Techinka: Konfiguracja systemu Vyatta w ćwiczeniach
Autor: Łukasz Łaciak | Data: 09/06/11
| |
|
11. Load Balancing i Failover.
Load Balancing.
Jest to technika równoważenia obciążenia na dwa lub więcej łącz. Obciążenie jest rozkładane po równo na każdy z podłączonych interfejsów, chyba, że określone są wagi. W razie awarii na jednym z łącz, jest ono wykluczane z puli, aż do ustąpienia niesprawności.
Failover.
Jest trybem pracy dającym możliwość przełączania się na inny zasób w razie wystąpienia awarii. Gdy jedno z łącz lub węzłów przestanie odpowiadać, ruch automatycznie jest przełączany na drugi węzeł lub łącze. W podstawowej wersji wystarczą dwa łącza, aby go włączyć.
Istnieje jeszcze failover z zachowaniem stanu łącza, który może takie przełączenie wykonać niezauważalnie, nie powodując zerwania trwającego połączenia. Przykładowo prowadząc rozmowę VoIP, zwykły failover zerwie połączenie, a opcja z zachowaniem stanu łącza powinna zapewnić stałe jego trwanie, a zatem rozmowa powinna toczyć się dalej bez przeszkód. Dzieje się tak dlatego, ponieważ istnieją dwa węzły – jeden jest zapasowy. Działają one równolegle i są połączone ze sobą w celu wymiany informacji o stanie działania oraz połączenia. Gdy węzeł zapasowy stwierdzi, że jego sąsiad nie pracuje poprawnie, przejmuje jego ruch. W razie naprawy węzła głównego, przy włączonej pewnej opcji, o której będzie mowa poniżej, ruch automatycznie zaczyna płynąć przez niego.
11.1. Cel oraz założenia.
Celem ćwiczenia jest zapoznanie się z konfiguracją równoważenia obciążenia oraz failover w dwóch odmianach oraz zrozumienie ich działania, a także konieczności istnienia w niektórych sieciach.
11.2. Load Balancing i Failover.
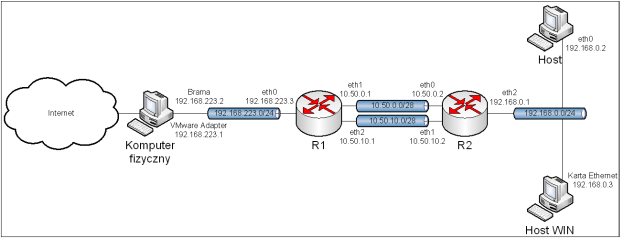
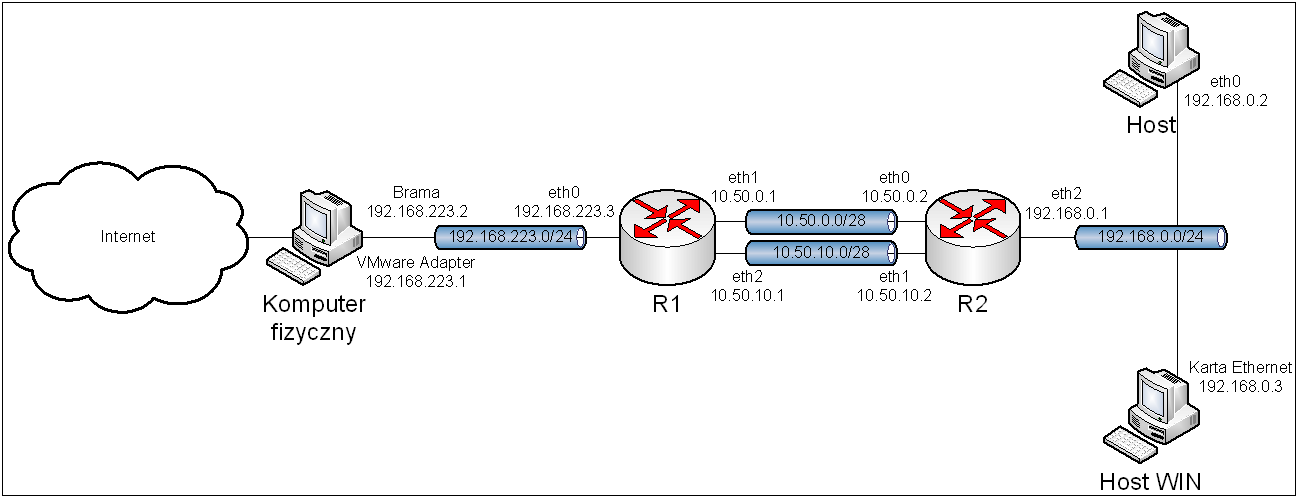
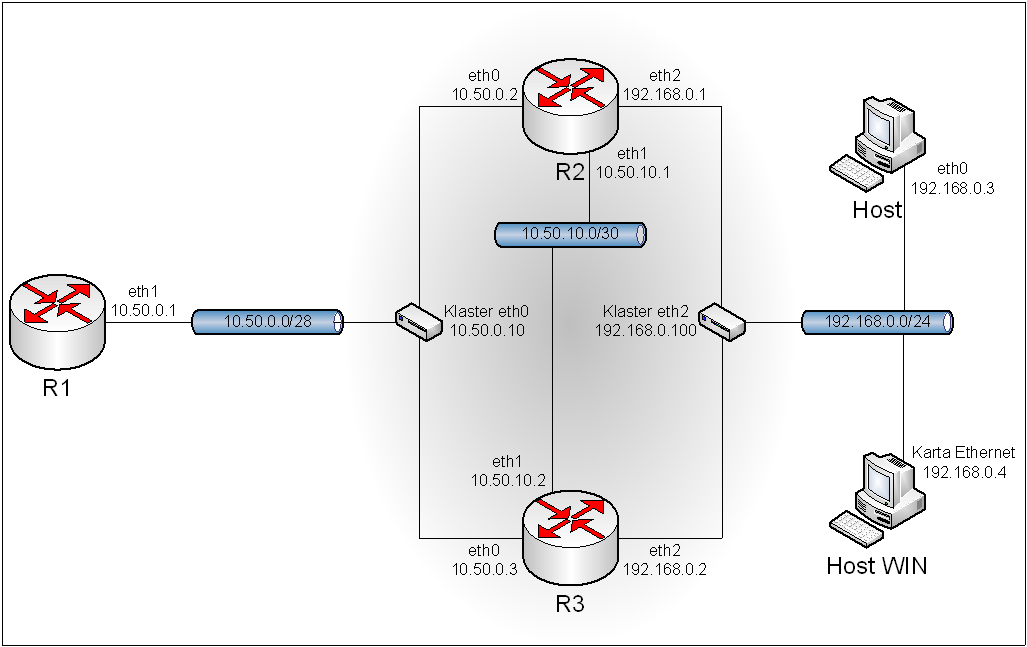
Obraz 11-1: Topologia sieci użytej w zadaniu
11.2.1. Przygotowanie wirtualnych sieci.
R1:
eth0 – NAT (VMnet8)
eth1 – VMnet2
eth2 – VMnet3
R2:
eth0 – VMnet2
eth1 – VMnet3
eth2 – VMnet4
Host:
eth0 – VMnet4
Host WIN:
Karta Ethernet – VMnet4
11.2.2. Konfiguracja.
Przed rozpoczęciem zostanie zainstalowany program Iptraf. Tak jak Tshark i Tcpdump, jest on snifferem. Jednak w odróżnieniu od nich, posiada interfejs graficzny oraz pokazuje zestawienie ilości pakietów na poszczególnych interfejsach, co będzie przydatne w niniejszym ćwiczeniu.
Aby go zainstalować, konieczne jest dopisanie adresu repozytorium do pliku "/etc/apt/sources.list", oraz pobranie aktualnej listy aplikacji, a następnie ściągnięcie programu Iptraf z tego repozytorium. Wszystkie poniższe polecenia będą wykonywane w trybie operacyjnym.
R2:
sudo chmod 666 /etc/apt/sources.list
sudo echo "deb http://ftp.pl.debian.org/debian/ stable main non-free contrib" >> /etc/apt/sources.list
sudo apt-get update
sudo apt-get install iptraf
Teraz należy przywrócić stan sieci poleceniem 'load'. Na komputerze R1 oraz Host zostanie przywrócony stan z ćwiczenia "9. Firewall", a na R2 z ćwiczenia "5. Routing statyczny". Wystarczy wprowadzić kilka poprawek.
R1:
set interfaces ethernet eth2 address 10.50.10.1/28
set protocols static route 192.168.0.0/24 next-hop 10.50.0.2
commit
R2:
delete interfaces ethernet eth1 address
set interfaces ethernet eth1 address 10.50.10.2/28
set interfaces ethernet eth2 address 192.168.0.1/24
commit
Host:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.2/24
set system gateway-address 192.168.0.1
commit
W opcjach protokołu TCP/IP na komputerze Host WIN należy wprowadzić adres 192.168.0.3 z maską 255.255.255.0 oraz bramę domyślną z adresem 192.168.0.1.
Na tą chwilę korzystając z Internetu na komputerach Host lub Host WIN, ruch będzie kierowany poprzez sieć 10.50.0.0/28, ponieważ komputer R2 ma ustawioną domyślną bramę na komputer z tej sieci. Scenariusz obejmie podstawowe równoważenie obciążenia, które będzie rozkładane na sieci 10.50.0.1/28 i 10.50.10.0/28, a następnie zostanie rozszerzony o kilka przydatnych funkcji.
Składnia użytych poleceń:
- 'set load-balancing wan interface-health < interfejs> nexthop < adres IP>' – określa adres kolejnego przeskoku dla sprawdzenia stanu.
- 'set load-balancing wan rule 10 interface < interfejs>' – definuje interfejs(y) na którym(których) będzie wykonywany load balancing.
- 'set load-balancing wan rule 10 inbound-interface < interfejs>' – określa interfejs, którym będzie dostarczany ruch do równoważenia.
R2:
set load-balancing wan interface-health eth0 nexthop 10.50.0.1
set load-balancing wan interface-health eth1 nexthop 10.50.10.1
set load-balancing wan rule 10 interface eth0
set load-balancing wan rule 10 interface eth1
set load-balancing wan rule 10 inbound-interface eth2
commit
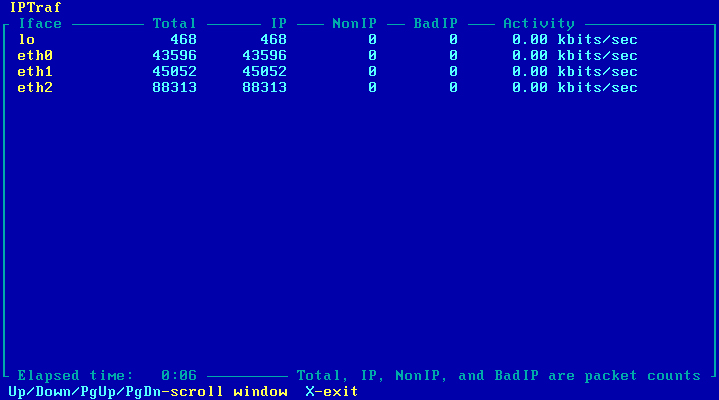
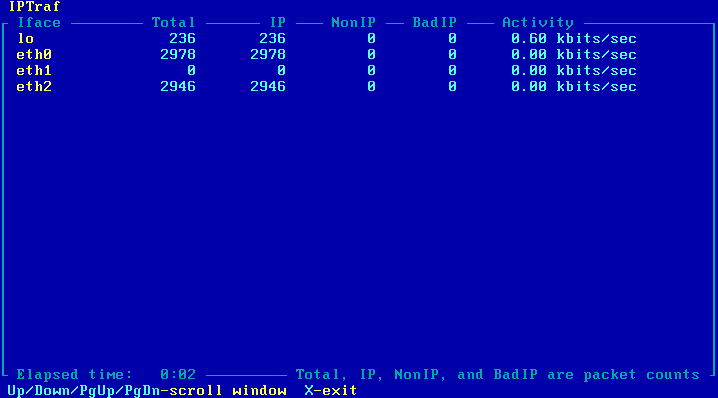
Równoważenie ruchu powinno już działać, co można sprawdzić programem Iptraf zainstalowanym wcześniej. Należy wywołać go poleceniem 'sudo iptraf', nacisnąć jakikolwiek klawisz i wybrać opcję "Genereal interface statistics". Jest to podgląd na statystyki pakietów przepływających przez komputer R2. Ruch można wygenerować z maszyny Host lub Host WIN. Obraz 11-2 pokazuje przykładowe statystyki
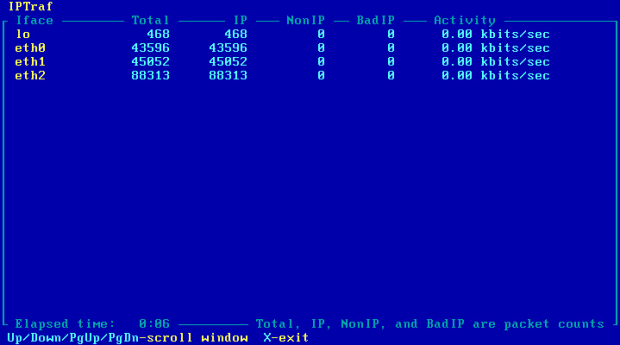
Obraz 11-2: Podgląd ilości pakietów przepływających przez komputer R2
Dla łącz przez obie sieci zostaną ustawione adresy różnych serwerów, które będą pingowane w celu sprawdzenia działania tych łącz.
Składnia użytych poleceń:
- 'set load-balancing wan interface-health < interfejs> failure-count < liczba>' – określa liczbę nieudanych sprawdzeń stanu, po którum interfejs zostanie wyłączony z równoważenia obciążenia.
- 'set load-balancing wan interface-health < interfejs> test < numer> target < adres IP>' – określa adres, który będzie sprawdzany w celu wykrycia awarii łącza.
- 'set load-balancing wan interface-health < interfejs> test < numer> type < typ>' – definiuje typ testu.
R2:
set protocols static route 8.8.8.8/32 next-hop 10.50.0.1
set protocols static route 8.8.4.4/32 next-hop 10.50.10.1
set load-balancing wan interface-health eth0 failure-count 8
set load-balancing wan interface-health eth0 test 10 target 8.8.8.8
set load-balancing wan interface-health eth0 test 10 type ping
set load-balancing wan interface-health eth1 failure-count 8
set load-balancing wan interface-health eth1 test 10 target 8.8.4.4
set load-balancing wan interface-health eth1 test 10 type ping
commit
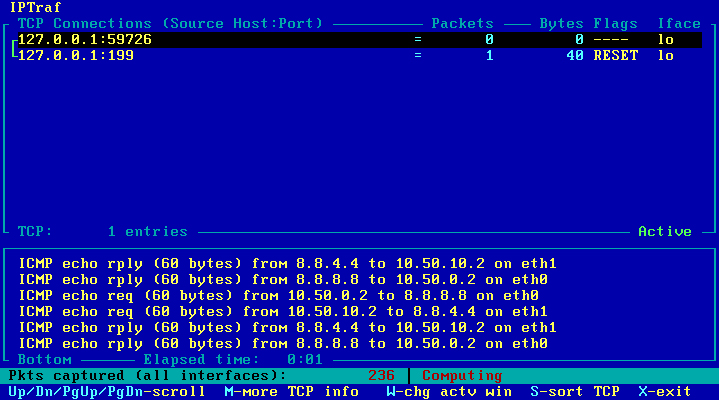
Po powyższej konfiguracji, co kilka sekund przy użyciu protokołu ICMP są sprawdzane oba łącza, co można sprawdzić programem Iptraf, wybierając opcję "IP traffic monitor" [Obraz 11-3]. W razie awarii któregoś z łącz, ruch automatycznie będzie płynął tylko tym drugim. To już jest na pewien sposób failover.
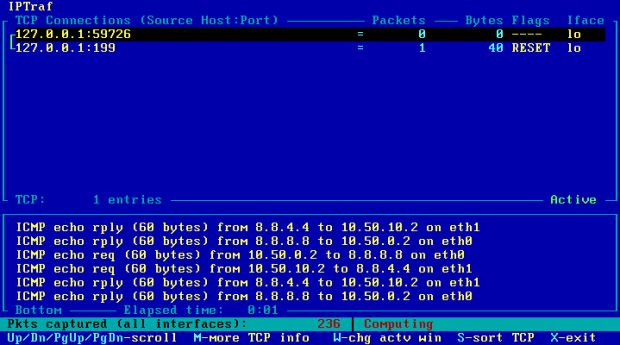
Obraz 11-3: Podgląd ruchu przepływającego przez komputer R2
Do konfiguracji można także wprowadzić wagi, dzięki którym ruch będzie dzielony na oba interfejsy nierówno.
Składnia użytych poleceń:
- 'set load-balancing wan rule < numer> interface < interfejs> weight < liczba>' – określa wagę łącza.
R2:
delete load-balancing wan rule 10
set load-balancing wan rule 10 interface eth0 weight 2
set load-balancing wan rule 10 interface eth1 weight 8
set load-balancing wan rule 10 inbound-interface eth2
commit
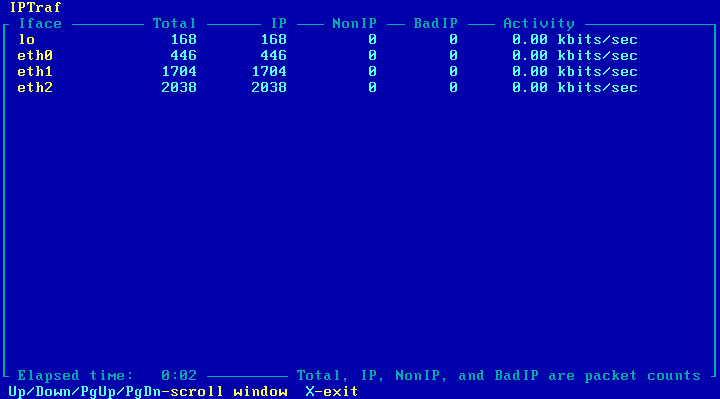
Iptraf pokazuje rozbieżność – to przez sieć 10.50.10.0/28 jest przesyłana większość ruchu [Obraz 11-4].
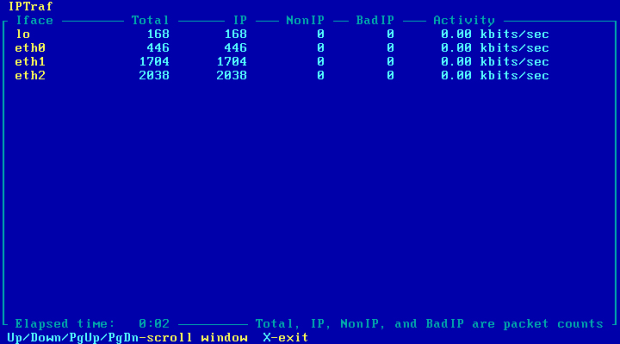
Obraz 11-4: Podgląd ilości pakietów przepływających przez komputer R2
W razie awarii na którymś krańcu sieci 10.50.10.0/28, ruch po chwili będzie kierowany przez sieć 10.50.0.0/28 [Obraz 11-5]. Awaria zostanie zasymulowana przez usunięcie adresu z interfejsu eth1 komputera R2.
R2:
delete interfaces ethernet eth1 address
commit
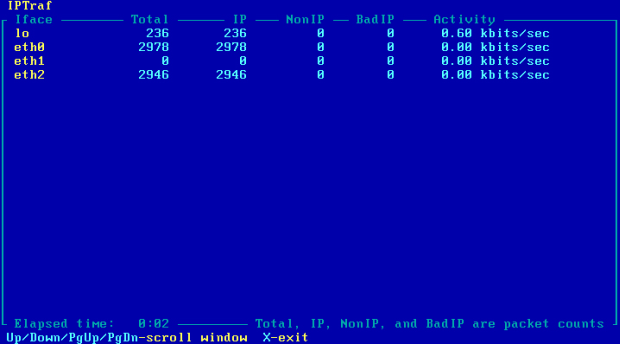
Obraz 11-5: Podgląd ilości pakietów przepływających przez komputer R2
Jak widać failover działa z pewnym opóźnieniem, ale nie na tyle dużym żeby był to problem. Związek z tym ma ilość sprawdzeń łącza pakietami ICMP. Chwilę po przywróceniu do poprawnego działania interfejsu eth2 komputera R2 pakiety będą znowu przesyłane przez sieć preferowaną, czyli 10.50.10.0/28.
11.3. Failover z zachowaniem stanu łącza.
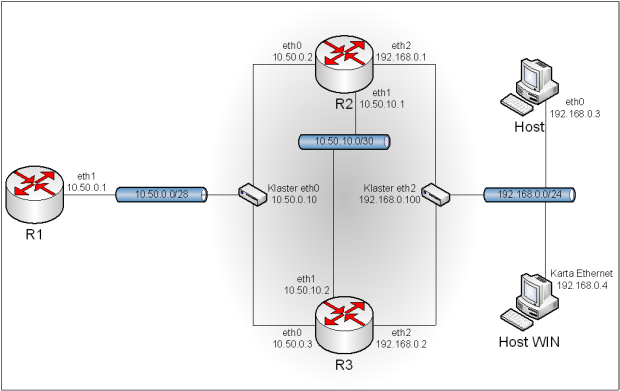
Obraz 11-6: Topologia sieci użytej w zadaniu
Połączenie z komputerem fizycznym i Internetem zostało usunięte z powodu zbyt dużego rozmiaru obrazu, jednak w konfiguracji się znajdzie.
11.3.1. Przygotowanie wirtualnych sieci.
R1:
eth0 – NAT (VMnet8)
eth1 – VMnet2
R2:
eth0 – VMnet2
eth1 – VMnet3
eth2 – VMnet4
R3:
eth0 – VMnet2
eth1 – VMnet3
eth2 – VMnet4
Host:
eth0 – VMnet4
Host WIN:
Karta Ethernet – VMnet4
11.3.2. Konfiguracja.
Po załadowaniu zapisanego stanu trzeba będzie uczynić kilka zmian.
R1:
set protocols static route 192.168.0.0/24 next-hop 10.50.0.10
commit
R2:
delete interfaces ethernet eth1 address
set interfaces ethernet eth1 address 10.50.10.1/30
set interfaces ethernet eth2 address 192.168.0.1/24
commit
R3:
delete interfaces
set interfaces ethernet eth0 address 10.50.0.3/28
set interfaces ethernet eth1 address 10.50.10.2/30
set interfaces ethernet eth2 address 192.168.0.2/24
set system gateway-address 10.50.0.1
commit
Host:
delete interfaces ethernet eth0 address
set interfaces ethernet eth0 address 192.168.0.3/24
set system gateway-address 192.168.0.100
commit
Jak widać powyżej bramy komputerów Host oraz Host WIN muszą być skierowane na wirtualny adres, który będzie adresem klastra, a na maszynie R1 musi istnieć wpis routingu statycznego kierujący na wirtualny adres z drugiej strony klastra. Dodatkowo na maszynie Host WIN trzeba zmienić adres na 192.168.0.4.
Wykonanie failover z zachowaniem stanu łącza jest trochę bardziej pracochłonne niż wykonanie bezstanowego failover, ale daje jedną, sporą korzyść – w razie awarii komputera, przez który przepływa ruch, nie jest zrywane bieżące połączenie, a zatem przy pobieraniu jakiegoś pliku praktycznie nie da się zauważyć tej awarii.
Najpierw zostanie utworzony firewall, który będzie dbał o to, by w tym samym czasie tylko przez jeden komputer przepływał ruch. Firewall będzie identyczny na komputerach R2 i R3.
R2, R3:
set firewall name DO_SIECI default-action drop
set firewall name DO_SIECI rule 10 action accept
set firewall name DO_SIECI rule 10 state established enable
set firewall name DO_SIECI rule 20 action accept
set firewall name DO_SIECI rule 20 destination address 192.168.0.0/24
set firewall name DO_SIECI rule 20 destination port 80
set firewall name DO_SIECI rule 20 protocol tcp
set firewall name DO_SIECI rule 20 state new enable
set firewall name OD_SIECI default-action accept
set firewall name OD_SIECI rule 10 action drop
set firewall name OD_SIECI rule 10 state invalid enable
set interfaces ethernet eth0 firewall in name DO_SIECI
set interfaces ethernet eth2 firewall in name OD_SIECI
commit
Następnie oba te komputery (R2 i R3) muszą zostać połączone w klaster, działający jak jedna maszyna z wirtualnymi interfejsami. To on będzie dbał o przełączanie ruchu w razie awarii jednego z jego węzłów. O awarii dowie się, gdy któryś z monitorowanych adresów przestanie odpowiadać na zapytania ICMP. Konfiguracja klastra będzie identyczna na komputerach R2 i R3.
Składnia użytych poleceń:
- 'set cluster group < nazwa> auto-failback < wartość logiczna>' – tworzy grupę o podanej nazwie oraz określa, że jeśli węzeł główny jest dostępny ponownie po awarii, to ruch ma być przełączony na niego.
- 'set cluster group < nazwa> monitor < adres IP>' – określa adres węzła monitorującego działanie klastra.
- 'set cluster group < nazwa> service < adres IP/maska/interfejs>' – definiuje wirtualny adres pod jakim będzie dostępny klaster.
- 'set cluster interface < interfejs>' – określa interfejs na którym będą przesyłane wiadomości monitorujące (heartbeat) działanie drugiego komputera w klastrze.
- 'set cluster dead-interval < liczba>' –określa po jakim czasie drugi komputer w klastrze ma być uznany za niesprawny (w milisekundach).
- 'set cluster keepalive-interval < liczba>' –określa, co ile milisekund ma być wysyłana wiadomość heartbeat.
- 'set cluster monitor-dead-interval < liczba>' – określa po jakim czasie węzeł monitorujący ma zostać uznany za niesprawny (w ms).
- 'set cluster pre-shared-secret < nazwa>' –definuje klucz uwierzytelniania.
R2, R3:
set cluster group GRUPA auto-failback true
set cluster group GRUPA monitor 10.50.0.1
set cluster group GRUPA monitor 192.168.0.3
set cluster group GRUPA primary R2
set cluster group GRUPA secondary R3
set cluster group GRUPA service 10.50.0.10/28/eth0
set cluster group GRUPA service 192.168.0.100/24/eth2
set cluster interface eth1
set cluster dead-interval 5000
set cluster keepalive-interval 1000
set cluster monitor-dead-interval 3000
set cluster pre-shared-secret klucz
commit
Dla ułatwienia topologii (oraz jej obrazu), między komputerami R1, a R2 i R3 jest tylko jedno łącze. W rzeczywistej sytuacji klaster może być podłączony do kilku dostawców Internetu.
Na koniec trzeba zapewnić synchronizację, aby połączenia nie były zrywane. Zapewnia to moduł Conntrack. Ta część także będzie wspólna dla obu węzłów.
Składnia użytych poleceń:
- 'set service conntrack-sync failover-mechanism cluster group < nazwa>' – definuje grupę dla której ma być wykonywana synchronizacja pakietów.
- 'set service conntrack-sync interface < interfejs>' – określa interfejs, którym będzie synchronizowane połączenie.
R2, R3:
set service conntrack-sync failover-mechanism cluster group GRUPA
set service conntrack-sync interface eth1
commit
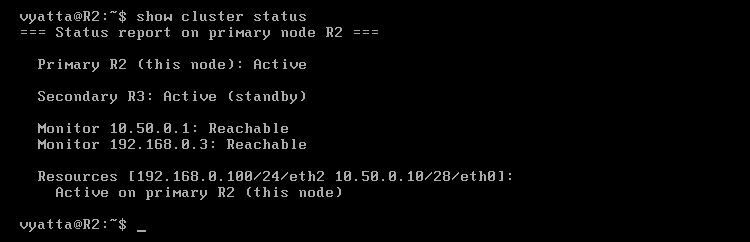
Obraz 11-7 pokazuje status klastra na komputerze R2. Oba komputery działają, R2 jest aktywny, a R3 oczekuje. Oba monitorowane adresy są osiągalne.
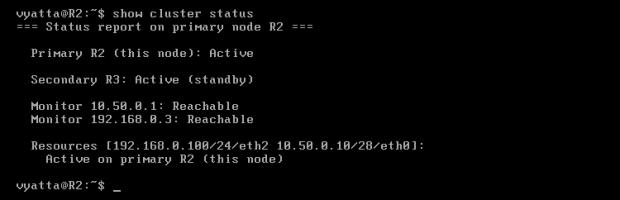
Obraz 11-7: Status klastra na komputerze R2 – oba komputery aktywne
Aby zobaczyć nie tylko status, a również pracę failover, dobrze jest włączyć pobieranie dużego pliku na komputerze Host lub Host WIN i monitorować pracę interfejsów programem Iperf.
Do wywołania awarii na węźle głównym (R2) wystarczy zaprzęgnąć zaporę sieciową.
R2
set firewall name BLOKADA default-action drop
set interfaces ethernet eth0 firewall local name BLOKADA
commit
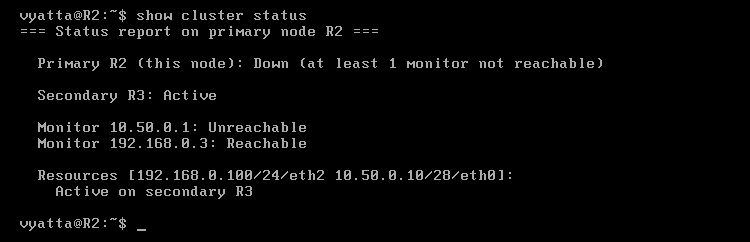
Po uruchomieniu tej zapory status, jak i aktywny węzeł, automatycznie powinien się zmienić [Obraz 11-8], a ruch przepływający do tej pory przez interfejsy eth0 i eth2 komputera R2 powinien popłynąć tymi samymi interfejsami maszyny R3.
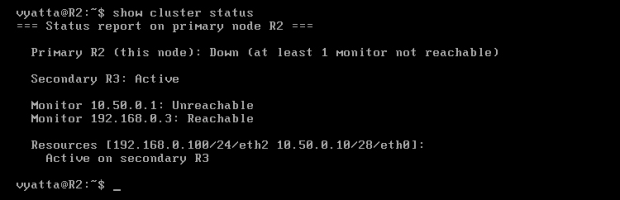
Obraz 11-8: Status klastra na komputerze R2 – tylko R3 aktywny
Failover wymaga dwóch maszyn przekazujących ruch, ale jest dobrym rozwiązaniem dla osób lub firm, które mają konieczność szybkiego i niewidocznego przełączania między łączami przy zachowaniu stanu połączenia.
|
|
 |
Rozdziały: Techinka: Konfiguracja systemu Vyatta w ćwiczeniach |
 |
| |
|
|
 |
 |
 |
|
|
|