|
TwojePC.pl © 2001 - 2026
|
 |
Wtorek 22 czerwca 2021 |
 |
| |
|
Ryzen Embedded trzeciej generacji w litografii 6nm z grafiką RDNA 2
Autor: Zbyszek | 12:29 |
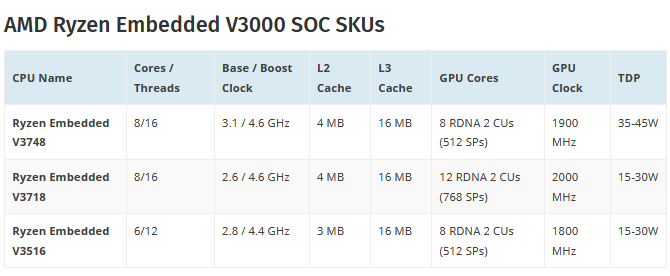
(11)") |  AMD przygotowuje się do wprowadzenia na rynek procesorów Ryzen Embedded trzeciej generacji, czyli Ryzen Embedded V3000. Procesory te są dedykowane do stosowania takich branżach, jak systemy obrazowania medycznego, elektronika przemysłowa, automaty do gier czy urządzenia typu „thin client”. Ich trzecia generacja to monolityczne procesory w formie APU, wyprodukowane w litografii 6nm, i zawierające 8 rdzeni ZEN 3 oraz układ graficzny z architekturą RDNA 2 dysponujący maksymalnie 12 blokami Compute Units. AMD przygotowało przynajmniej 3 modele: 8-rdzeniowe Ryzen Embedded V3748 i Ryzen Embedded V3718, różniące się wydajnością zintegrowanej grafiki, oraz 6 rdzeniowy Ryzen Embedded V3516. AMD przygotowuje się do wprowadzenia na rynek procesorów Ryzen Embedded trzeciej generacji, czyli Ryzen Embedded V3000. Procesory te są dedykowane do stosowania takich branżach, jak systemy obrazowania medycznego, elektronika przemysłowa, automaty do gier czy urządzenia typu „thin client”. Ich trzecia generacja to monolityczne procesory w formie APU, wyprodukowane w litografii 6nm, i zawierające 8 rdzeni ZEN 3 oraz układ graficzny z architekturą RDNA 2 dysponujący maksymalnie 12 blokami Compute Units. AMD przygotowało przynajmniej 3 modele: 8-rdzeniowe Ryzen Embedded V3748 i Ryzen Embedded V3718, różniące się wydajnością zintegrowanej grafiki, oraz 6 rdzeniowy Ryzen Embedded V3516.
Cała trójka ma 16MB pamięci L3, taktowanie boost sięgające 4,6 GHz w wersjach 8 rdzeniowych i 4,4 GHz dla wersji 6-rdzeniowej, oraz IGP zawierający od 8 do 12 bloków CU z taktowaniem wynoszącym w zależności od modelu od 1,8 GHz do 2,0 GHz.
Nowe CPU mają zastąpić oferowaną od roku serię Ryzen Embedded V2000, wytwarzaną w 7nm litografii, i zawierającą rdzenie ZEN2 i układ graficzny z architekturą Vega.
 |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- @temat. (autor: Mariosti | data: 22/06/21 | godz.: 13:29)
O, 12CU? Czyżby nowe gpu intela faktycznie były niezłe?
- Ze względu na przestarzałe litografie produkcji z jakimi Intel ma do czynienia (autor: Mario1978 | data: 22/06/21 | godz.: 15:51)
tutaj będziemy mieli sytuację analogiczną do obecnej. Wydajność na Watt w rękach AMD i maksymalna wydajność na jeszcze wyższym poziomie. Zobaczymy jak Intel postąpi ze zmianą nazw dla swoich procesów produkcji bo jak swoje 7nm++ nazwie 3nm Ultra Fin to cienko go widzę w konfrontacji z N3 czyli potocznie nazwane 3nm, z którego Apple będzie korzystał i znajdzie się w gotowych iPhone na czwarty kwartał 2022 roku. Plotki o zainteresowaniu Intel litografią N3 już dwa lata temu pięknie pokazują, że Intel na prawdę będzie chciał z tej litografii korzystać. Intel może mieć dobry projekt chociażby samych CPU ale gdy był on projektowany dla litografii 7nm od Intela rzekomo z upakowaniem tranzystorów na poziomie 270 Milionów na mm2 to ten projekt ma szansę pełnego wykorzystania dopiero dla litografii N3 od TSMC.
Jak zwykle Intel jest ratowany przez oprogramowanie, które efektywniej wykorzystuje ich stare projekty a architektura Zen od pierwszej generacji dla procesorów dalej nie jest w pełni efektywnie wykorzystania w OS ogólnie dostępnym dla konsumenta. Jedynie wielkie firmy mające swoich programistów mogą sobie pozwolić na własny OS dopracowany pod ich zamówienie dlatego czasami bywają takie Kwiatki jak różnica wydajności czy przepustowości wynosząca 300%. Mieć 60GB/s a 197GB/s przepustowości i to efektywnej to jednak robi różnicę a tak niestety bywa na tym rynku gdy oprogramowanie nie potrafi wykorzystać Hardware. Mnie tam już bardziej interesuje Zen 4 bo zastosowanie litografii N5P to będzie większy skok niż przejście z 14nm na 7nm DUV od TSMC. Różnica tranzystorów na mm2 zrobi swoje.
- Mario1978 | (autor: Markizy | data: 22/06/21 | godz.: 19:51)
nie przypominam sobie żeby intel w ostatnich litografiach spełniał wymagania pod względem ilości tranzystorów na mm^2. Ktoś już kiedyś tutaj udowadniał że parametry intela podane przez nich to czysta fikcja.
Intela nie ratowało stare oprogramowania, tylko wyższy zegar przez co mieli wyższą wydajność. Podstawę oprogramowania pod względem chociażby dokumentacji dostarcza producent układu scalonego, następnie na tej podstawie trzeba stworzyć oprogramowania.
Natomiast przejście z 14nm intelowskie na 7nm tsmc to będzie skok, 7nm zapewnia podobny poziom co prawidłowo wdrożone 10nm od intela.
Niemniej stawiam że intel wykorzysta maksymalnie jeden proces technologiczny dla swoich cpu od TSMC bo jest to nadal na tyle duża firma że jest w stanie wprowadzić nowe procesy na równi z konkrecją. Faktem jest że będzie wymagać to zmiany zarządzania fabami przez nich (otworzyć je dla firm zewnętrznych) ale jednak.
- Markizy (autor: PCCPU | data: 22/06/21 | godz.: 21:37)
Generalnie nowe mikroarchitektury x86 tworzy się po to by zapewnić wyższą wydajność w dotychczasowym oprogramowaniu.
- Chyba że (autor: PCCPU | data: 22/06/21 | godz.: 21:41)
Miałeś na myśli nowe instrukcje to z tym się zgodzę.
Co to dotychczasowych instrukcji np x86, x87, SSE, AVX itp to nowa mikroarchitektura ma dać wyższe IPC a nie że dopiero da jak oprogramowanie zostanie dostosowane.
- Edit2 (autor: PCCPU | data: 22/06/21 | godz.: 21:43)
Właśnie rozbudowa logiki rdzenia i optymalizacja ma dać wyże IPC w instrukcjach które już istnieją.
- 3)) (autor: Mario1978 | data: 23/06/21 | godz.: 13:32)
Operuję teoretycznymi wartościami zagęszczenia tranzystorów na mm2. Patrząc w przeszłość już można przewidzieć ile tranzystorów na mm2 zmieści się w układach HPC u Intela. U Intela jest to granica 45-58% teoretycznego zagęszczenia wobec rzeczywistego. Druga sprawa Intel zrewidował swoje plany na temat teoretycznego zagęszczenia tranzystorów dla litografii 7nm i zamiast ponad 270 MTr/mm2 mamy mieć teoretycznie 200 MTr/mm2. Czyli jak skorzystamy z naszego doświadczenia patrząc na przeszłość Intela to architektura Golden Cove była tworzona pod zagęszczenie tranzystorów wynoszące 90-100MTr/mm2. Zastosowanie słabszego/starszego procesu produkcji pod względem zagęszczenia jakim jest 10nm już w tej chwili od Intela tylko obniży sporo tą wartość dlatego zużycie energii będzie wyższe.
Zresztą przykład mamy w przypadku zastosowania najlepszej litografii ale już Starusienkiej jaką jest 14nm od Intela z nowym obciętym projektem. Żeby rozbudować rdzeń pod względem projektu potrzeba litografii, która zapewni taką gęstość upakowania tranzystorów by projekt był w pełni efektywnie wykorzystany. W TSMC czy Samsung teoretyczna wartość upakowania tranzystorów a realna dla układów HPC jest o 25-40% niższa. Z tym, niższe upakowanie jest na początku bo w miarę postępu i dopracowywania litografii otrzymujemy zagęszczenie tranzystorów na mm2 jeszcze większe. U Intela mamy na odwrót, w miarę postępu i rozwoju litografii czyli jej dopracowywania na obecnym węźle otrzymujemy jeszcze niższe zagęszczenie tranzystorów na mm2. Na przykładzie Intela i ich 14nm najlepiej dopracowanych ta teoretyczna wartość zagęszczenia tranzystorów wynosi 42.5 MTr/mm2 a rzeczywista w gotowym produkcie osiąga 18 MTr/mm2.
TSMC ma na chwilę obecną rozpiskę dla swojej litografii N3 gdzie zagęszczenie teoretyczne tranzystorów na mm2 wyniesie aż 303 MTr/mm2. Patrząc na samo to Intel będzie zmuszony składać zamówienia w TSMC jak chce stanowić realną konkurencję dla AMD.
- @7. (autor: Mariosti | data: 23/06/21 | godz.: 16:14)
Tylko gdyby TSMC miało nieskończone moce produkcyjne.
W sytuacji w której Apple zajmuje ponad 70% mocy produkcyjnych TSMC, Intel nawet z 2x gorszym procesem i tak będzie mógł utrzymać silną pozycję na rynku bo amd zwyczajnie fizycznie nie może wypuścić na rynek wystarczającej ilości produktów.
- PCCPU (autor: Markizy | data: 23/06/21 | godz.: 18:10)
aby przyśpieszyć wykonywanie niektórych operacji tworzy się właśnie nowe instrukcje. Natomiast to co dostarcza producent ma zapewnić właściwie działanie kompilatora aby efektywniej przygotowywał np składanie instrukcji aby procesor to liczył szybciej.
I projektanci układów stawiają raczej na jak najszybsze wykonywanie obecnie już wykonywanych instrukcji nie zależnie od ich rodzaju.
- @9. (autor: pwil2 | data: 24/06/21 | godz.: 01:40)
Ale przy projektowaniu architektury trzeba podjąć decyzje na przykład co do wielkości i trybu pracy pamięci cache. Aplikacja jeśli ma działać optymalnie, powinna przetwarzać dane w paczkach mieszczących się w cache.
Cache w trybie inclusive lepiej działa ze starym softem, ale cache na wyłączność lepiej się skaluje.
- @9. (autor: Mariosti | data: 24/06/21 | godz.: 13:21)
Procesor to nie jest ręczny kalkulator.
W raz z kolejnymi architekturami procesorów coraz więcej starych instrukcji wykonywanych jest np nie w 2-4 tylko w 1 cyklu procesora.
Dodatkowo całkowity, średni czas wykonania instrukcji polega też na szybkości działania cache, kontrolera ram itd.
Średni czas wykonania instrukcji polega też na skuteczności mechanizmu predykcji skoków i wykonywania równolegle instrukcji które procesor myśli że być może będą następne do wykonania.
Teraz dochodzą nowe mechanizmy predykcji wartości danych w tych predykowanych rozgałęzieniach instrukcji.
Dodatkowo, średni czas wykonywania instrukcji zależy też od kwestii efektywności dzielenia zasobów rdzenia procesora pomiędzy różne wątki (SMT).
I to wszystko to tylko czubek góry lodowej.
Nowe instrukcje zwykle wyrastają w naturalny sposób jako konsekwencja rozbudowy rdzeni, lub jako celowe optymalizacje specyficznych działań na procesorze powszechnie wykonywanych w różnym oprogramowaniu i wyskakujących w profilerach jako procentowo czasochłonne, a np w krzemie wcale nie wymagają dużo dodatkowej logiki do zmiany na instrukcje wykonywane w jednym cyklu zegara.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
