|
TwojePC.pl © 2001 - 2026
|
 |
Środa 24 sierpnia 2022 |
 |
| |
|
Procesory Ryzen 7000 otrzymają pamięć 3D V-Cache 2. generacji
Autor: Zbyszek | źródło: Twitter | 06:43 |
(6)") | 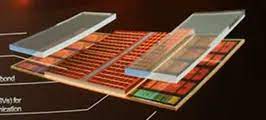 W sieci pojawiają się nowe informacje na temat przyszłym procesorów Ryzen serii 7000 wyposażonych w dodatkową pamięć podręczną 3D V-Cache. Według nich, nowe procesory z dodatkową pamięcią mogą zadebiutować na rynku w 1. kwartale 2023 roku lub na początku 2. kwartału 2023 roku, i otrzymają 3D V-Cache 2. generacji. Ma mieć ona wprawdzie identyczną pojemność (64 MB) jak pamięć 3D V-Cache z procesora Ryzen 7 5800X 3D, ale oprócz tego kilka zasadniczych ulepszeń. Najważniejszym z nich będzie dwukrotnie wyższa przepustowość, czyli szybkość przesyłu danych pomiędzy zasadniczą pamięcią L3 w procesorze a umieszczoną nad nią dodatkową pamięcią 3D V-Cache. W sieci pojawiają się nowe informacje na temat przyszłym procesorów Ryzen serii 7000 wyposażonych w dodatkową pamięć podręczną 3D V-Cache. Według nich, nowe procesory z dodatkową pamięcią mogą zadebiutować na rynku w 1. kwartale 2023 roku lub na początku 2. kwartału 2023 roku, i otrzymają 3D V-Cache 2. generacji. Ma mieć ona wprawdzie identyczną pojemność (64 MB) jak pamięć 3D V-Cache z procesora Ryzen 7 5800X 3D, ale oprócz tego kilka zasadniczych ulepszeń. Najważniejszym z nich będzie dwukrotnie wyższa przepustowość, czyli szybkość przesyłu danych pomiędzy zasadniczą pamięcią L3 w procesorze a umieszczoną nad nią dodatkową pamięcią 3D V-Cache.
To ma sprawić, że w grach 3D zysk wydajności wynikający z zastosowania pamięci 3D V-Cache 2. generacji będzie wyższy, niż 15 procent notowane w procesorze Ryzen 7 5800X 3D. Poza tym pamięć 3D V-Cache 2. generacji ma zawierać zmiany poprawiające odprowadzanie ciepła z procesora i upraszczające produkcję procesorów w nią wyposażonych.
Oczywiście, to informacje nieoficjalne, a więc dowiemy się od AMD prawdopodobnie najpóźniej podczas styczniowych targów CES. |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- Ta dodatkowa pamięć Cache to odpowiedź w stronę programistów (autor: Mario1978 | data: 25/08/22 | godz.: 12:42)
nie ogarniających dzisiejszy hardware. Od lat widać, że gry są tak tworzone by PCIe 3.0 nie był ograniczeniem. Zobaczymy jak hardware będzie wykorzystywał te korzyści jak to wtedy będzie się prezentować. Wystarczy popatrzeć na testy Milan-X by zauważyć, że wzrosty, w niektórych przypadkach jeżeli chodzi o programy są ogromne. Od lat Software ma problem bo Hardware już dawno prześcignął możliwości programowe. Żeby wykorzystać w pełni atuty takich konfiguracji to muszą to być firmy pokroju Amazon, które same sobie dostosowuje OS i oprogramowanie pod hardware. Wystarczy też popatrzeć na testy wewnętrzne hardware właśnie takich firm, które mają własnych programistów dopracowujący Niestandardowe OS po hardware. Procesor może zyskać ogromną wydajność także przez fakt gdy będzie na nim montowana pamięć nieulotna nowej generacji z jeszcze szybszymi czasami dostępu a co za tym idzie przepustowość będzie jeszcze bardziej ogromna. A są już pamięci, które osiągają czas dostępu na poziomie 1ns a nawet niżej tylko jeszcze nie są stosowane. Każda wielka firma dopracowuje te co będzie w bliskiej przyszłości produkowane.
- @up (autor: Qjanusz | data: 25/08/22 | godz.: 16:03)
trochę podobnie było za czasów PS3. Cell miał legendarne możliwości. Problem z ich wydobyciem był po stronie "leniwych programistów".
Prawda jest taka że aby było efektywnie, soft musi uzupełniać sprzęt, a sprzęt naginać się do softu. Czasy super optymalizacji softu pod sprzęt, przy dzisiejszej wadze softu, nie jest najlepszym rozwiązaniem.
Wracając do 3D cache, jest to bardzo dobra próba zwiększenia wydajności sprzętu pod konkretne zastosowania, bez oglądania się na optymalizacje ze strony dostawcy softu.
- Mario1978 (autor: pawel1207 | data: 26/08/22 | godz.: 18:28)
bredzisz 3dcache nie jest zadnym uklonem amd po prostu potrzebowalo ukladu ktory bedzie zapewnial dominacje w okreslonej polce dzieki 3dcache nie musialo modyfikowac calego cpu po prostu poprawino to co w zenach jest slabe czyli wlasni pamiec cache byl to eksperyment czy ludzie beda w stanie wydac kase na takie rozwiazanie bo nie oszukujmmy sie z punktu widzenia usera procki z z 3dcache sa malo oplacalne a z punktu widzenia gracza juz ma sens wyszlo dobrze sa klijenci na takie cpu wiec oplaca sie produkowac i roszerzyc oferte ot cala historia smieszy mnie jak dorabia sie ideologie tam gdzie jej nie ma ... to nie kod potrzebuje tego cache tylo dane :D w grach to nie pcie3x jest ograniczeniem ale to ze ma na to zapotrzebowania bo reszta by i tak nie wyrobila malo tego zapchanie pcie bo mozna poskutkuje zamuleniem wszystkiego bo latencja wzrosnie drastyczni dla wszystkiego :D a strumieniowanie jest w powijakiach w pewnym sensie .to hardware jest zastoj hardware stoi od kilku lat niemal w miejscu po 10 latach rozwoju jakes marny wrost ipc o 50 % co wczesnieiuj bylo co generacje :D to po prostu hardware nie nadarza za potrzebami nikt nie bedzie obecnie klepal oprogramowania w asm i czystym c zwlaszcza w biznesie bo hardware jest tanszy niz praca programisty mamy jezyki wysokiego poziomu i hadrware sobie z tym po prostu nie radzi tak jak powinien mamy karty graficzne ktore ledwo co uciagaja rt :D pomimo iz software w tym kierunku rozwiaja sie o kilkudziesieciu lat . :D jest swietnie dopracowane a przynajmniej jego rdzen mam wrazenie ze zyjesz w latach 80/90 kiedy tak bylo ze to soft musial gonic mozliwosci obecnie hardware niewiele wnosi nie mamy tu rewolucji mamy co najwyzej powolna adaptacje co do potrzeb softu czy amd albo intel na przestrzeni lat wymyslilo cos nowego co stalo sie powszechne mielismy jakas rewolucje ? co najwyrzej mamy ewolucje do ktorej programisci musza sie zadaptowac i ktora niewiele wnosi swietym przykladem byl cell gdzie niby mielismy rewolucje puzniej sie okazalo ze to zadna rewolucja i nkikt tego nie potrzebuje a extra rdzenie byly tak skopane ze dzialy jak nie obciarzylo sie ich do konca aby ogarnac opuznienia trzeba bylo stawac na glowie aby czasem ktoregos w 100 % nie obciarzyc bo padalo wszystko :D wiec nie mow mi ze to hardware nie nadarza za software :D
- pawel1207 (autor: Markizy | data: 26/08/22 | godz.: 19:40)
też mijasz się z prawdą. Sporadycznie występowały skoki wydajności z generacja na generacje o 50%, i to tylko wtedy gdy poprzednia architektura była kiepska (bulldozer, netburs).
Oprogramowanie też bywa w lesie i to mimo wielu lat rozwoju. Od ilu mamy procesory 4 rdzeniowe? A i tak wiele gier preferuje szybki pojedynczym wątek niż wielowątkowość. Nie wspominając o DX11 którego sterownik leciał na jednym wątku.
Pisanie w asemblerze czy nawet w C za bardzo nie jest konieczne, ważne jest dobrze zbudowany kompilator i przemyślany kod. Ale wiele środowisk pomaga w pójściu na skróty wiec kod powstaje bez odpowiednich optymalizacji w samym działniu.
Natomiast amd dodało pamięć 3d cache ponieważ są zastosowania w serwerach gdzie dodatkowy cache jest opłacalny. A że stacjonarne procki jak i te serwerowe budowane są z chipletów wiec czemu nie mieliby upiec dwóch pieczeni na jednym ogniu.
- Markizy (autor: pawel1207 | data: 26/08/22 | godz.: 20:47)
wczesniej postep byl znacznie szybszy 50 % to wartosc szacunkowa byly zmany architektory i byl postep w nanometrach a nawet w samym krzemie czuc bylo rozwoj o jak wymieniales sprzet co rok to od razu zauwarzales ze jest lepiej teraz :D :D praktycznie po sandy bridge cpu mamy powolne ewolucje czasem jest odrobine szybciej . obecnie ludzie sikaja w majtki z wrazenia jak amd zapowiada 15 procentowy wzrost i to nie ipc tylko ogolnej wydajnosci wczesniej ludzie by cos takiego wysmiali i cpu przeszlo by bez echa kupili by ci co skladaj nowego kompa..
gry i soft preferuje jeden watek bo wtedy kod wykonuje sie naszybciej nie wszystko da sie latwo zrownoleglic dochodzi latencja przy tej operacji paradoksalnie aby kod wielowatkowy wykonywal sie dobrze potrzebny byl postep cpu gdzie rdzeni od poczatku byly projektowane do tej pracy wystarczy zobaczyc jak to w swoim czasie wygladalo na sklejkach intelowych :D nawet sandy bridge kulal pod tym wzgledem ten sam stary kod wielowatkowy na nowych cpu dziala znacznie lepiej bo cpu nie ma tak wielu waskich gardel przy pracy wielowatkowej to nie znaczy ze kompilatory od czego czasu nie poszly do przodu w tym kierunku obecnie wielordzeniowosc jest wrecz wymagana a jesli cos obecnie wymaga i dzial na jedym rdzeniu to jest to zwykle partactwo kwestia bezpieczenstwa lub nie ma potrzeby aby rozkladac to na wiele rdzeni wprzypadku gier to jest partactwo zadko koniecznosc ..
i zgadza sie pisanie w asm nie jest konieczne ale do dzisiaj z jego pomoca buduje sie petle a w zasadzie c plus asm w wielu zastosowanich co do reszty to oczywista oczywistosc znana od poczatkow programowania niemniej brak optymalizacji to nie oznacza ze nie wykorzytujemy sprzetu to oznacza wlasnie to ze sprzet nie ogarnia wymagan softu i potrzebana jest optymalizaja pomijam bledy w programowniu.
amd dodało pamięć 3d cache i wiadomo ze docelowo wyladuje w serwerach tutaj mowimy o bredzeniu na temat robienia uklonow :D bo to mnie rozbawilo amd jest tak samo chciwe jak intel o zadnych uklonach tu nie ma mowy to porstu badanie rynku i nie mowie tu o serwerach tylko o rynku konsumenckim bo to on przeciera szlaki dla 3d cache takie fakty pojawi sie w serwerach jak je dopracuja i ogarna sie z padajacymi kontrolerami pamieci w tych procesorach ..:D
i nie zgadzam sie ze to soft nie nadarza za sprzetem jest dokladnie odwrotnie obecnie to hardware bardzo mocno ogranicza to co chcemy i to co mozemy zrobic cierzko zrobic rewolucje przy 15 % ogolnych wrostach wydajnosci rocznie przynajmniej w gpu jest lepiej na razie . wlaszcza ze potencjalny klijent nie wymienial swojego sprzetu od kilku lat wtedy mozna wysc z zalozenia ze lepiej pisac pod staszy sprzet a na nowym i tak sie szybciej wykona niemniej w pracy wielowatkowej lepiej wiedziec ile rdzeni sie ma dodyspozycji bo inaczje dla klijent a koncowego moze nie wygladac to za fajnie a puzniej jest placz i rozczarowanie i fakt na nowe cpu znacznie latwiej jest rozloyc algorytm na wiele rdzeni i znacznie lepiej sie skaluja z takim kodem po prostu np na starym cpu przy podobnej ilosci rzeczy zaczyna byc problem i np sa przestoje bo nie wyrabia komunikacja miedy rdzeniami czy cache efektem jet to ze np silnik ma shuterring bo nagle przy jakiejs operacji ktora nowe cpu lykaja bez problemu stara ma takie opuznienie ze rece opadaj pomimo iz teoretycznie problemu nie powinno byc.
- @5 Pewne galezie rozwoju i postepu sa... (autor: gantrithor | data: 27/08/22 | godz.: 01:21)
niestety "narazie" nieoplacalne przykladem moze byc waferscale gdzie chiplety sa drukowane na jednym waflu krzemowym a w razie awari jednego z chipletow wafel jest ciety i ewaluowany ponownie w celu umieszczenia na plytce procesora w formie McM czy reorganizacja i sklejanie czolami procesorow co zaprezentowal intel podczas konferencji IEEE w 2004 roku, to wlasnie tez jest poklosie i dosc niesmiale kroki amd z integracja pamieci 3D cache co jest i tak dosc prymitywne bo jest stosowane w przemysle ukladow flash od kilkunastu lat.
Jak mowisz ogromnym problemem przy wzroscie wydajnosci okazuje sie zwyczajnie fizyka, jesli dwa tranzystory chca sie ze soba komunikowac a sa oddalone o 1000 tranzystorow od siebie to wprowadza dosc spore opoznienia tu pomaga zmniejszanie procesu technologicznego gdzie tranzystory fizycznie zblizaja sie do siebie, innym problemem okazuje sie zegar tranzystora bo co z tego ze tranzystor potrafi pracowac z czestotliwoscia 10GHz skoro pamiec cache potrafi dostarczyc mu dane do przetwarzania tylko co drugi cykl zmniejszajac tym samym wydajnosc o 50%, niestety juz przed czasami pentium 4 zaczynalo to stanowic problem a poszczegolne czesci procesora zaczely byc grupowane w bloki ktore znowu komunikowaly sie z innymi czesciami procesora a problem tylko sie uwydatnil...
Z tej okazji intel wprowadzil etapy potoku procesora "processor pipeline stages" trik pozwalajacy poszczegolnym blokom procesora wykonywac male intrukcje kiedy sasiedni blok robi co innego, podnioslo to wydajnosc i zamaskowalo opoznienia w przesyle danych lecz problem nadal pozostal i dalej wraz ze wzrostem zaawansowania a wraz z nim ilosci tranazystorow coraz bardziej sie uwydatnial.
Intel wykonal dosc smialy eksperyment, inzynierowie pocieli dwa funkcjonalne masowo produkowane egzemplarze procesora pentium 4 z funkcjnujacymi blokami tak ze na pierwszej warstwie znajdowaly sie "FPU, pamiec cache L1 oraz polowa pamieci cache L2" na drugiej zas znajdowaly sie "druga polowa pamieci cache L2, jednostki SIMD, jednostki wykonawcze oraz rejestry" bloki ulozono tak aby unikac przegrzewania oraz tak aby byly blizej pamieci cache.
Rezultatem bylo zmniejszenie ilosci etapow potoku o 25% co zwiekszylo wydajnosc procesora o 15% tylko eliminujac opoznienia bez przeprojektowania blokow proceasora, reorganizacja procesora ponadto pozwolila na redukcje przewodow zasilajacych co zmniejszylo konsumpcje energi calego procesora o 15% a podsumowac mozna ten eksperyment tak ze wydajnosc na wat wzrosla o 35% porownujac oba procesory zegar w zegar co nie jest malym wynikiem i plasuje sie w skoku generacyjnym.
To troche tak jak by przeorganizowac silnik spalinowy przelozyc kilka czesci w inne miejsce a rezultatem bylo by zmniejszenie spalania o 35% przy tej samej mocy silnika i identycznych czesciach zamiennych...
Podsumowaujac zwiekszanie ilosci tranzystorow planarnego procesora mija sie z celem gdyz zwiekszaja sie opoznienia co zwyczajnie eliminuje zysk ilosci tranzystorow odpowiedzia sa kolejne procesy technologiczne zmniejszajace wielkosc tranzystora i ich odleglosc od siebie ale nadal pozostaje ograniczenie zegara procesora i ciaglasc dostarczania porcji danych do obliczen, procesory warstwowe pozwalaja na eliminacje znacznej czesci opoznien co pozwala na zwiekszenie ilosci danych dostarczanych do tranzystorow wiec naturalnym bylo by zwiekszenie ich czestotliwosci i zarazem efektywnosci.
Co stoi na przeszkodzie? czas, pieniadze, innowacyjnosc a przedewszytkim brak narzedzi, produkcja dwoch mniejszych procesorow okazuje sie byc tansza niz produkcja jednego wiekszego wiec przetarte sa juz pewne szlaki natomiast "sklejanie" ich warstwowo nie jest jeszcze na tyle popularne aby isc dalej mimo iz pewien szlak przetarlo AMD z pamieciami 3d cache jednak nadal pozostaje problem uzysku aby przedsiewziecie mialo sens produkcja musiala by odbywac sie na juz dosc dobrze opanowanym procesie technologicznym aby byl wysoki uzysk gdyz produkcja sklejek powoduje zwyczajnie zmniejszenie ilosci sprawnych ukladow o polowe.
Sklejanie, czesc procesora jest ukladana na szklanej tafli w celu jego "produkcji" nastepnie za pomoca lasera utrafioletowego jest oddzielana, jest to proces mechaiczny powodujacy straty w uzysku, firmy IBM oraz TEL opracowaly nowa obiecujaca metode produkcji elementow sklejek dla wafli krzemowych 300mm ktora nie wymaga uzywania szklanych tafli wiec i tu pojawiaja sie juz pewne narzedzia.
Czy gra jest wogole warta swieczki? jak najbardziej, stojac przy scianie jaka jest fizyka i pieniadze najlatwiejszym rozwiazaniem jest wlasnie uklad procesora warstwowy nie wspominajac juz o tym ze odpowiednio zaprojektowane bloki procesora mogly by zwiekszyc wydajnosc nawet trzykrotnie dla pojedynczego watku rdzenia.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
