|
TwojePC.pl © 2001 - 2026
|
 |
Poniedziałek 4 stycznia 2021 |
 |
| |
|
AMD patentuje budowę typu MCM dla układów GPU
Autor: Zbyszek | źródło: WccFTech | 06:46 |
(13)") |  Począwszy od serii Ryzen 3000 procesory AMD wykorzystują budowę typu MCM (Muti Chip Module), w której pojedynczy procesor składa się z conajmniej dwóch oddzielnych układów scalonych połączonych bardzo szybką magistralą - o czym więcej można przeczytać tutaj. Rozwiązanie ma kilka zalet - pozwala produkować mniejsze rdzenie krzemowe, co zwiększa uzysk z produkcji, a pozatym umożliwia rozdzielenie produkcji pomiędzy fabryki TSMC i GlobalFoundries - pierwsza z firm wytwarza układy krzemowe z rdzeniami x86, a druga układ krzemowy z kontrolerami, mostkiem północnym i interfejsami I/O. Począwszy od serii Ryzen 3000 procesory AMD wykorzystują budowę typu MCM (Muti Chip Module), w której pojedynczy procesor składa się z conajmniej dwóch oddzielnych układów scalonych połączonych bardzo szybką magistralą - o czym więcej można przeczytać tutaj. Rozwiązanie ma kilka zalet - pozwala produkować mniejsze rdzenie krzemowe, co zwiększa uzysk z produkcji, a pozatym umożliwia rozdzielenie produkcji pomiędzy fabryki TSMC i GlobalFoundries - pierwsza z firm wytwarza układy krzemowe z rdzeniami x86, a druga układ krzemowy z kontrolerami, mostkiem północnym i interfejsami I/O.
Od pewnego czasu spekuluje się, że z biegiem czasu rozwiązanie MCM zostanie przeniesione przez AMD także do kart graficznych, pozwalając na łączenie kilku mniejszych rdzeni w sposób symulujący jeden duży układ krzemowy.
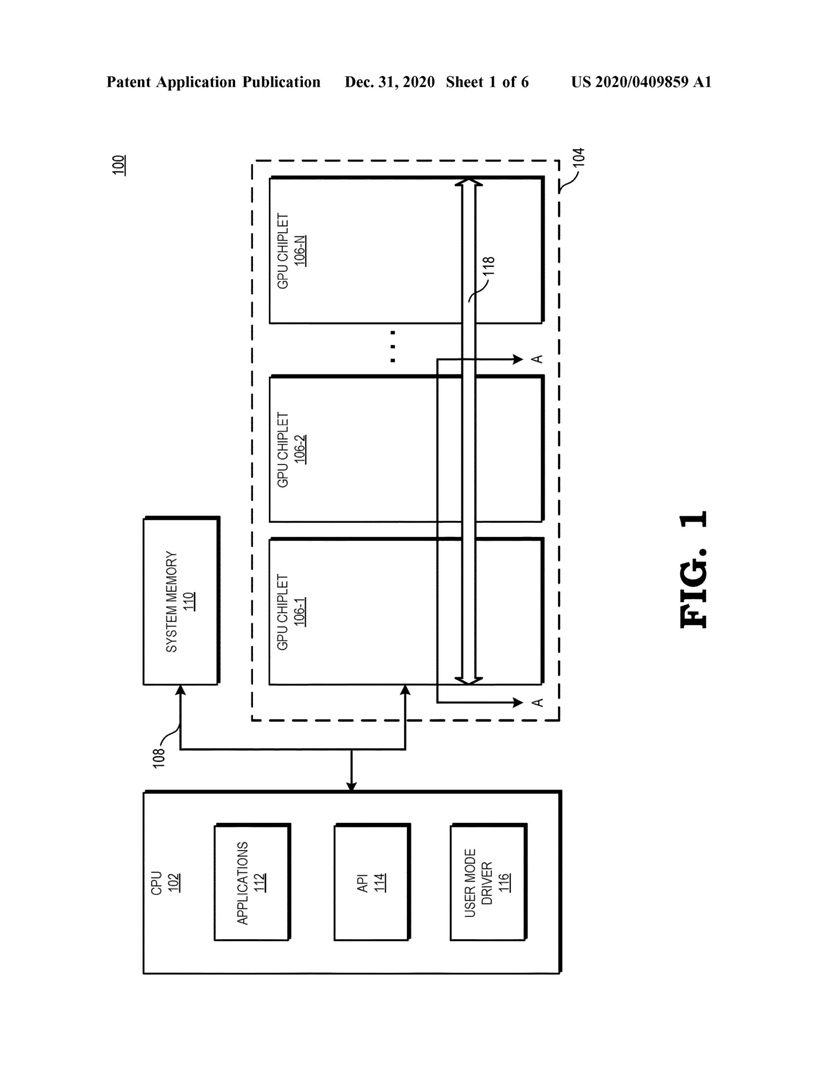
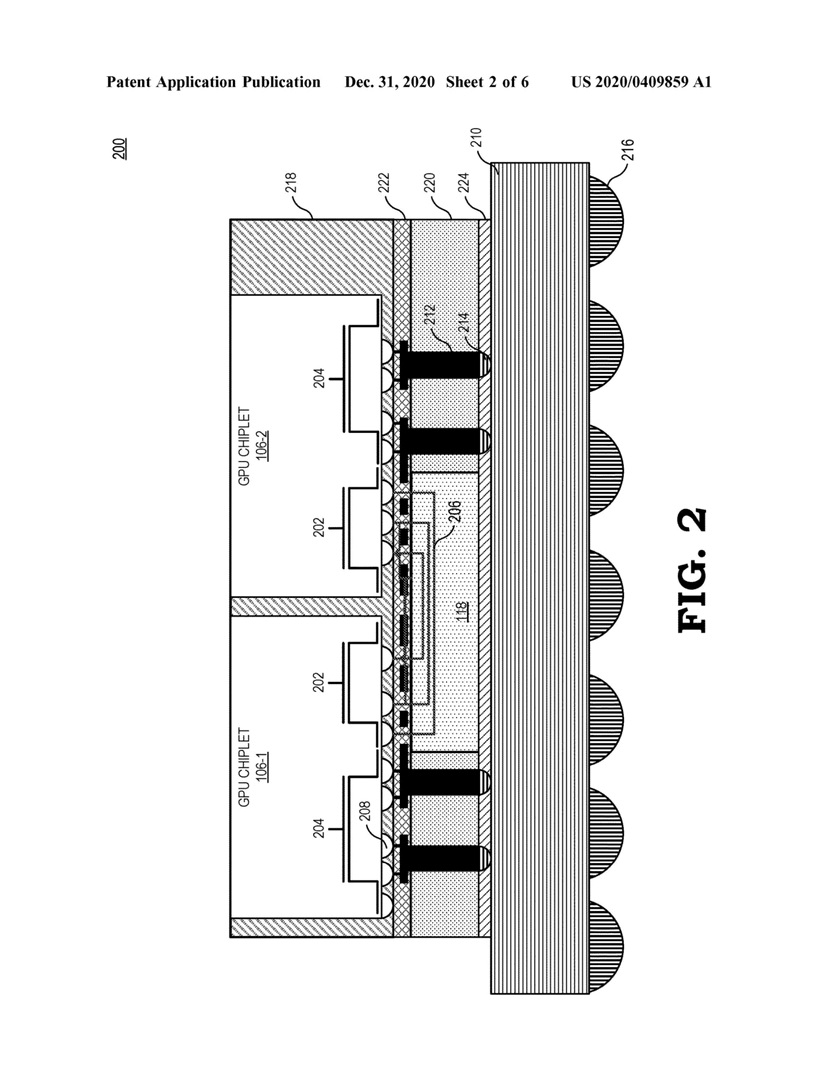
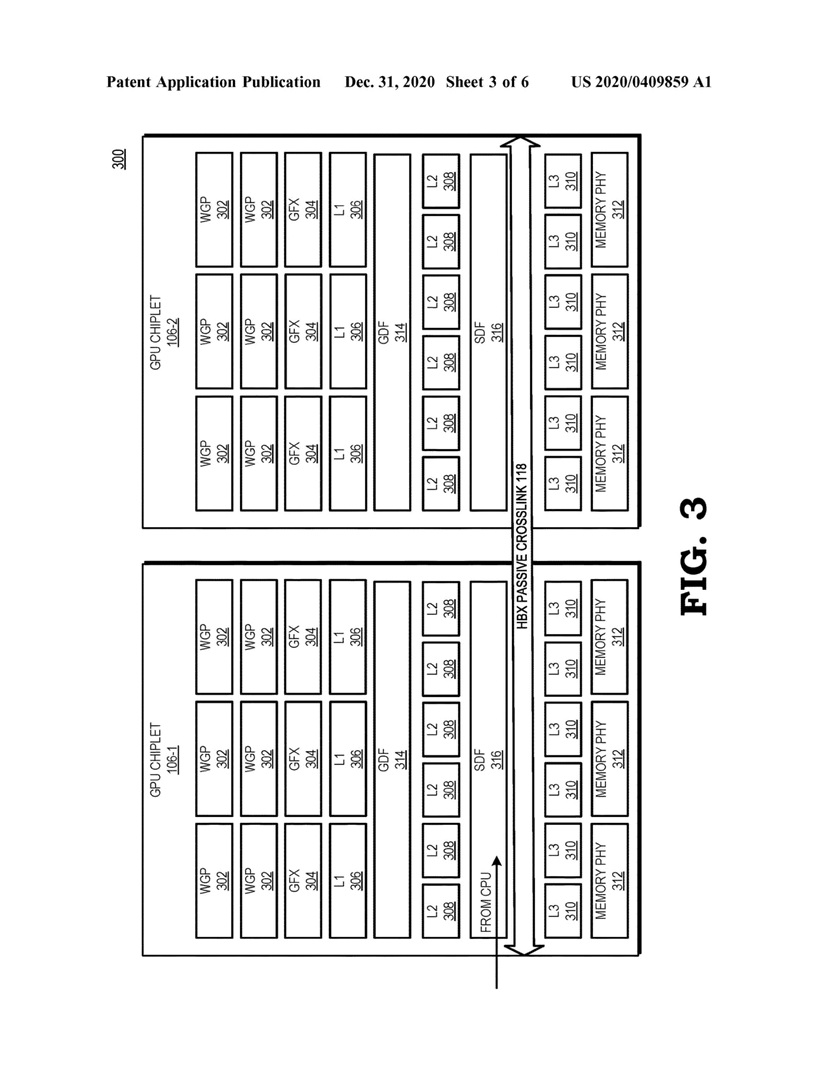
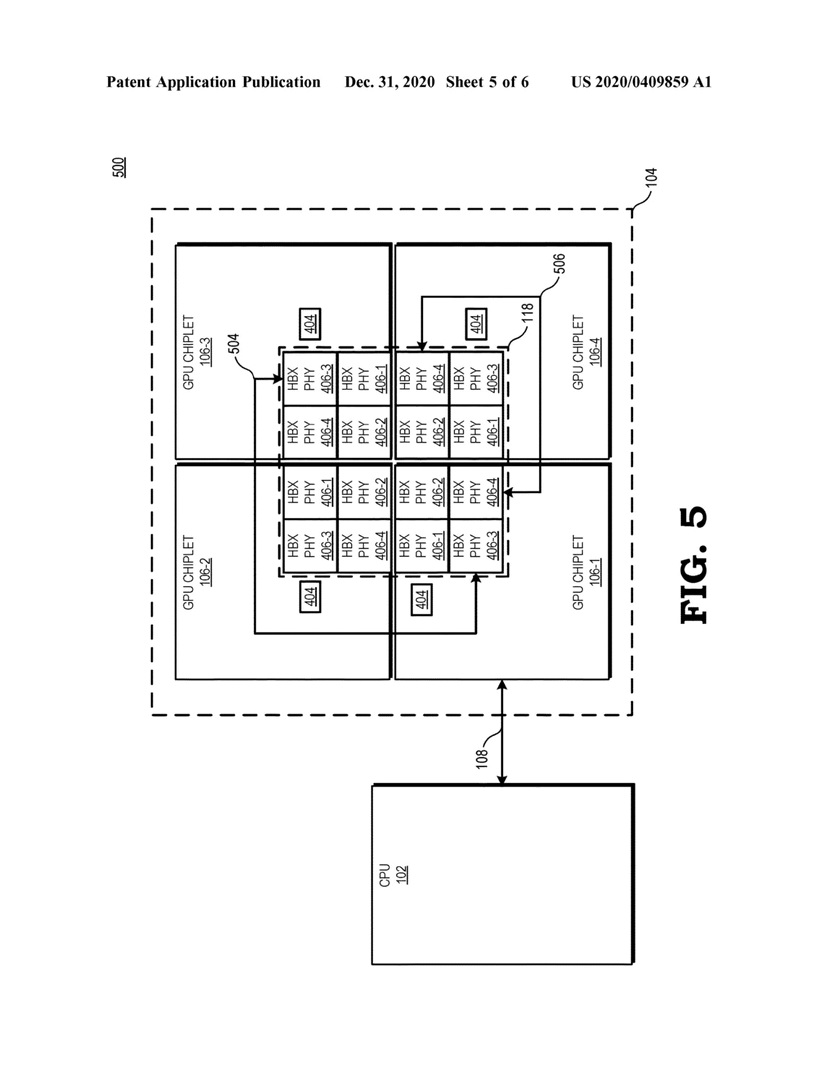
Pogłoski właśnie stają się faktem, bo 31 grudnia 2020 roku firma AMD zarejestrowała patent na modularną budowę kart graficznych, złożonych z kilku rdzeni krzemowych zwanych chipletami. Do patentu dołączone zostały rysunki, z których może wynikać, że AMD chce łączyć ze sobą rdzenie GPU przez interfejs typu Interposer, czyli podobnie jak łączone są pamięci HBM z rdzeniem GPU w kartach z serii Radeon Vega i Radeon VII.
      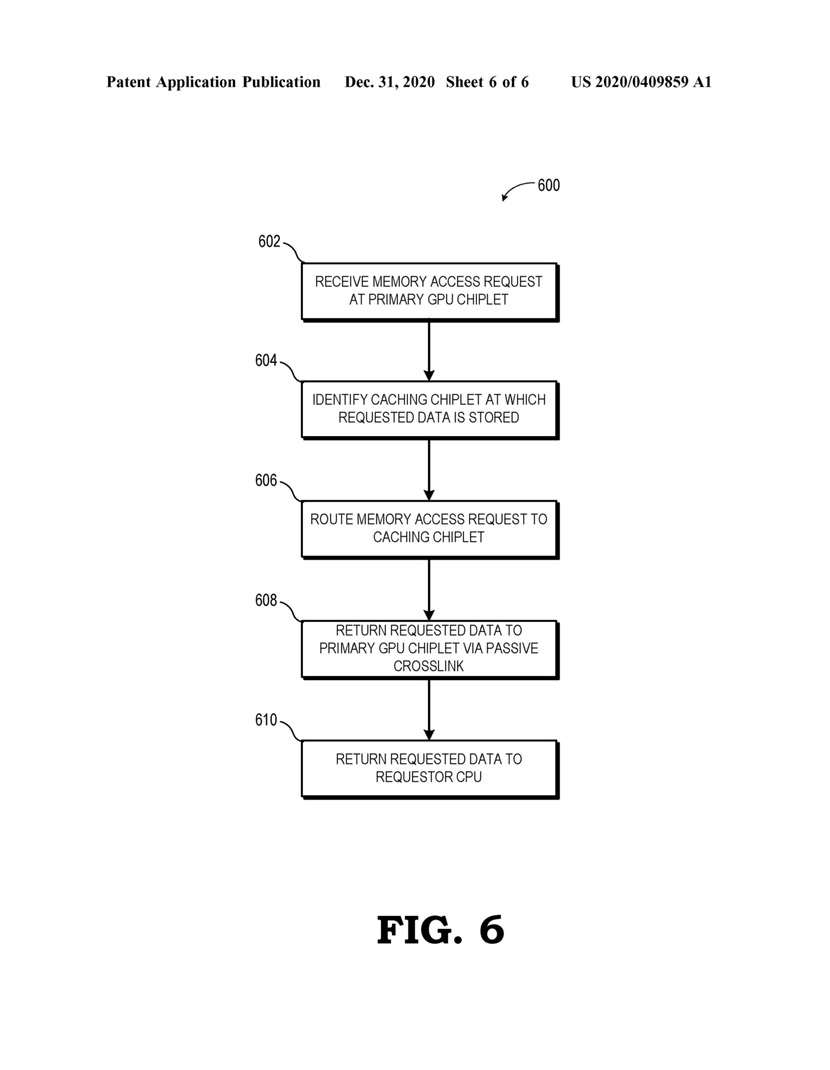       |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- kiedyś któryś z gości od AMD wypowiadał się że implementacja MCM w GPU (autor: Qjanusz | data: 4/01/21 | godz.: 09:37)
nie jest taka prosta jak w przypadku CPU, ponieważ wydajność GPU jest bardziej wrażliwa na wszelakie opóźnienia niż CPU, a MCM bez wątpienia wprowadza wszelakiego rodzaju "lagi"
Ciekawe czy AMD już teraz doszło do takiego etapu, że opóźnienia te są akceptowalne / zbalansowane innymi sztuczkami, czy to bardziej przejaw walki o słabo dostępne nowoczesne linie produkcyjne w fabach.
- Hmm... (autor: Kenjiro | data: 4/01/21 | godz.: 10:32)
Pamiętajmy, że w USA można patentować pomysły, nawet te, których nie da się zrealizować technicznie lub realizacja jest zbyt kosztowna lub problematyczna.
W związku z tym może być tak, że patent ma wyłącznie na celu zablokować ewentualne podobne pomysły w wykonaniu konkurencji.
Co innego w Europie, gdzie patent musi odzwierciedlać konkretne rozwiązanie techniczne.
- To nie jest do końca tak, że (autor: josh | data: 4/01/21 | godz.: 11:38)
patent ma coś blokować. Jakby spojrzeć od strony koncepcji patentów (obecnie często wypaczanej) to idea jest dokładnie odwrotna. Być może AMD nie może obecnie tego używać, ale nie chce też tego chować do szuflady. Patent daje wszystkim wgląd w koncepcję. Może ktoś wymyśli coś, usprawni i wtedy obie strony skorzystają.
- @temat. (autor: Mariosti | data: 4/01/21 | godz.: 13:09)
W ciągu ostatnich 3 lat AMD dokonało bardzo dużo w kwestii rozwijania Infinity Fabric, obniżania jego opóźnień i zwiększania przepustowości.
Najwyraźniej uznali że przyszłe generacje IF w wersji dla GPU mogą być już wystarczające na zastosowanie takiej architektury, a jak do tego doliczą sam fakt iż absolutny top wydajności już nie jest tak istotny i lepiej mieć gpu 10-15% mniej wydajne od konkurencji ale w lepszej cenie i faktycznie dostępne w sklepach... no to wniosek jest prosty.
- patent (autor: pawel1207 | data: 4/01/21 | godz.: 16:10)
zawsze slurzy monopolizacji rynku na pewne rozwiazanie i innego celu patentow nie ma.. "W ciągu ostatnich 3 lat AMD dokonało bardzo dużo w kwestii rozwijania Infinity Fabric, obniżania jego opóźnień i zwiększania przepustowości.
Najwyraźniej uznali że przyszłe generacje IF w wersji dla GPU mogą być już wystarczające na zastosowanie takiej architektury, a jak do tego doliczą sam fakt iż absolutny top wydajności już nie jest tak istotny i lepiej mieć gpu 10-15% mniej wydajne od konkurencji ale w lepszej cenie i faktycznie dostępne w sklepach... no to wniosek jest prosty." taa wszyscy widzimy ta dostepnosc i cene zarazem :D :D :D :D
- Narazie jestem sceptyczny... (autor: gantrithor | data: 4/01/21 | godz.: 17:06)
bo moze sie okazac ze to poprostu uklad graficny na rynek pro gdzie szeregowe polaczone gpu nie negatywnegoo wplywu na obliczenia "patrz intel Xe"
Z drugiej strony amd ladnie pokazalo ze stosujac dodatkowa pamiec dedykowana w samym ukladzie gpu mozna znacznie zmniejszyc opoznienia miedzy procesorem i gpu nie wspominajac juz ze podobna operacja mogla by dzialac jeszcze lepiej w przypadku gpu ktore sa ulozone zaraz obok siebie i posiadaja znacznie szybsza komunikacje "amd crosslink, nvidia pasywny nvlink" zamiast pci-e
Tu jesli dobrze rozumiem to cpu komunikuje sie tylko z jedym gpu do pamieci l3 a juz nastepnie gpu komunikuje sie poprzez crosslink z innymi gpu bez uzycia cpu co ma za zadanie przy dzisiejszym programowaniu sprawic ze uklad jest widziany jako jeden monolityczny uklad gpu.
@4 Chodzi o cene ale tez wydajnosc, teoretycznie najwiekszym ukladem ktory mozna wydrukowac jest chip o wielkosci 815mm/2 im wiekszy uklad tym bardziej optyka rozmazuje sie na rogach ukladu do tego na krawedziach jest bardziej widoczny cien swiatla odbitego pod katem 6 stopni mimo iz jest to dosc malo to przy takich wymiarach litografi jest to juz pewien problem "cien jest bardziej spowodowany gruboscia powloki antyrefleksyjnej i absorbera ale przy duzych ukladach ma to wiekszy wplyw niz w malych"
Jesli mozesz wyprodukowac tylko uklad 815mm/2 to tak naprawde wchodzisz w stagnacje, a co jesli by ulozyc obok siebie 4, 6 lub nawet 12 takich ukladow, nagle przeskakuje sie pewna bariere ktora stanowi dzis fizyka.
W centrach danych az 90% energi jest marnowane na przesyl danych miedzy pamiecia vram, ram, cpu, innymi gpu, innymi szafami... kolejnym rozwiazaniem jest produkcja ukladow waferscale gdzie nie przeskoczono limitu teoretycznego 815mm/2 ale na jednym i tym samym waflu krzemowym jest wydrukowane kilka ukladow gpu ktore do komunikacji uzywaja sciezek krzemowych co powoduje przyspieszenie przesylu danych miedzy gpu 100 krotnie i zmniejsza zuzycie energi 1000 krotnie.
Na takiej podstawie zostal zbudowany uklad cerebras systems o powierzchni 46,225mm/2 "16nm" posiadajacy 18GB ram oraz przesyl wewnetrzny 100 Pb/s, caly uklad zuzywa 20kW energi, dla przykladu 56 ukladow tesla v100 "12nm" daje podobna wielkosc co uklad cerebras ale konsumuje tylko 15kW energi... gdzie tu postep? a no jest bo w obliczeniach AI osiaga 1000 krotnie wyzsza wydajnosc niz jedna karta tesla v100.
Dla porownania 1000 kart potrzebowalo by 250kW energi.
Obecnie wafer scale engine jest juz w drugiej generacji i wlasciwie nic nie stoi na przeszkodzie aby od zaraz "po drobnych modyfikacjach lini produkcyjnych" wprowadzic ta technologie na rynek, 2 lub 4 uklady na tym samym waflu to i tak bardzo duzy postep i uwazam ze jesli McM sie zadomowi to w drugiej moze trzeciej generacji beda wlasnie stosowane wafer scale. "technologia nie jest opatentowana jako taka"
Ciekawostka cerebras systems testuje w laboratorium nowy uklad cs-1 15u drugiej generacji wykonany przez TSMC w 7nm, posiada on 2,6 tryliona tranzystorow i sklada sie z 850 tysiecy procesorow dla porownania pierwszej generacji uklad posiadal 1,2 tryliona tranzystorow i 400 tysiecy procesorow oraz byl wykonany w 16nm.
- @6 Przepraszam za skrot myslowy... (autor: gantrithor | data: 4/01/21 | godz.: 17:16)
nie chcialem wprowadzic w blad jako by tsmc mialo 100% uzysku w 7nm, uklady cerebras sa tak zaprojektowane aby mozna bylo programowo ominac uszkodzone czesci ukladu co nie zmienia faktu ze jesli amd planuje jeden glowny master gpu i reszta slave to nawet taki uklad w waferscale mogl by funkcjonowac uszkodzony na podobe ukladow ccx procesorow zen gdzie uszkodzone rdzenie byly poprostu wylaczone.
- @6. (autor: Mariosti | data: 4/01/21 | godz.: 17:54)
Clue architektury modułowej to kwestia uzysku.
Przy tych wspomnianych przez ciebie 815mm^2 powierzchni układu scalonego można uznać że przy 7nm jako dobry uznany zostanie uzysk rzędu 50%.
Podobną wydajność zapewne da się uzyskać stosując 4 chiplety o powierzchni 200mm^2 + ~200mm^2 chip i/o wykonany np w 12nm, ale tutaj już możliwy będzie uzysk rzędu 90-95% dla części w 7nm i 99% dla części w 12nm.
Tu tkwi główna siła tego rozwiązania.
- ad8. (autor: Mariosti | data: 4/01/21 | godz.: 17:57)
Albo podobnie jak w przypadku Zen3 pojedynczy chiplet mógłby mieć w okolicy 100mm^2 powierzchni i do topowych gpu stosowanoby od 2-3 do 8 chipletów z dużym chipem i/o, a do modeli z niższej półki 1 do 2 chipletów z małym chipem i/o.
- ad9. (autor: Mariosti | data: 4/01/21 | godz.: 17:58)
Stosując ten sam jeden rodzaj chipletu gpu we wszystkich modelach i tylko 2 rodzaje chipów io zwiększyłoby nieprawdopodobnie płynność dostaw, elastyczność produkcji, oraz wspomniany wielokrotnie uzysk.
- @Mariosti (autor: Promilus | data: 4/01/21 | godz.: 19:44)
Tak tylko AMD musiałoby rozwiązać te problemy, które już w przypadku CPU się w Zenach uwypuklały, a co dopiero w przypadku GPU gdzie danymi trzeba się wymieniać bardzo często i bardzo wieloma...
- @11. (autor: Mariosti | data: 5/01/21 | godz.: 11:57)
Nie no w gpu wymiana danych jest dość prosta i raczej nie występuje przerzucanie wątków między gpc tak jak między ccx, tak samo między sp nie występuje przerzucanie wątków/instrukcji/danych.
Dane wewnątrz gpc zwykle są traktowane "równolegle" i zresztą gpc na pewno byłoby integralne i nierozerwalne. Jedyny w zasadzie problem to dostęp do pamięci podręcznej i do ramu, bo to one stanowią większość wymiany danych poza gpc (kontrolery ramu sa zwykle wewnątrz gpc, ale dają dostęp tylko do jednego modułu ramu, także tutaj w grę wchodziłoby właśni infinity fabric, niezależnie od tego czy kontroler ram pozostałby przy gpc w chiplecie czy w chipie i/o jak w zen'ach.
Ogólnie rzecz biorąc cpu wymagają znacznie większej eleastyczności niż gpu jeśli chodzi o interconnecty, także tutaj się nie zgodzę i wg mnie z gpu będzie łatwiej.
Jedyna trudność w przypadku gpu to wymagana bardzo duża przepustowość tych interconnectów.
- @Mariosti (autor: Promilus | data: 5/01/21 | godz.: 14:24)
Ty piszesz o równoległości wątków, a ja pisałem o wymianie DANYCH.
"Dane wewnątrz gpc zwykle są traktowane "równolegle" i zresztą gpc na pewno byłoby integralne i nierozerwalne" - nie zmienia to faktu, że u nvidii każdy GPC jest podłączony do L2 cache zapewniającego spójność danych. IF nie ma opcji zapewnienia takich parametrów więc to co jest interesujące to właśnie jak AMD ma to zamiar rozwiązać. Innymi słowy jeśli uznać GPC jako odpowiednik wielowątkowego rdzenia CPU to w GPU istotne jest to by ten rdzeń z pozostałymi był połączony czymś z niskimi opóźnieniami i wysoką przepustowością. W przypadku zupełnie niezależnych od siebie wątków z niezależnymi od siebie danymi to nie jest tak istotne, problem w tym, że w GPU to mogą być niezależne od siebie wątki, ale dane są jak najbardziej wspólne. Wspólne są dane wejściowe (geometria, tekstury) i wyjściowe (piksele). Ta spójność danych musi być zachowana. I tak jak IF wprowadza jednak opóźnienia w dostępie do danych różnych CCX wielokrotnie wyższe niż ich cache, a w niektórych przypadkach daje to stratę kilkunastu % wydajności wielowątkowej tak w przypadku GPU to by była strata idąca w grube dziesiątki %. Więc jeszcze raz - niezwykle istotne jest to jak AMD ten problem dla GPU obejdzie. NIE ma aktualnie fizycznej opcji by osiągnąć to co w monolicie robi L2.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
