|
TwojePC.pl © 2001 - 2026
|
 |
Wtorek 7 lipca 2020 |
 |
| |
|
Core i5-1135G7 i Core i7-1165G7 - testy wydajności iGPU
Autor: Zbyszek | źródło: WccFtech | 06:35 |
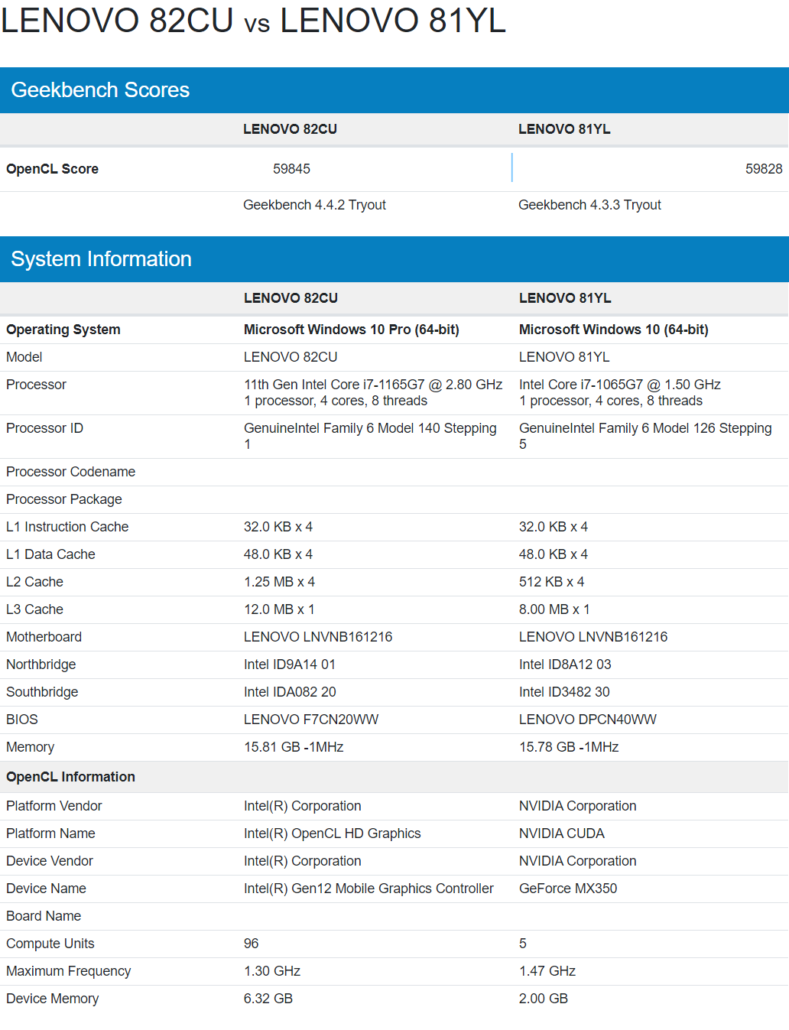
(11)") |  Od kilku miesięcy w sieci regularnie pojawiają się informacje na temat nadchodzących mobilnych procesorów Intela 11. generacji, czyli chipów o nazwie kodowej Tiger Lake-U. Będą one wytwarzane w litografii 10nm++ i wyposażone w rdzenie x86 Willow Cove oraz zintegrowany układ graficzny 12 generacji (architektura Xe) z 96 jednostkami wykonawczymi (EU). Pierwszymi przedstawicielami tej serii zostaną 4-rdzeniowe i 8 wątkowe Core i5-1135G7 i Intel Core i7-1165G7. Drugi z tych procesorów, zamontowany w laptopie Lenovo 82CU, został porównany do karty GeForce MX350 w benchmarku OpenCL GeekBench. Od kilku miesięcy w sieci regularnie pojawiają się informacje na temat nadchodzących mobilnych procesorów Intela 11. generacji, czyli chipów o nazwie kodowej Tiger Lake-U. Będą one wytwarzane w litografii 10nm++ i wyposażone w rdzenie x86 Willow Cove oraz zintegrowany układ graficzny 12 generacji (architektura Xe) z 96 jednostkami wykonawczymi (EU). Pierwszymi przedstawicielami tej serii zostaną 4-rdzeniowe i 8 wątkowe Core i5-1135G7 i Intel Core i7-1165G7. Drugi z tych procesorów, zamontowany w laptopie Lenovo 82CU, został porównany do karty GeForce MX350 w benchmarku OpenCL GeekBench.
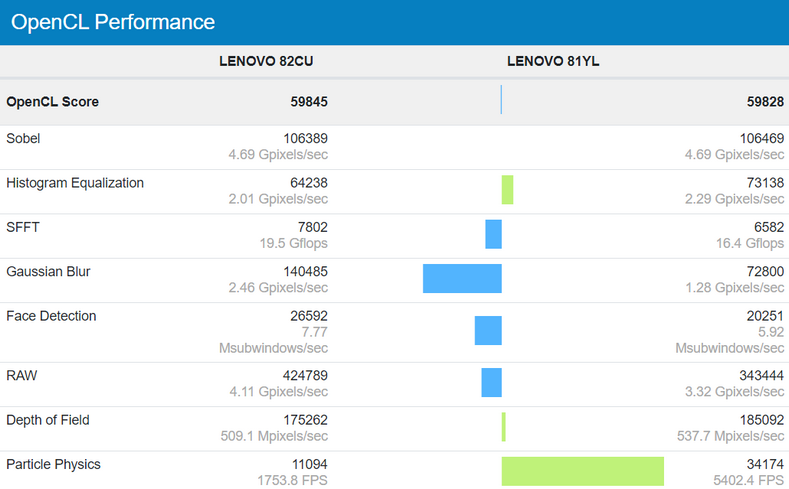
Okazuje się, że obydwa procesory graficzne - zintegrowany w Core i7-1165G7 IGP Intel Xe oraz GeForce MX350 uzyskały bardzo zbliżony rezultat, wynoszący około 60 000 punktów.
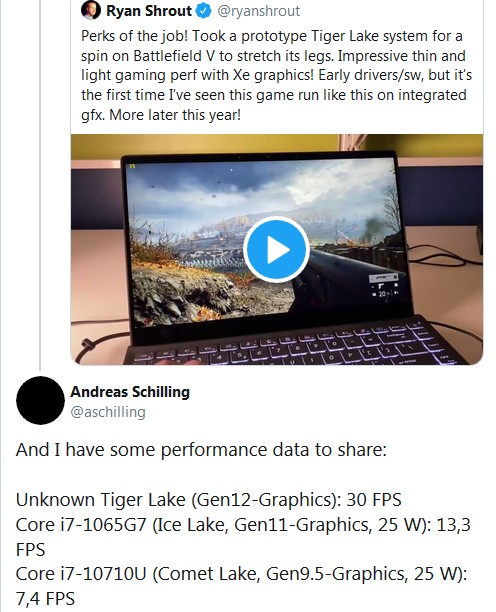
W sieci pojawił się także wynik, jaki próbka nieznanego procesora z serii Tiger Lake-U osiągnęła w Battlefield V. Jak się okazuje, zintegrowany w tym procesorze układ graficzny potrafił zapewnić ponad dwukrotnie więcej klatek na sekundę niż Core i7-1065G7 z serii Ice-Lake.
To zła wiadomość dla AMD, oznaczająca, że IGP w Tiger Lake-U może być znacznie bardziej wydajny niż Vega 8 w mobilnych Ryzenach serii 4000.
   |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- Zbyszek (autor: kombajn4 | data: 7/07/20 | godz.: 06:51)
" znacznie bardziej wydajny niż Vega 8"
Polska język trudna język? Aż oczy krwawią od tego łamańca językowego. Nie wystarczy napisać "znacznie wydajniejszy"? Czy po prostu robisz kopiuj i wklej z google translate i w oryginale było "a lot more powerful then Vega 8" ?
- "To zła wiadomość dla AMD" (autor: Qjanusz | data: 7/07/20 | godz.: 10:14)
ale dobra dla nas. Ja się osobiście cieszę z tego, że AMD zostanie zmotywowane do montowania w APU RDNA2 którym AMD dysponuje tu i teraz, zamiast z niezrozumiałych dla nikogo przyczyn ciągle stawia na starą Vegę.
Osiągnięcie poziomu MX350 przez IGP/APU, jest wydarzeniem nad wyraz bardzo pozytywnym.
Dojdzie jeszcze do tego, że będziemy wybierać Intela pod kątem wydajności IGP, a AMD w kontekście wydajności CPU - to już byłyby niezłe jaja...
- Ciekawy post z forum Anandtech (autor: PCCPU | data: 7/07/20 | godz.: 12:31)
Google Translate:
"Intel opublikował interesujący artykuł na temat przewidywania wartości skupionej i jego konsekwencji dla przyszłych ulepszeń architektury procesora:
https://conferences.computer.org/...466100a079.pdf
Kilka fragmentów, które osobiście uznałem za interesujące:
„Zaproponowano przewidywanie wartości, aby spekulacyjnie przełamać prawdziwe zależności danych, umożliwiając w ten sposób procesorom Out of Order (OOO) osiągnięcie wyższego równoległości poziomu instrukcji (ILP) i zwiększenie wydajności. predyktory wartości artystycznej próbują zmaksymalizować liczbę instrukcji, które można przewidzieć pod kątem wartości, z przekonaniem, że większy zasięg odblokuje więcej ILP i zwiększy wydajność ”.
„FVP znacznie zmniejsza obszar, moc i złożoność projektową implementacji prognozowania wartości, a jednocześnie zapewnia duże przyrosty wydajności. Szczegółowe wyniki symulacji dla 60 różnorodnych jedno-wątkowych obciążeń pokazują, że cenimy przewidywanie około 25% wszystkich instrukcji obciążenia i dostarczamy 3,3% wzrost wydajności w porównaniu do poziomu bazowego podobnego do procesora Intel Skylake. Wydajność ta znacznie wzrasta do 8,6%, gdy symulujemy futurystyczny procesor, który ma dwukrotnie więcej zasobów niż Skylake. ”"
- Edit (autor: PCCPU | data: 7/07/20 | godz.: 12:47)
Dla ścisłości chodzi o wydajność predyktorów czyi przewidywania skoków i pętli w kodzie.
- Edit2 (autor: PCCPU | data: 7/07/20 | godz.: 12:50)
jak i Out Of Order(OOO) - przekolejkowywanie instrukcji/rozkazów.
- @3. Doceniam dobrą wolę (autor: pandy | data: 7/07/20 | godz.: 13:02)
ale po co coś tłumaczyć google skoro wiadomo że straci to jakikolwiek sens i zamieni się w niezrozumiały bełkot?
State of the art to termin oznaczający najbardziej zaawansowany - dzieło sztuki (w domyśle inżynierskiej) - coś co zbliża się do teoretycznego maksimum wyznaczonego teorią (np informacji) i np technologią (ta istniejącą teraz i/lub dającą się przewidzieć w nieodległej przyszłości) - nie ma to nic wspólnego z wartościami artystycznymi...
- @4. (autor: pandy | data: 7/07/20 | godz.: 13:05)
Chodzi o przewidywanie wartości bo to dane a nie instrukcje są w tej chwili ograniczeniem. Chodzi o zależności związane z danymi które ograniczają ILP - Modern Out-of-Order (OOO) processors rely on large instruction windows to extract instruction level parallelism(ILP). However, inherent data dependencies limit ILP. Value prediction [16] was proposed as a mechanism to break thesedata dependencies and unlock ILP. By predicting the value of a producer instruction, the consumer can speculatively execute even before the producer has executed. If the prediction was incorrect, a pipeline flush is typically needed
- @Up (autor: PCCPU | data: 7/07/20 | godz.: 13:14)
Za bardzo pospieszyłem się. Dzięki za sprostowanie.
- czyli (autor: Zbyszek.J | data: 7/07/20 | godz.: 14:16)
oprócz przewidywania instrukcji dojdzie przewidywanie danych
- Ciekawe (autor: PCCPU | data: 7/07/20 | godz.: 19:59)
Może Intel tą symulowaną mikroarchitekturę 2x "szerszą" od Skylake wprowadzi w GoldenCove lub kolejnym x86.
- @9. (autor: pandy | data: 8/07/20 | godz.: 10:19)
Już teraz jest przewidywanie danych (w równoległych potokach antycypuje się nie tylko instrukcje będące wynikiem przetwarzania danych ale też same dane co pozwala właśnie wykorzystać do maksimum out od order i ILP - to nie jest nic nowego bo sumatory z antycypowaniem przeniesienia są z nami od kilkudziesięciu lat jako podstawowe bloki konstrukcyjne w ALU ) - dokument który podrzucił PCCPU wspomina o trochę innym podejściu (zamiast zwiększać wielkosc okna co wiąże się z większą ilością tranzystorów i większą mocą traconą używają oni innego podejścia - natomiast nie wgryzałem się w to by zrozumieć na czym polega ta istotna różnica - to powoli przestaje być czysta elektronika a bardziej statystyka związana z przetwarzaniem danych - analiza kontekstu programowego i struktur danych zaimplementowana na poziomie krzemu).
Szczerze mówiąc czytanie takich dokumentów jest coraz trudniejsze - nie wiem czy to kwestia narodowości autorów publikacji czy jednak materia zaczyna być tak złożona że zaczyna się wymykać dobremu, inżynierskiemu językowi angielskiemu.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
