|
TwojePC.pl © 2001 - 2026
|
 |
Piątek 26 marca 2021 |
 |
| |
|
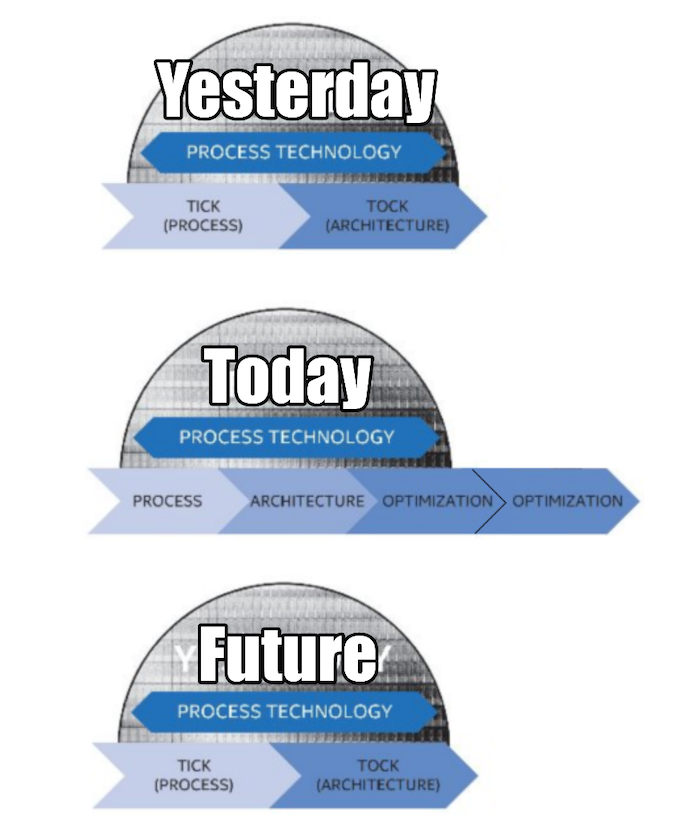
Intel zapowiada powrót w 2024 roku do modelu Tick-Tock
Autor: Wedelek | źródło: AnandTech | 05:30 |
(20)") |  Podczas sesji pytań Q&A aktualny szef Intela – Pat Gelsinger zdradził, że chce w 2024 roku wrócić do znanego z lat poprzednich modelu Tick-Tock. Innymi słowy mamy co roku dostawać procesor, który albo będzie wdrażać nową mikroarchitekturę CPU albo nowy proces litograficzny. Ma to pozwolić na szybki postęp i w rezultacie przywrócić Intelowi dominującą pozycję na rynku procesorów. Mówimy oczywiście cały czas o IPC i ogólnej wydajności, bo jeśli chodzi o udziały w rynku, to Intel nieustannie dzierży palmę pierwszeństwa i nic nie wskazuje na to, by miał ją szybko stracić. Inna sprawa, że plany nie zawsze pokrywają się z rzeczywistością. Podczas sesji pytań Q&A aktualny szef Intela – Pat Gelsinger zdradził, że chce w 2024 roku wrócić do znanego z lat poprzednich modelu Tick-Tock. Innymi słowy mamy co roku dostawać procesor, który albo będzie wdrażać nową mikroarchitekturę CPU albo nowy proces litograficzny. Ma to pozwolić na szybki postęp i w rezultacie przywrócić Intelowi dominującą pozycję na rynku procesorów. Mówimy oczywiście cały czas o IPC i ogólnej wydajności, bo jeśli chodzi o udziały w rynku, to Intel nieustannie dzierży palmę pierwszeństwa i nic nie wskazuje na to, by miał ją szybko stracić. Inna sprawa, że plany nie zawsze pokrywają się z rzeczywistością.
Aktualny zastój nie wziął się przecież z lenistwa Intela, tylko z problemów z wdrożeniem litografii 10nm. To wywróciło cały model do góry nogami, wprowadzając nas w fazę nieustannej optymalizacji tego, co już było. Intel musiał nawet w pewnym momencie przenieść swoją już istniejącą architekturę do starszej litografii by móc nadal konkurować z innymi. Tak powstały układy Rocket Lake-S z rdzeniami Cypress Cove, które od strony technicznej są tym samym co Sunny Cove, ale w 14nm zamiast w 10nm.
Z drugiej strony skoro malutkie AMD potrafiło się podźwignąć z porażki o nazwie Bulldozer i stworzyć Zen, to czemu dużo bogatszemu Intelowi miałoby się to nie udać.
 |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- Paradoks (autor: ekspert_IT | data: 26/03/21 | godz.: 10:08)
Sukces 14nm Intela okazał się jego bolączką, gdyż jak go wprowadzali w 2014r był nowoczesny, AMD dopiero wprowadzało 28nm Steamroller (po 32nm Piledriverze i Bulldozerze), więc mieli wszystko: AMD leżało w pojedyńczym wątku (w multicore sytuacja była nieco lepsza), AMD wytwarzało o wiele mniej ukłądów z wafla w fabach Globala, Intel był konkurencyjny na tle Samsunga czy TSMC (które wprowadziły ten proces rok wcześniej). A teraz? Wielokrotnie usprawniane 14nm Intela nie może konkurować w TOP z 7nm AMD, a 10nm okazało się bolączką całej firmy. A konkurencja już wprowadza 5nm i przymierza się do 3nm...
- @1 ale (autor: OBoloG | data: 26/03/21 | godz.: 10:48)
co będzie po 3nm? w końcu wszyscy dojdą do muru którego nie przeskoczą - trzeba będzie wytwarzać coraz większe układy o coraz większej powierzchni bo proces produkcyjny zakończy się pewnie na 1 nm.
- @2. (autor: g5mark | data: 26/03/21 | godz.: 10:51)
podobno już od jakiegoś czasu znane są nano rurki.Pewnie pójdą w te stronę albo zacznie się wyścig w kierunku komputerów kwantowych
- Jest taki fajny przewodnik zakładający wymiary i technologie produkcji. (autor: Mario1978 | data: 26/03/21 | godz.: 11:31)
Można w nim znaleźć specyfikację zakładaną przez ogólnoZiemski związek zrzeszający największe firmy produkujące tranzystory. Wszystkie wymiary mają osiągnąć na chwilę obecną minimalnie 16nm x 20nm x 24nm i będzie to 1.4nm nazywane przez Intela ale dopiero w 2028 roku. Jednocześnie w 2025 roku ma być dla litografii 3nm użyta technologia układanie tranzystorów na sobie na całej powierzchni CPU. Grubość zwiększy się nie widocznie dla ludzkiego oka a dostając taki procesor lub chip będziemy mieli dwa razy więcej tranzystorów.
W 2030 roku zakładają, że takie nakładanie się tranzystorów na siebie osiągnie poziom 4 stosów przez co nieznacznie pogrubienie układu o powierzchni 10mm x 10mm będzie mógł zmieścić 3.2 Miliarda tranzystora czyli 800 Milionów tranzystorów na mm2 x 4.
Ale patrząc na zapędy TSMC oraz firmy Samsung, która już teraz jest zdolna do wypuszczenia DDR5 w jednym 'Blistrze' o pojemności 512GB z 8 stosami, którego każdy stos połączony jest przez TSV już wiadome, że może to nastąpić prędzej.
Oczywiście według zapowiedzi układanie w stosy przyniesie obniżenie maksymalnego taktowania o 10-20% ale korzyści w ilości tranzystorów będą nie do ogarnięcia dla osób, które nie wierzą w takie 'CUDA'. Wyobraźcie sobie w 2028 roku układ SOC w Smartfonie mający 100mm2 mający 200 Miliardów tranzystorów. Teraz to jest nie do ogarnięcia ale właśnie tak to będzie się zmieniać.
- para w gwizdek (autor: ziemowit | data: 26/03/21 | godz.: 11:45)
:)
ja bym wprowadził ogólnoZiemski zakaz rozwoju CPU i GPU na 5 lat.
Oraz ogólnoZiemski nakaz optymalizacji kodu.
- @5. (autor: Kosiarz | data: 26/03/21 | godz.: 12:22)
:D dobre
- Intel (autor: Conan Barbarian | data: 26/03/21 | godz.: 14:57)
Intel naprawdę dzielnie się broni w tych 14nm+++ i niech lepiej AMD nie osiada na sukcesach, bo szczęście wiecznie nie sprzyja.
W przypadku AMD nie ma już nawet śladu dawnej (2017) miłości dla "usera" a zamiast normalnej firmy mamy pazerne korpo, w dupie mające wszystko i wszystkich. Szczytem sikania parabolicznego jest ukłon w stronę pierdolonych górników, skąd chwilowa kaska płynie.
- @5× (autor: grab56 | data: 26/03/21 | godz.: 14:59)
Optymalizacja kodu ruszy pełną parą, jak tylko dojdziemy do "ściany".
- @Conan (autor: ekspert_IT | data: 26/03/21 | godz.: 15:21)
Obecne wysokie ceny CPU i kuriozalne/skandaliczne ceny na gpu to wina spekulantów Bitcoinowych. A w zasadzie to wina rządów, że nie ma oprocentowania depozytów/obligacji , co powoduje, że ludzie spekulacyjnie inwestują we wszystko: akcje spółek śmieciowych, bitcoina, marne a horrendalnie drogie dzieła sztuki nowoczesnej , mieszkania za 25 tys zł z metra...A jeszcze wracając do AMD to i tak się bardziej opłaca bo nie musisz zmieniać płyty i ramów do każdej kolejnej generacji proca...
- @9. (autor: g5mark | data: 26/03/21 | godz.: 17:17)
Prawie się zgadzam z tobą. Ceny poszły w górę, bo każdy dobry powód jest dobry aby te cenę podwyższyć. Właściwie to nie ma komu robić w fabrykach, cykl logistyczny został zakłócony, każde ogniwo z tego cyklu podwyższyło sobie ceny, bo jakże...skoro mamy Covid,to ceny idą w górę.Bitcoin to tylko jedna para kaloszy
- Conan Barbarian (autor: Markizy | data: 26/03/21 | godz.: 20:11)
amd nigdy nie pałało miłością do "usera" nawet jak mieli słabą ofertę odwalali kwiatki z kompatybilnością FM2 z FM2+. Tak samo było jak zapowiadali układy graficzne Vege też wielki kiler zielonych, a wyszło średnio. Nie mówiąc o tym że ich układy cierpią na mocną chorobę poboru energii.
Układy polaris były dobre, a były by jeszcze lepsze gdyby pilnowali producentów kart którzy wywalali napięcia maksymalne prawie w pełnym zakresie pracy karty. Nie mówiąc o tym że chyba wszystkie układy dało się odpalić z napięciem na rdzeniu niższym o 100mV.
- Narazie do granic fizyki inzynierom i naukowcom daleko... (autor: gantrithor | data: 26/03/21 | godz.: 20:43)
obecnie tranzystor w 7nm zajmuje okolo ~40nm/2 jest to bardzo zbrubne zalozenie ze wzgledu na to iz wysoko wydajne tranzystory zajmuja wiecej miejsca mozna to porownac do parkingu z samochodami, wydajniejszy i wysoko taktowany tranzystor potrzebuje wiecej finow dzieki ktorym transportuje wiecej energi aby utrzymac wysokie zegary te zajmuja wiecej miejsca inaczej jest w ukladach mobilnych dajmy na to procesor snapdragon 888 gdzie tranzystory maja mniej finow, sa nizej taktowane i sa mniej wydajne za to zuzywaja znacznie mniej energi oraz zajmuja mniej miejsca.
Wydajny procesor to duzy parking ale co by tu zrobic aby przy dzisiejszej technologi zbudowac kompaktowy i wysoko wydajny tranzystor zajmujacy malo miejsca?
Odpowiedzia jest nanosheet "gaafet" czy mbcfet "samsung" gdzie finy ulozone sa jeden na drugim zamiast jeden obok drugiego to taki parking gdzie samochody stoja jeden na drugim zamiast obok siebie, takie rozwiazanie jest tanie dostepne juz dzisiaj i mozna je wdrozyc od zaraz na dodatek ma kilka zalet jak lepsza kontrola przeplywu elektronow oraz nizsze napiecie.
Tranzystory gaafet pozwola jeszcze przez ladnych pare lat zwiekszac upakowanie tranzystorow tak wiec stagnacja potrwa jeszcze troche a krzem sie jeszcze nigdzie nie wybiera.
- @11 (autor: Conan Barbarian | data: 26/03/21 | godz.: 22:16)
"ich układy cierpią na mocną chorobę poboru energii"
Tego to na pewno nie można im obecnie zarzucić.
Proce na ZEN3 są świetne, ale niestety drogie lub nieosiągalne (5900X).
- @12 (autor: Markizy | data: 27/03/21 | godz.: 12:30)
O ile CPU działaja wzorowo tak GPU nadal na poziomie zielonych, a przecież ci drudzy korzystają z gorszego procesu niż AMD. Obecnie trudno realnie kogokolwiek z kimkolwiek w dziale GPU porównać ale nadal muszą dużo popracować nad parametrami pracy.
- @up (autor: Markizy | data: 27/03/21 | godz.: 12:31)
Miało być do 13
- debilne pole tematu (autor: henrix343 | data: 27/03/21 | godz.: 21:05)
Tick Tock to im odlicza AMD i bardzo dobrze. Oby te korpo sie zrownaly i doszedl jakis 3 gracz, bo ceny sa po prostu KOSMICZNE.
- henrix343 (autor: PCCPU | data: 28/03/21 | godz.: 03:56)
AMD nie ma żadnego modelu TIC-TOCK ponieważ Zen2 i Zen3 jadą na tym samym 7nm procesie produkcji.
- Ciekawostka (autor: PCCPU | data: 28/03/21 | godz.: 04:31)
Jim Keller twierdził że kolejny rdzeń po SunnyCove będzie znacznie większy. okno instrukcji(ROB) ma mieć 800 pozycji względem SunnyCove(352) i ma mieć ogromne predyktory danych i gałęzi. Jeśli to prawda to GoldenCove będzie niżej taktowany niż Skylake czy Rocketlake.
- Takie tam ;) (autor: PCCPU | data: 28/03/21 | godz.: 05:26)
Rdzeń x86 Skylake 217 milionów tranzystorów
Front-end
Cache L1-Instrukcji 32KB 8-Way
µOP cache 1536 wpisów
ITLB 8 wpisów(2M)
Allocation Queue(IDQ) 64 µOP/wątek lub 128 µOP pojedynczy wątek
LSD może wykryć do 64 µOP pętli/wątek lub 128 µOP pojedynczy wątek
5-cio drożny dekoder x86(1 kompleksowy, 4 proste)
Back-end
Przydział instrukcji 4-Way
Przekolejkowywanie instrukcji(OoO(ROB)) 224 wpisy w locie
Scheduler 97 wpisów
Register Files - Integer 180 wpisów + FP 168 wpisów
Dispatch 8-Way(wysyłka z schedulera(porty jednostek wykonawczych))
Execution Engine
3x FP-ALU(Jednostki arytmetyczno-logiczne-zmienno-przecinkowe(2x FMAC 256bit))
1x ALU(Jednostka arytmetyczno-logiczna)
1x StoreData(magazyn danych)
3x AGU(2x ładowanie adresów, 1x generowanie adresów)
Memory subsystem
In-Flight Loads 72 wpisy (ładowanie w locie z L1D)
In-Flight Stores 56 wpisów (magazynowanie w locie do L1D)
Cache L1-Danych 32KB 8-Way
Cache L2 256KB 4-Way
------------------------------------------------------------------------------------------------------------------------
Rdzeń x86 CypressCove 300 milionów tranzystorów
Front-end
Cache L1-Instrukcji 32KB 8-Way
µOP cache 2250 wpisów
Smarter prefetchers(inteligentniejszy preselektor)
Improved Branch Predictor(ulepszony predyktor gałęzi)
ITLB 16 wpisów(podwójne 2M)
Allocation Queue(IDQ) 70 µOP/wątek lub 140 µOP pojedynczy wątek
LSD może wykryć do 70 µOP pętli/wątek lub 140 µOP pojedynczy wątek
5-cio drożny dekoder x86(1 kompleksowy, 4 proste)
Back-end
Przydział instrukcji 5-Way
Przekolejkowywanie instrukcji(OoO(ROB)) 352 wpisy w locie
Scheduler 160 wpisów
Register Files - Integer 280 wpisów + FP 224 wpisy
Dispatch 10-Way (wysyłka z schedulera(porty jednostek wykonawczych))
Execution Engine
3x FP-ALU(Jednostki arytmetyczno-logiczne-zmiennoprzecinkowe(1x FMAC512bit lub 2x FMAC256bit))(w rzeczywistości jest 1x FMAC512bit + 1x FMAC256bit)
1x ALU(Jednostka arytmetyczno-logiczna)
2x StoreData(magazyn danych)
2x AGU(ładowanie adresów)
2x AGU(generowanie adresów)
Memory subsystem
In-Flight Loads 128 wpisów (ładowanie w locie z L1D)
In-Flight Stores 72 wpisy (magazynowanie w locie do L1D)
Cache L1-Danych 48KB 12-Way
Cache L2 512KB 8-Way
------------------------------------------------------------------------------------------------------------------------------
Rdzeń x86 GoldenCove ~500 milionów tranzystorów
Front-end
Cache L1-Instrukcji 32KB 8-Way
µOP cache 4000-6000 wpisów
Smarter prefetchers(ogromny preselektor)
Improved Branch Predictor(ogromny predyktor gałęzi)
ITLB 32 wpisów(poczwórne 2M)
Allocation Queue(IDQ) 128 µOP/wątek lub 256 µOP pojedynczy wątek
LSD może wykryć do 128 µOP pętli/wątek lub 256 µOP pojedynczy wątek
8-io drożny dekoder x86(2 kompleksowe, 6 prostych)
Back-end
Przydział instrukcji 6-8-Way
Przekolejkowywanie instrukcji(OoO(ROB)) 800 wpisów w locie
Scheduler 300-450 wpisów
Register Files - Integer 350-500 wpisów + FP 300-400 wpisów
Dispatch 16-Way (wysyłka z schedulera(porty jednostek wykonawczych))
Execution Engine
6x FP-ALU(Jednostki arytmetyczno-logiczne-zmiennoprzecinkowe(2x FMAC512bit + 1-2x FMAC256bit(2x 512b lub 3-4x 256bit)
2x ALU(Jednostka arytmetyczno-logiczna)
3x StoreData(magazyn danych)
3x AGU(ładowanie adresów)
2x AGU(generowanie adresów)
Memory subsystem
In-Flight Loads 250-360 wpisów (ładowanie w locie z L1D)
In-Flight Stores 128-192 wpisy (magazynowanie w locie do L1D)
Cache L1-Danych 48KB 12-Way
Cache L2 1280KB 20-Way
Ciekawe jak bardzo chybię w tym przewidywaniu ;)
- Panie Intel (autor: Xeno | data: 28/03/21 | godz.: 23:38)
radze pójśc do sklepu i kupić sobie porządny komputer z M1...
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
