name DO_SIECI rule 20 destination port 80
set firewall name DO_SIECI rule 20 protocol tcp
set firewall name DO_SIECI rule 20 state new enable
set firewall name OD_SIECI default-action accept
set firewall name OD_SIECI rule 10 action drop
set firewall name OD_SIECI rule 10 state invalid enable
set interfaces ethernet eth0 firewall in name DO_SIECI
set interfaces ethernet eth2 firewall in name OD_SIECI
commit
Następnie oba te komputery (R2 i R3) muszą zostać połączone w klaster, działający jak jedna maszyna z wirtualnymi interfejsami. To on będzie dbał o przełączanie ruchu w razie awarii jednego z jego węzłów. O awarii dowie się, gdy któryś z monitorowanych adresów przestanie odpowiadać na zapytania ICMP. Konfiguracja klastra będzie identyczna na komputerach R2 i R3.
Składnia użytych poleceń:
- 'set cluster group < nazwa> auto-failback < wartość logiczna>' – tworzy grupę o podanej nazwie oraz określa, że jeśli węzeł główny jest dostępny ponownie po awarii, to ruch ma być przełączony na niego.
- 'set cluster group < nazwa> monitor < adres IP>' – określa adres węzła monitorującego działanie klastra.
- 'set cluster group < nazwa> service < adres IP/maska/interfejs>' – definiuje wirtualny adres pod jakim będzie dostępny klaster.
- 'set cluster interface < interfejs>' – określa interfejs na którym będą przesyłane wiadomości monitorujące (heartbeat) działanie drugiego komputera w klastrze.
- 'set cluster dead-interval < liczba>' –określa po jakim czasie drugi komputer w klastrze ma być uznany za niesprawny (w milisekundach).
- 'set cluster keepalive-interval < liczba>' –określa, co ile milisekund ma być wysyłana wiadomość heartbeat.
- 'set cluster monitor-dead-interval < liczba>' – określa po jakim czasie węzeł monitorujący ma zostać uznany za niesprawny (w ms).
- 'set cluster pre-shared-secret < nazwa>' –definuje klucz uwierzytelniania.
R2, R3:
set cluster group GRUPA auto-failback true
set cluster group GRUPA monitor 10.50.0.1
set cluster group GRUPA monitor 192.168.0.3
set cluster group GRUPA primary R2
set cluster group GRUPA secondary R3
set cluster group GRUPA service 10.50.0.10/28/eth0
set cluster group GRUPA service 192.168.0.100/24/eth2
set cluster interface eth1
set cluster dead-interval 5000
set cluster keepalive-interval 1000
set cluster monitor-dead-interval 3000
set cluster pre-shared-secret klucz
commit
Dla ułatwienia topologii (oraz jej obrazu), między komputerami R1, a R2 i R3 jest tylko jedno łącze. W rzeczywistej sytuacji klaster może być podłączony do kilku dostawców Internetu.
Na koniec trzeba zapewnić synchronizację, aby połączenia nie były zrywane. Zapewnia to moduł Conntrack. Ta część także będzie wspólna dla obu węzłów.
Składnia użytych poleceń:
- 'set service conntrack-sync failover-mechanism cluster group < nazwa>' – definuje grupę dla której ma być wykonywana synchronizacja pakietów.
- 'set service conntrack-sync interface < interfejs>' – określa interfejs, którym będzie synchronizowane połączenie.
R2, R3:
set service conntrack-sync failover-mechanism cluster group GRUPA
set service conntrack-sync interface eth1
commit
Obraz 11-7 pokazuje status klastra na komputerze R2. Oba komputery działają, R2 jest aktywny, a R3 oczekuje. Oba monitorowane adresy są osiągalne.
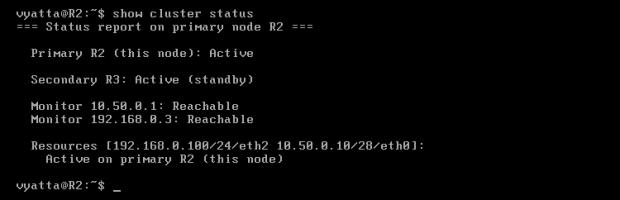
Obraz 11-7: Status klastra na komputerze R2 – oba komputery aktywne
Aby zobaczyć nie tylko status, a również pracę failover, dobrze jest włączyć pobieranie dużego pliku na komputerze Host lub Host WIN i monitorować pracę interfejsów programem Iperf.
Do wywołania awarii na węźle głównym (R2) wystarczy zaprzęgnąć zaporę sieciową.
R2
set firewall name BLOKADA default-action drop
set interfaces ethernet eth0 firewall local name BLOKADA
commit
Po uruchomieniu tej zapory status, jak i aktywny węzeł, automatycznie powinien się zmienić [Obraz 11-8], a ruch przepływający do tej pory przez interfejsy eth0 i eth2 komputera R2 powinien popłynąć tymi samymi interfejsami maszyny R3.
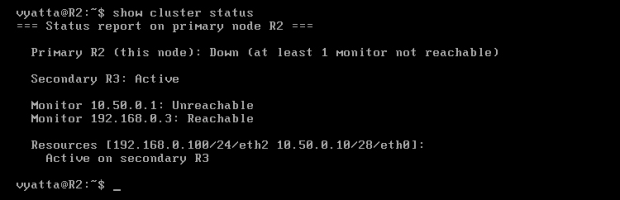
Obraz 11-8: Status klastra na komputerze R2 – tylko R3 aktywny
Failover wymaga dwóch maszyn przekazujących ruch, ale jest dobrym rozwiązaniem dla osób lub firm, które mają konieczność szybkiego i niewidocznego przełączania między łączami przy zachowaniu stanu połączenia.
12. QoS.
Quality of Service jest zbiorem usług pozwalających na zarządzanie jakością oraz przepływem dostarczanego ruchu, wedle zapotrzebowania i aktualnych wymagań. Dzięki QoS istnieje możliwość sprawiedliwego podziału pasma, priorytetyzacja pewnych usług, ograniczanie przepustowości, a także kolejkowanie ruchu oraz odrzucanie ruchu nadmiarowego.
Określanie priorytetów ruchu jest możliwe dzięki usługom zróżnicowanym (DiffServ, ang. Differentiated Services), które określają ważność danej klasy ruchu ustawiając sześć bitów w polu TOS (ang. Type Of Service) nagłówka IP. Tak oznaczone pakiety mogą być odpowiednio traktowane i przesyłane w zależności od nadanych im właściwości.
Domyślnie kształtowanie ruchu opiera się o politykę sprawiedliwej kolejki (ang. fair queue) wprowadzaną przez algorytm SFQ (ang. Stochastic Fairness Queuing), wraz z dzieleniem ruchu po równo na każdą maszynę zgodnie z algorytmem Token Bucket.
12.1. Topologia.
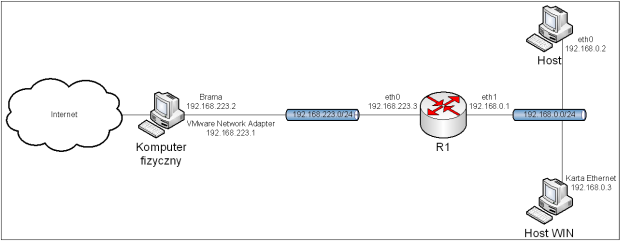
Obraz 12-1: Topologia sieci użytej w zadaniu
12.2. Cel oraz założenia.
Celem ćwiczenia jest ukazanie możliwości kształtowania ruchu w sieci Ethernet w oparciu o wbudowany system kolejkowania Token Bucket.
Do podglądu ruchu, a pośrednio do rozwiązywania problemów, może być przydatny program Iptraf, którego instalacja została przeprowadzona w ćwiczeniu "11. Load Balancing i Failover".
Do szerszego wykorzystania QoS niezbędna może okazać się wiedza o działaniu algorytmów takich jak: Token Bucket, SFQ, FIFO, Round-Robin, RED oraz WRED, a także dobra znajomość DiffServ.
12.3. Przygotowanie wirtualnych sieci.
R1:
eth0 - NAT (VMnet8)
eth1 - VMnet2
Host:
eth0 - VMnet2
Host WIN:
Karta Ethernet - VMnet2
12.4. Konfiguracja.
Po wczytaniu ostatniej zapisanej konfiguracji, należy wprowadzić kilka poprawek.
R1:
delete interfaces ethernet eth1 address
set interfaces ethernet eth1 address 192.168.0.1/24
commit
Host:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.2/24
set system gateway-address 192.168.0.1
commit
Analogicznie, na komputerze Host WIN, należy zmienić adres karty sieciowej na 192.168.0.3, a adres bramy na 192.168.0.1.
Ruch będzie kierowany zgodnie z następującym scenariuszem: komputer Host o adresie MAC 00:0c:29:ee:a3:fe będzie miał gwarantowane 65% szybkości łącza, a maszyna Host WIN o adresie MAC 00:0c:29:a9:90:7c będzie miała gwarantowane 25%. Każdy z nich będzie mógł wykorzystać do 95% łącza, a protokół SSL będzie posiadał priorytet "krytyczny", dzięki czemu nie będzie na nim opóźnień.
Składnia użytych poleceń:
- 'set traffic-policy shaper < nazwa> bandwidth < wartość>' - ustala szybkość łącza automatycznie, w kilobitach lub innej jednostce (wymagana jednostka).
- 'set traffic-policy shaper < nazwa> class < numer> match < nazwa> ip destination port < numer>' -definiuje port klasy ruchu.
- 'set traffic-policy shaper < nazwa> class < numer> set-dscp < wartość>' -określa priorytet dla klasy ruchu.
- 'set traffic-policy shaper < nazwa> class < numer> bandwidth < wartość>' -definiuje gwarantowaną przepływność ruchu dla klasy, wyrażoną w procentach, kilobitach lub innej jednostce.
- 'set traffic-policy shaper < nazwa> class < numer> ceiling < wartość>' -definiuje maksymalną przepływność ruchu dla klasy, wyrażoną w procentach, kilobitach lub innej jednostce.
- 'set traffic-policy shaper < nazwa> class < numer> match < nazwa> ip destination address < adres sieci>' -określa adres sieci lub hosta (maska 32) dla danej klasy ruchu.
- 'set traffic-policy shaper < nazwa> default bandwidth < wartość>' - definiuje gwarantowaną przepływność ruchu dla klasy domyślnej, wyrażoną w procentach, kilobitach lub innej jednostce.
- 'set traffic-policy shaper < nazwa> default ceiling < wartość>' - definiuje maksymalną przepływność ruchu dla klasy domyślnej, wyrażoną w procentach, kilobitach lub innej jednostce.
R1:
set traffic-policy shaper PODZIAL bandwidth 2048
set traffic-policy shaper PODZIAL class 5 match DOPASOWANIE ip destination port 443
set traffic-policy shaper PODZIAL class 5 set-dscp critical
set traffic-policy shaper PODZIAL class 10 bandwidth 65%
set traffic-policy shaper PODZIAL class 10 ceiling 95%
set traffic-policy shaper PODZIAL class 10 match DOPASOWANIE ip destination address 192.168.0.2/32
set traffic-policy shaper PODZIAL class 20 bandwidth 25%
set traffic-policy shaper PODZIAL class 20 ceiling 95%
set traffic-policy shaper PODZIAL class 20 match DOPASOWANIE ip destination address 192.168.0.3/32
set traffic-policy shaper PODZIAL default bandwidth 100%
set traffic-policy shaper PODZIAL default ceiling 100%
set interfaces ethernet eth1 traffic-policy out PODZIAL
commit
Aby sprawdzić czy klasyfikacja ruchu działa prawidłowo, wystarczy na komputerach Host i Host WIN w tym samym czasie włączyć pobieranie jakiegoś pliku. Prędkości na tych maszynach powinny oscylować wokół ustalonych, co widać na obrazach 12-2 oraz 12-3.
Obraz 12-2: Pobieranie pliku na komputerze Host
Obraz 12-3: Pobieranie pliku na komputerze Host WIN
Po chwili równoległego pobierania na obu maszynach, poleceniem 'show queueing ethernet' (w trybie operacyjnym na komputerze R1) można wyświetlić właściwości kolejek. Obraz 12-4 przedstawia te właściwości, a w nich m. in. ilość przesłanych oraz zakolejkowanych pakietów dla każdej z klas. Klasa "root" jest główną klasą danej polityki, a klasa "21" jest klasą domyślną.
Obraz 12-4: Właściwości kolejki na maszynie R1
Oczywiście po wyłączeniu pobierania na jednym z komputerów, drugi będzie osiągał do 95% ustalonej prędkości łącza.
Zarządzanie ruchem może bardzo ułatwić życie, szczególnie w dużych sieciach, w sieciach, gdzie jakiś ruch musi być priorytetowany, a także w sieciach domowych, gdzie korzysta się intensywnie z Internetu oraz programów P2P, które potrafią całkowicie zapchać łącze.
Podsumowanie.
Po wykonaniu tych ćwiczeń, system Vyatta można określić jako prosty w konfiguracji i nie sprawiający zbyt wielu problemów, oczywiście pod warunkiem uważnego wprowadzania poleceń oraz znajomości zagadnień związanych z konfigurowaną usługą.
W wykonanych ćwiczeniach przedstawione zostały przykłady konfiguracji usług i protokołów w przejrzysty sposób, tłumacząc ich działanie, możliwe problemy oraz sposób ich rozwiązania. W zadaniach tych znalazła się dodatkowo skrócona teoria dotycząca konfigurowanego protokołu czy usługi, wyjaśniająca w jaki sposób zachodzi komunikacja między konfigurowanymi komputerami. Oczywiście, ćwiczenia przedstawione w tej pracy nie wyczerpują możliwości systemu; są one tylko częścią jego zdolności i metod konfiguracji, gdyż praca ta musiała mieć swój koniec.
Vyatta radzi sobie znakomicie jako router softwarowy, obsługujący najpopularniejsze protokoły routingu, jak RIP, OSPF oraz BGP. Jest przystosowana do świadczenia wielu usług w sieci, takich jak DHCP, IPS, Load Balancing, Failover oraz QoS, a także innych, nieopisanych w tej pracy. Vyatta także dobrze się konfiguruje do działania jako firewall.
Metoda wprowadzania komend do systemu jest prosta i przejrzysta, a drzewo konfiguracji ułatwia szybkie ogarnięcie ustawień systemu. Główna zaletą systemu Vyatta jest to, że jest on darmowy w wersji Core, która to wystarczy do zarządzania całkiem skomplikowaną siecią, a do tego nie ma on ograniczeń narzucanych przez sprzęt jak ma to miejsce w routerach sprzętowych.
Dzięki tym wszystkim funkcjom system ten nadaje się do zarządzania sieciami stawiającymi bardzo różne wymagania. Vyatta poradzi sobie zarówno w małej sieci, działając jako router RIP, jak i w bardzo dużej sieci, gdzie będzie potrzebna jako router BGP, OSPF, a także będzie udostępniała zasoby oraz usługi na zewnątrz (hosting). Dodatkowo Vyatta jest ciągle rozwijana, jej kod jest poprawiany na bieżąco, a co kilka(naście) miesięcy wychodzi nowa wersja. Dzięki prostocie konfiguracji oraz jądrze Linux, przez które jest stabilna i wydajna, system ten ma szansę stać się jednym z popularniejszych systemów obsługujących sieci domowe, a także firmowe o różnych rozmiarach i stopniu skomplikowania.
Od autora: wyrażam zgodę na nieodpłatne powielanie artykułu lub jego części jedynie w celach dydaktycznych, pod warunkiem umieszczenia tytułu artykułu oraz imienia i nazwiska autora, a także źródła oryginalnej publikacji: TwojePC.pl. W przypadku chęci wykorzystania dokumentu lub jego części w inny sposób proszę o kontakt ze mną lub redaktorem naczelnym TwojePC.pl.
|