|
TwojePC.pl © 2001 - 2026
|
 |
Piątek 20 sierpnia 2021 |
 |
| |
|
Intel Golden Cove: szczegóły budowy nowych wydajnych rdzeni CPU
Autor: Zbyszek | źródło: Intel | 12:01 |
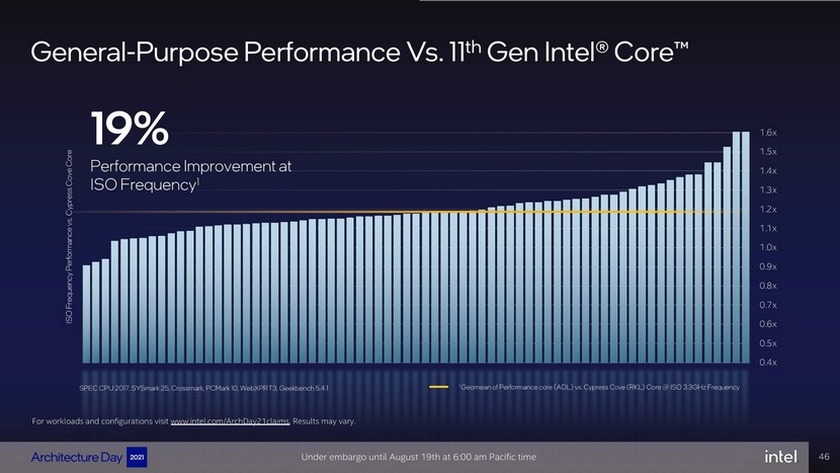
(7)") |  Podczas konferencji Architecture Day 2021 Intel przedstawił szczegóły budowy swojego nowego wydajnego rdzenia CPU - Golden Cove. Nowy rdzeń zostal znacznie usprawniony i oferuje średnio o 19% wyższy wskaźnik IPC od poprzedników, czyli Sunny Cove, Willow Cove i Cypress Cove. Podczas gdy Cypress Cove można określić jako bardziej rozbudowaną wersję architektury Skylake, w przypadku Golden Cove zmian jest znacznie więcej. Znacznie przebudowano front-end, czyli część rdzenia zaopatrującą jednostki wykonawcze w instrukcje. W tej części znacznie rozbudowano dekoder rozkazów - zamiast 1 dekodera typu complex wspartego 4 dekoderami typu simple, Golden Cove dysponuje 6 dekoderami typu complex. Podczas konferencji Architecture Day 2021 Intel przedstawił szczegóły budowy swojego nowego wydajnego rdzenia CPU - Golden Cove. Nowy rdzeń zostal znacznie usprawniony i oferuje średnio o 19% wyższy wskaźnik IPC od poprzedników, czyli Sunny Cove, Willow Cove i Cypress Cove. Podczas gdy Cypress Cove można określić jako bardziej rozbudowaną wersję architektury Skylake, w przypadku Golden Cove zmian jest znacznie więcej. Znacznie przebudowano front-end, czyli część rdzenia zaopatrującą jednostki wykonawcze w instrukcje. W tej części znacznie rozbudowano dekoder rozkazów - zamiast 1 dekodera typu complex wspartego 4 dekoderami typu simple, Golden Cove dysponuje 6 dekoderami typu complex.
Nowe dekodery potrafią też przyjmować na wejściu jednocześnie 32 bajty instrukcji x86, zamiast 16 bajtów jak w Sunny Cove i Skylake. Kolejka zdekodowanych instrukcji może być teraz zasilana nawet 8 mikro-instrukcjami w jednym cyklu zegara, zamiast sześcioma jak w Sunny Cove i Cypress Cove. Ma też większą długość - przechowuje 72 mikroinstrukcje na wątek (lub 144 mikroinstrukcje dla jednego wątku, jeśli właśnie obsługiwany jest tylko jeden wątek).
Oprócz tego w części front-end prawie dwukrotnie powiększono pamięć podręczną mico-op-cache dla zdekodowanych instrukcji (ma ona wielkość 4K zamiast 2,25K) oraz usprawniono podsystem TLB i system predykcji skoków, który jest bardziej skuteczny i może śledzić teraz do 12 tysięcy instrukcji, zamiast do 5 tysięcy instrukcji.
Cześć wykonawcza została wyraźnie rozbudowana - liczba portów schedulera została zwiększona z 10 do 12, a liczba mikroinstrukcji przydzielanych do wykonania podczas jednego cyklu zegara wzrosła z 5 do 6. Aby obsłużyć zwiększony o 20 procent potok instrukcji dodano dodatkowe jednostki wykonawcze - liczba jednostek ALU wzrosła z 4 do 5, liczba jednostek AGU wzrosła z 4 do 5, a każda jednostka ALU wsparta jest dodatkową jednostką typu LEA. W części zmienno-przecinkowej do jednostek typu FMA dodano obsługę instrukcji typu FP16 oraz dodano jednostki typu FADD realizujące proste instrukcje. Powiększony został też bufor przekolejkowań (Re-Order Buffer) który ma teraz pojemność 512 mikroinstrukcji, zamiast 352 mikroinstrukcji jak w Sunny Cove i 224 w Skylake.
W części back-end, czyli ładującej i odbierającej dane do jednostek wykonawczych, zwiększono liczbę jednocześnie wykonywanych operacji typu Load z 2 do 3 na cykl zegara, a także poprawiono buforów obsługujących operację Load i Store, oraz usprawniono mechanizm TLB w pamięci podręcznej L1 danych i prefetcher w pamięci podręcznej L2.
W praktyce w Golden Cove mamy zatem do czynienia z rdzeniem o budowie sześciodrożnej - 6 dekoderów, 6 mikroinstrukcji przetwarzanych w 1 cyklu. Poprzednie architektury SunnyCove i Skylake miały budowę 5-drożną, a serie od Core 2 Duo, poprzez Sandy Bridge po Haswell były rdzeniami 4-drożnymi. Sumarycznie względem architektury Skylake wskaźnik IPC powinien być większy o około lub blisko 40 procent (1,18 x 1,19)
Wprowadzone zmiany są dość duże i zapewne uzyskany przez nie wzrost wskaźnika IPC mógłby być większy, gdyby zdecydowano się bardziej rozbudować część back-end rdzenia. Prawdopodobnie ten element rdzenia zostanie bardziej rozbudowany w ulepszonej wersji Golden Cove, czyli w rdzeniu Raptor Cove, który według nieoficjalnych informacji ma zaoferować wzrost wskaźnika IPC do 10% względem Golden Cove.
         |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- Zbyszek (autor: PCCPU | data: 20/08/21 | godz.: 17:48)
Rdzeń x86 Skylake nie ma ROB 256 mikroinstrukcji tylko 224. ROB z 256 mikroinstrukcjami mają rdzenie x86 Zen3(AMD) i Gracemont(Intel).
Nie wiem gdzie widziałeś że rdzeń x86 GoldenCove ma podwójny
3 drożny dekoder x86, ze slajdów to nie wynika. Natomiast ja widzę że jest pojedynczy 6 drożny dekoder x86. Mało tego, według tych slajdów Intel twierdzi że rdzeń x86 SunnyCove dysponuje 4 drożnym dekoderem x86 a ja do tej pory byłem przekonany że jednak 5 drożny dekoder. Przynajmniej według Wikichip i innych źródeł. Co ciekawe na slajdzie Intela dotyczącym mikroarchitektury Skylake też są 4 dekoder x86 a jedynie na szczałce od dekodera x86 jest opis 5 co może znaczyć do 5 mikroinstrukcji być może z mikro i makro fuzją.
Podwójny klaster 3 drożnych(sumarycznie 6) dekoderów x86 ma rdzeń Gracemont a nie GoldenCove.
- @PCCPU (autor: henrix343 | data: 20/08/21 | godz.: 20:17)
respect.
- Fajnie to wyglada i super ze jest tak duzo ciekawych zmian... (autor: gantrithor | data: 21/08/21 | godz.: 00:07)
niestety wzrost mocy obliczeniowej nie jest adekwatny do usprawnien w budowie ukladu i mam dosc dziwne de ja vu jak mialo to miejsce z pentium 4 gdzie rdzen prescott mial zastapic northwood i tam tez fajnie to wygladalo na papierze niestety okazlalo sie inaczej w praktyce bo wydluzony potok wykonawczy spowodowal ze zegar w zegar prescott przegrywal z northwoodem intel wtedy probowal kompensowac to zwiekszeniem ilosci pamieci cache... northwood 3,2GHz szedl leb w leb z athlonem 64 3200+ gdzie procesor amd czesciej byl szybszy kiedy prescottowi bylo blizej athlonowi 64 3000+ na dodatek system z presscotem i gpu ati radeon 9800 pro zuzywal o 80-100w wiecej niz ten sam system z athlonem 3200+ i az o 200 w wiecej niz system z northwoodem 3,2GHz!
Intel juz dzisiaj ma problem z pradozernoscia swoich konstrukcji...
- @ PCCPU (autor: Zbyszek.J | data: 21/08/21 | godz.: 00:38)
dzięki za korekty. Z pośpiechu faktycznie zrobiłem te 2 błędy (ROB w Skylake 256 zamiast 224) i 6 dekoderów w 2 grupach zamiast 1). Ale dzięki Tobie je zaraz poprawiłem.
Skylake ma 5-drożny dekoder:
https://en.wikichip.org/...ectures/skylake_(client)
https://www.anandtech.com/...ture-and-sunny-cove/3
- Zbyszek.J (autor: PCCPU | data: 21/08/21 | godz.: 01:50)
Ależ proszę bardzo :)
Wikichip wcale nie jest nie omylny a Intel nigdzie nie umieścił informacji że Skylake dysponuje 5 drożnym dekoderem x86. 5 mikro-instrukcji z dekodera x86 może świadczyć o mikro lub makro fuzji lub że zł po żony dekoder daje dwie mikro-instrukcji.
Slajd Intela o GoldenCove mówi co innego:
Szerszy z 4 do 6 dekoderów! A to oznacza że od Conroe(Core2) do SunnyCove dekoder x86 był 4 drożny.
Wikichip:
"Front-End Improvements
There are some really major changes in the Golden Cove microarchitecture. The front-end on Golden Cove is perhaps the biggest genealogical change in the microarchitecture going as far back as Sandy Bridge or even earlier. Although the cache itself is unchanged, Golden Cove can now fetch 32 bytes each cycle, doubling the fetch bandwidth versus all prior cores (I believe all the way back to the original P6). The higher bandwidth was necessitated by the largest change in the code – the decoders. Golden Cove is now 50% wider than all previous cores, adding 2 additional decoders for a total of six.
To complement that higher fetch and decode bandwidth from the MITE path, the DSB path was also enlarged. Intel nearly doubled the micro-op cache to 4K and increased the delivery bandwidth by a third – from 6 μOPs/cycle to 8 μOPs/cycle."
Google translator:
:Ulepszenia frontonu W mikroarchitekturze Golden Cove zaszły naprawdę poważne zmiany. Front-end na Golden Cove jest prawdopodobnie największą genealogiczną zmianą w mikroarchitekturze, sięgającą czasów Sandy Bridge lub nawet wcześniej. Chociaż sama pamięć podręczna pozostaje niezmieniona, Golden Cove może teraz pobierać 32 bajty w każdym cyklu, podwajając przepustowość pobierania w porównaniu ze wszystkimi wcześniejszymi rdzeniami (wierzę, że aż do oryginalnego P6). Wyższa przepustowość była wymuszona największą zmianą w kodzie – dekoderach. Golden Cove jest teraz o 50% szerszy niż wszystkie poprzednie rdzenie, dodając 2 dodatkowe dekodery, co daje łącznie sześć. Aby uzupełnić wyższą przepustowość pobierania i dekodowania ze ścieżki MITE, zwiększono również ścieżkę DSB. Intel prawie podwoił pamięć podręczną micro-op do 4K i zwiększył przepustowość dostarczania o jedną trzecią – z 6 μOP/cykl do 8 μOP/cykl."
https://fuse.wikichip.org/...ient-and-server-socs/
- Edit (autor: PCCPU | data: 21/08/21 | godz.: 01:54)
50% szerszy dekoder x86 to chyba nie z 5 do 6 tylko z 4 do 6 ;)
- Edit2 (autor: PCCPU | data: 21/08/21 | godz.: 14:44)
Jako ciekawostkę dodam że GoldenCove dostał nowy bardzo masywny predyktor który śledzi z wyprzedzeniem 12000 mikro-instrukcji podczas gdy SunnyCove tylko 5000 mikro-instrukcji.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
