|
TwojePC.pl © 2001 - 2026
|
 |
RECENZJE | Pełna recenzja kart nowej generacji ! |
 |
| |
|
Pełna recenzja kart nowej generacji !
Autor: Kris | Data: 09/08/04
| |
|
Teoria (piksele)
Przetwarzanie pikseli
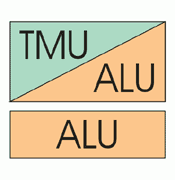
 NV40 jest w stanie przetwarzać jednocześnie 16 pikseli (architektura szesnastopotokowa) lub 32 wartości "Z" (współrzędne bez parametru koloru), czyli 4x więcej niż jego poprzednik. Cztery potoki tworzą jeden blok funkcjonalny (tzw. Quad) ze wspólną pamięcią podręczną tekstur (L2). Każdy potok zawiera procesor pikseli składający się z dwóch jednostek arytmetyczno-logicznych (ALU) realizujących program shadera i odpowiadających za teksturowanie. Taki sam schemat znajdziemy również w poprzednich układach nVidia, ale możliwości wykonywania operacji na ALU są różne. W NV30 i NV35 jeden ALU był dedykowany do wykonywania operacji odwołania do tekstur (TMU), natomiast drugi przetwarzał instrukcje matematyczne (NV30 wykonywał jedną a NV35 dwie takie instrukcje w takcie zegara). NV40 natomiast, przy braku operacji związanych z teksturami może wykorzystać również i drugi ALU do obliczeń arytmetycznych. Zwiększeniu uległa również ilość rejestrów. Stałych, z 32 do 224, a tymczasowych, z 22 do 32. Oprócz zmian o charakterze wydajnościowym mamy również pokaźną listę nowych funkcji. TMU zyskał precyzją zmiennoprzecinkową FP16 (filtrowanie tekstur), wprowadzono możliwość obsługi wielu obszarów renderowania (Multiple Render Targets) oraz dynamiczną i statyczną kontrolę przebiegu. Dzięki temu silnik pikseli NV40 uzyskał zgodność ze specyfikacją 3.0, a ilość instrukcji pojedynczego shadera może być nieograniczona (NV3.x wspierały wersję 2.a z limitem 512 instrukcji). 32-bitowa precyzja obliczeń została odziedziczona po poprzednikach. NV40 jest w stanie przetwarzać jednocześnie 16 pikseli (architektura szesnastopotokowa) lub 32 wartości "Z" (współrzędne bez parametru koloru), czyli 4x więcej niż jego poprzednik. Cztery potoki tworzą jeden blok funkcjonalny (tzw. Quad) ze wspólną pamięcią podręczną tekstur (L2). Każdy potok zawiera procesor pikseli składający się z dwóch jednostek arytmetyczno-logicznych (ALU) realizujących program shadera i odpowiadających za teksturowanie. Taki sam schemat znajdziemy również w poprzednich układach nVidia, ale możliwości wykonywania operacji na ALU są różne. W NV30 i NV35 jeden ALU był dedykowany do wykonywania operacji odwołania do tekstur (TMU), natomiast drugi przetwarzał instrukcje matematyczne (NV30 wykonywał jedną a NV35 dwie takie instrukcje w takcie zegara). NV40 natomiast, przy braku operacji związanych z teksturami może wykorzystać również i drugi ALU do obliczeń arytmetycznych. Zwiększeniu uległa również ilość rejestrów. Stałych, z 32 do 224, a tymczasowych, z 22 do 32. Oprócz zmian o charakterze wydajnościowym mamy również pokaźną listę nowych funkcji. TMU zyskał precyzją zmiennoprzecinkową FP16 (filtrowanie tekstur), wprowadzono możliwość obsługi wielu obszarów renderowania (Multiple Render Targets) oraz dynamiczną i statyczną kontrolę przebiegu. Dzięki temu silnik pikseli NV40 uzyskał zgodność ze specyfikacją 3.0, a ilość instrukcji pojedynczego shadera może być nieograniczona (NV3.x wspierały wersję 2.a z limitem 512 instrukcji). 32-bitowa precyzja obliczeń została odziedziczona po poprzednikach. |
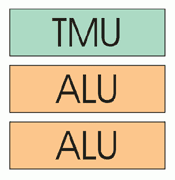
 R420 przetwarza jednocześnie 16 pikseli (lub wartości "Z"), czyli 2x więcej niż jego poprzednik. Zwiększono również ilość rejestrów tymczasowych, z 12 do 32 i wprowadzono statyczną kontrolę przebiegu programu shadera. Silnik pikseli jest zgodny z wersją 2.b. R3xx mógł wykonywać program shadera składający się z 32 operacji na teksturach oraz 64 instrukcji matematycznych (silnik w wersji 2.0). R420 jest w stanie przetworzyć po 512 instrukcji każdego typu, co łącznie daje 1024, ale specyfikacja DirectX dla PS wersji 2.b nie pozwala na przekroczenie łącznej ilości 512 operacji na shader. Podobnie jak w NV40 cztery potoki powiązane są w jeden Quad. Do zwiększenia efektywności przetwarzania dłuższych programów służy F-Bufor, który w przypadku R420 uzyskał możliwość dynamicznej zmiany swojej wielkości. Obsługa wielu obszarów renderowania oraz zmiennoprzecinkowe filtrowanie przez TMU było już dostępne we wcześniejszych układach. Nie zmieniła się również 24-bitowa precyzja obliczeń oraz układ trzech ALU (z których jeden odpowiada za operacje na teksturach), umożliwiający przetworzenie do pięciu instrukcji w pojedynczym takcie zegara. Wprowadzono również możliwość sprzętowej dekompresji tekstur spakowanych w nowym, bezstratnym standardzie 3Dc. R420 przetwarza jednocześnie 16 pikseli (lub wartości "Z"), czyli 2x więcej niż jego poprzednik. Zwiększono również ilość rejestrów tymczasowych, z 12 do 32 i wprowadzono statyczną kontrolę przebiegu programu shadera. Silnik pikseli jest zgodny z wersją 2.b. R3xx mógł wykonywać program shadera składający się z 32 operacji na teksturach oraz 64 instrukcji matematycznych (silnik w wersji 2.0). R420 jest w stanie przetworzyć po 512 instrukcji każdego typu, co łącznie daje 1024, ale specyfikacja DirectX dla PS wersji 2.b nie pozwala na przekroczenie łącznej ilości 512 operacji na shader. Podobnie jak w NV40 cztery potoki powiązane są w jeden Quad. Do zwiększenia efektywności przetwarzania dłuższych programów służy F-Bufor, który w przypadku R420 uzyskał możliwość dynamicznej zmiany swojej wielkości. Obsługa wielu obszarów renderowania oraz zmiennoprzecinkowe filtrowanie przez TMU było już dostępne we wcześniejszych układach. Nie zmieniła się również 24-bitowa precyzja obliczeń oraz układ trzech ALU (z których jeden odpowiada za operacje na teksturach), umożliwiający przetworzenie do pięciu instrukcji w pojedynczym takcie zegara. Wprowadzono również możliwość sprzętowej dekompresji tekstur spakowanych w nowym, bezstratnym standardzie 3Dc. |
Wbrew temu, co niektórzy sądzą, NV40 nie jest oparty na nowej architekturze. Bazą silnika jest model przetwarzania NV30, który nieznacznie (głównie kontroler pamięci i jeden ALU) zmodyfikowano, najpierw do postaci NV35, a teraz, w końcu, doczekał się poważnej i nie ma co ukrywać, wysoce pożądanej rekonstrukcji. Od pierwszego układu Dx9, przygotowanego przez nVidia (pomimo początkowych problemów z interpretacją, związanych z utajnieniem szczegółów konstrukcyjnych), rzuca się w oczy odmienność podejścia do metody przetwarzania operacji 3D, w stosunku do ATI. Rdzeń Radeonów cechuje minimalizacja ilości rozkazów jednostek matematycznych ALU, przy względnie dużej liczbie, możliwych do wykonania, prostych operacji, w jednym takcie zegara (stąd wynika również łatwość implementacji przeróżnych innych efektów, niekoniecznie 3D, korzystając ze wsparcia silnika pikseli). GeForce natomiast, dysponował pokaźną listą, zaawansowanych instrukcji, dedykowanych ściśle określonym zadaniom przetwarzania 3D (pewną analogię znajdziemy w zasadzie działania procesorów RISC i CISC). Jeśli układ nVidia miałby szansę na osiągnięcie tej samej liczby dowolnych operacji w jednym takcie, to przy zbliżonej częstotliwości działania oczywiście zmasakrowałby produkt ATI wydajnością.
Nie jest to jednak możliwe w związku z niezbędnym działaniem projektantów, borykających się z próbą zniwelowania podstawowej wady tego modelu przetwarzania. Chodzi mianowicie o wielkość i skomplikowanie rdzenia, z którym bezpośrednio wiążą się kwestie kosztów produkcji oraz wydatku energetycznego, i co za tym idzie, taktowania. Idea minimalizacji ilości tranzystorów polegała na powiązaniu części zasobów i bloków poszczególnych jednostek ALU. Pojedynczy potok NV3x/4x jest w stanie wykonywać kilka instrukcji jednocześnie, ale tylko wtedy, gdy są one różne (oprócz kilku wyjątków). W takim przypadku mamy do czynienie z największą wydajnością oraz efektywnym wykorzystaniem, niemal każdego "tranzystora", tworzącego bloki wykonawcze potoku pikseli. Problem w tym, że konkretny shader może w sam raz "złośliwie" powielać, w kolejnych rozkazach, te same polecenia i układ natychmiast straci efektywność działania. W ten sposób doszliśmy do jednej z podstawowych wad architektury nowych GeForce'ów. Niestety skuteczność ich działania jest w znacznej mierze oparta na optymalizacji kodu. Niektórym wydajne się, że program współpracy nVidia z programistami gier ma charakter głównie marketingowy. To też, ale przede wszystkim chodzi o maksymalne dostosowanie struktury instrukcji do możliwości układu, bo jest to w stanie przynieść wymierny efekt wydajnościowy. Programistom, wbrew kolejnym plotkom, wcale nie zależy aby ich dzieło działało dobrze tylko na części sprzętu obecnego na rynku. W ich interesie jest również to, aby gra wyglądała i działała dobrze na każdej karcie. Korzystnie na wydajność wpływa sam kompilator, który analizując program shadera jest w stanie zmienić kolejność instrukcji, ale pełnię wydajności karty można jedynie osiągnąć przy dedykowanym kodzie. ATI również wprowadza swój program współpracy z twórcami gier, ale w przypadku Radeonów, zarówno potrzeba, jak i sam efekt optymalizacji, ma niewielkie znaczenie. Chodzi głównie o stronę reklamową i stanowi próbę zbilansowania działań konkurencji, w oczach potencjalnego klienta. Wróćmy do opisu nowych układów.
NV40 vs R420
W zasadzie o R420 niewiele można napisać. Działania projektantów miały na celu efektywne wprowadzenie dwukrotnie większej ilości potoków wraz z nieznacznym usprawnieniem przetwarzania dłuższych shaderów. I pewnie im się to udało. Do nowości zaliczyć można 3Dc. Jest to model kompresji bezstratnej mający zastosowanie dla tekstur odwzorowujących wypukłości metodą map "normalnych". Użycie dużej tekstury pozwala na lepszą implementację efektu, a metody stratne kompresji prowadzą do zniekształceń obrazu (tekstura w tym wypadku "tworzy" geometrię) znacznie łatwiejszych do wychwycenia niż w przypadku klasycznego teksturowania (zakłócenia w samej palecie koloru). Jednak w związku z tym, że R420 potrafi sprzętowo jedynie dekompresować, to aby mógł wykorzystać tekstury w tym formacie, muszą być one, w formie skompresowanej, zawarte w samej grze. ATI nieodpłatnie udostępnia zarówno narzędzia do kompresji jak i nie ogranicza dostępu do samego algorytmu licząc na to, że stanie się to standardem również dla innych producentów hardware a programiści gier wprowadzą format 3Dc zarówno w nowych silnikach jak i w postaci łaty do starych. Dopiero czas pokaże w jakim stopniu 3Dc przyjmie się w grach. Osobiście jestem raczej umiarkowanym entuzjastą.
NV40 natomiast, wręcz zalewa nas powodzią modyfikacji. Oprócz zwiększenia ilości potoków, przebudowano lub przynajmniej rozszerzono, instrukcję większości ALU. Nareszcie GeForce dostał TMU (nakładanie i filtrowanie tekstur) na miarę generacji Dx9 (z ograniczeniem do precyzji 16-bitowej). W powiązaniu z kilkoma efektami (co ważniejsze od dawna dostępnymi u konkurencji) będzie można (mam nadzieję, że nVidia doprowadzi do tego) zrezygnować z kilku uproszczeń w obrazie. Choć teoretycznie, mogły być one realizowane przez układ, to koszt ich wykonania był za duży. Wprawdzie realna ilość jednostek wykonawczych w potoku nie zwiększyła się (niektóre ulotki reklamowych stosują naciąganą formę przedstawienia ich działania), ale dzięki wprowadzeniu "dwufunkcyjnego" ALU (tekstury LUB arytmetyka), potok powinien znacznie lepiej dostosować się do nowych wymagań gier, w których następuje tendencja do zwiększania ilości obliczeń matematycznych kosztem bezpośrednich operacji na teksturach. Pojawienie się instrukcji umożliwiających kontrolę przebiegu programu jest, z jednej strony, krokiem milowym do powstania silników gier, zawierających skomplikowane efekty shaderów, a z drugiej strony, może stanowić dodatkowy zastrzyk wydajności w grach aktualnych oraz tych, które pojawią się jeszcze w tym roku. Jest to możliwe, między innymi, dzięki możliwości dodatkowej optymalizacji procesu nakładania efektu. Można sobie wyobrazić logiczną konstrukcję programu uzależniającego zastosowanie polecania dla piksela od faktu, czy w danych warunkach efekt może być na nim w ogóle widoczny. Chodzi głównie o statyczną kontrolę przebiegu bo w przypadku dynamicznej koszt jest już znacznie większy (3x więcej cykli zegara).
W odróżnieniu od kwestii wydajności nie należy natomiast dać się ponieść marketingowi i uwierzyć, że dzięki zakupie NV40, w sposób spektakularny, skorzystamy na jakości obrazu w stosunku do kart konkurencji. Jako, że niedawny "król shaderów", Radeon 9800 XT, "padał" przy próbie obrobienia programów zawierających kilkadziesiąt prostych instrukcji, to układ, który ma moc nawet i parę razy większą (nawet teoretycznie), nie jest w stanie zbliżyć się do granic specyfikacji 2.x, a tym bardziej osiągać korzyść z braku ograniczenia ilości instrukcji. W kwestii wydajności można, w nieco uproszczony sposób, znaleźć analogię do realnego porównania PS1.4 z PS1.1 z ewentualnym, dodatkowym kosztem w postaci konieczności użycia 32-bitowej precyzji. PS3.0 nie jest żadną metodą bezpośrednią na dodatkowe efekty 3D. Jest to pewien certyfikat, którego zdobycie gwarantuje programistom osiągnięcie konkretnej "kultury" pracy, a producentowi układu ewentualną możliwość dodatkowego zysku wydajnościowego. Trzeba również podkreślić, że to właśnie nVidia zdecydowała się na ten krok (kosztem zarówno inwestycyjnym w pionach R&D, jak i wielkości samego rdzenia) i tak, jak aktualne gry SM2.0 zaczęły pierwotnie powstawać na kartach ATI, tak pichcenie kolejnej generacji silników 3D zacznie się dokonywać na "palnikach" nowych GeForce'ów.
|
|
|
Rozdziały: Pełna recenzja kart nowej generacji ! |
|
| |
|
|
 |
 |
 |
|
|
|
|
|
|
|
|
|
|
|
|

