|
TwojePC.pl © 2001 - 2026
|
 |
Poniedziałek 1 listopada 2021 |
 |
| |
|
Pierwsze dane na temat procesorów z architekturą ZEN 4
Autor: Zbyszek | 17:58 |
(12)") |  W sierpniu pewni hakerzy zdołali wykraść z firmy Gigabyte aż 112 GB poufnych danych. Były to m.in niewydane jeszcze wersje BIOSu, klucze kryptograficzne, dokumentacje techniczne, oraz chronione tajemnicą informacje Intela i AMD. Po wykonanej akcji włamywacze zmodyfikowali jedną z publicznych stron internetowych Gigabyte, zamieszczając wpis zachęcający kierownictwo Gigabyte do kontaktu z nimi. Obie strony prawdopodobnie nie doszły do porozumienia, i wykradzione dane były stopniowo publikowane w Internecie. Wśród opublikowanych danych znajdują się pierwsze informacje na temat procesorów AMD z architekturą ZEN 4. W sierpniu pewni hakerzy zdołali wykraść z firmy Gigabyte aż 112 GB poufnych danych. Były to m.in niewydane jeszcze wersje BIOSu, klucze kryptograficzne, dokumentacje techniczne, oraz chronione tajemnicą informacje Intela i AMD. Po wykonanej akcji włamywacze zmodyfikowali jedną z publicznych stron internetowych Gigabyte, zamieszczając wpis zachęcający kierownictwo Gigabyte do kontaktu z nimi. Obie strony prawdopodobnie nie doszły do porozumienia, i wykradzione dane były stopniowo publikowane w Internecie. Wśród opublikowanych danych znajdują się pierwsze informacje na temat procesorów AMD z architekturą ZEN 4.
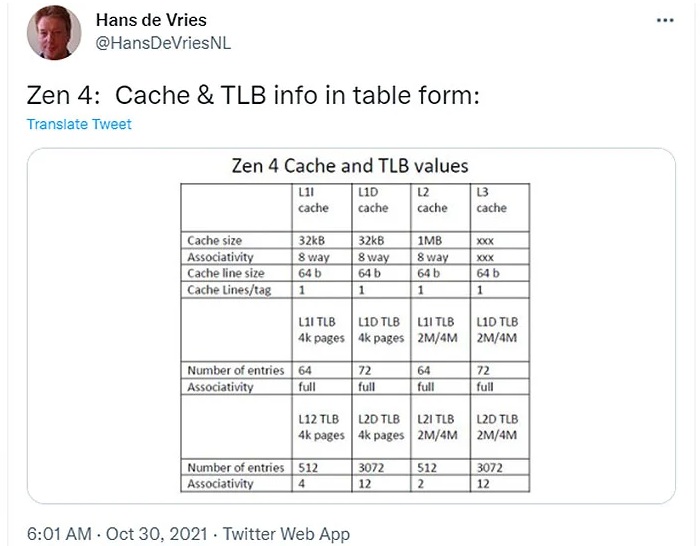
Jedną ze zmian wprowadzoną w ZEN 4 będzie powiększona pamięć L2 - zamiast 512KB będzie to 1MB, o tej samej asocjacyjności (8-way). Dla porównania obecne 10nm rdzenie Intela mają 1,25 MB pamięci L2 o większej asocjacyjności (20-way) - większa asocjacyjność przekłada się na większą szansę, że potrzebne procesorowi dane znajdą się w L2, ale efektem ubocznym są większe opóźnienia w zwracaniu wyników i większy pobór energii. AMD stawia zatem na szybkość działania i efektywność energetyczną pamięci L2.
Informacje pochodzące z Gigabyte potwierdzają też natywną obsługę instrukcji AVX-512 (przynajmniej w wersjach serwerowych procesorów) oraz wyższą częstotliwość pracy magistrali Infinity Fabric. Maksymalny zegar FCLK ma zostać podniesiony z 2000 do 2400 MHz, co może również oznaczać zwiększone taktowanie kontrolera pamięci i obsługę DDR5-4800 w trybie 1:1 (odpowiednik tzw. Gear 1 u Intela).
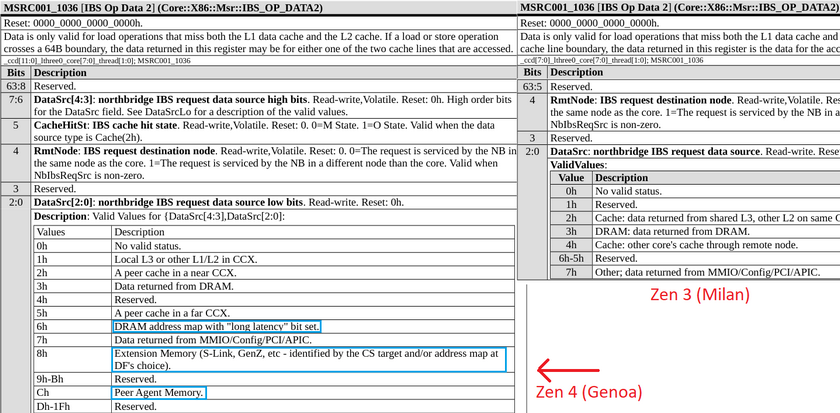
W przypadku interfejsu łączącego chipy CCD z rdzeniami x86 z chipem CIOD (I/O Die), jego szerokość pozostanie bez zmian (32-bity), ale taktowanie (LCLK) zostanie podniesione z 750 MHz do 1,15 GHz, zapewniając o 53 procent większą przepustowość. Dodatkowo, każdy chip CCD otrzyma nie jeden, ale po dwa takie interfejsy, a chipy CCD i CIOD podwójną liczbę nadajników/odbiorników SDP (Scalable Data Ports). Nie wiadomo na ten moment w jaki sposób AMD chce wykorzystać dodatkowe interfejsy, ale można wyobrazić sobie np. bezpośrednią komunikację pomiędzy chipami CCD, a nie za pośrednictwem CIOD jak dotychczas.
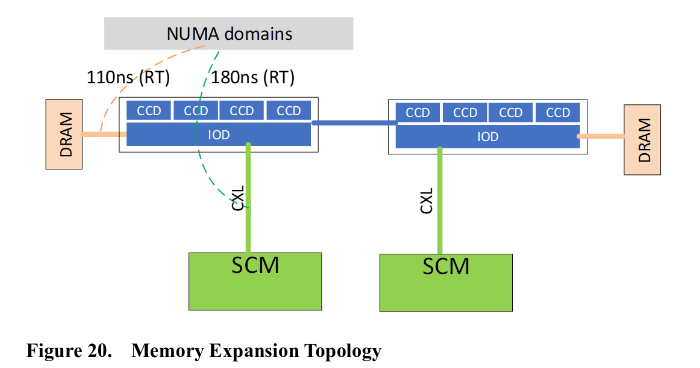
Poza tym z dokumentacji wyciekłej z Gigabyte wynika, że serwerowy chip CIOD otrzyma mechanizm wykrywający typ zainstalowanej pamięci RAM - czy będzie to szybka pamięć DRAM, czy też pamięć RAM typu SCM (Storage claass Memory) o większych opóźnieniach - np. moduły Intel Optane. W zależności od tego front-end procesora ma zachowywać się nieco inaczej, w celu uzyskania maksymalnej wydajności. Możliwa będzie też praca procesorów EPYC Genoa z jednocześnie zainstalowanymi w slotach DIMM obydwoma typami pamięci (DRAM i Optane)
ZEN 4 ma też dysponować bardziej rozbudowanymi mechanizmami mierzenia własnej wydajności, oraz dedykowanym koprocesorem operacji wejścia/wyjścia (I/O) nadzorującym działanie magistral m.in. PCI-E, USB, SATA itp. Dotychczas funkcję tą pełnił BIOS płyty głównej.
    |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- asocjacyjność 8-way i 20-way (autor: DrLamok | data: 1/11/21 | godz.: 18:15)
rozwiń trochę temat asocjacyjności o której tak kwieciście piszesz w artykule... chciałbym się dowiedzieć więcej w temacie...
- w uproszczeniu to tak (autor: Zbyszek.J | data: 1/11/21 | godz.: 18:18)
jakby liczba kanałów dostępu do cache. Inaczej np. cache 8-drożny, 20-drożny...
- jak będzie (autor: Mario2k | data: 1/11/21 | godz.: 21:14)
To zobaczymy po premierze , wystarczy żeby było 10-15% szybciej w single core od Intela Alder Lake to będzie dobrze.
- @Mario2k (autor: rainy | data: 1/11/21 | godz.: 21:54)
Spodziewam się, iż wzrost IPC Zena 4 będzie podobny albo nawet trochę wyższy (20 lub ponad 20 procent) niż Zen 3 vs Zen 2, więc od AL będzie z całą pewnością zauważalnie szybszy.
- ponoć ZEN4 (autor: Zbyszek.J | data: 1/11/21 | godz.: 22:26)
ponoć ZEN4 ma przypominać przejście z ZEN1 na ZEN2. Czyli w rdzeniu x86 raczej nie optymalizacja (jak ZEN 3), ale w większości ewolucja (rozbudowa struktur). Za to otoczenie rdzeni x86 zostanie wyraźnie pozmieniane (tak jak przy ZEN 2).
I następnie ZEN5 to sytuacja podobna jak przejście z ZEN 2 do ZEN3 - czyli otoczenie rdzeni x86 bez większych zmian, a same rdzenie x86 dużo zoptymalizowane (a mało rozbudowane).
- @4. (autor: Mariosti | data: 2/11/21 | godz.: 11:58)
W takim układzie w ST wyrówna AL, a w MT znowu mu odjedzie (i to porównując oczywiście do AL@241W).
- @Mariosti (autor: rainy | data: 2/11/21 | godz.: 13:17)
Moim zdaniem, IPC Alder Lake będzie circa 10 procent wyższe od Zena 3, więc Zen 4 powinien mieć podobną albo nawet trochę wyższą przewagę nad AL w tym elemencie.
- @7. (autor: Mariosti | data: 2/11/21 | godz.: 14:27)
Zobaczymy, generalnie nawet jeśli tylko wyrówna, a nie będzie nagle wcinał 250W pod obciążeniem to i tak będzie technologicznie przed Intelem, tak jak zresztą w tej chwili Zen3 też jednak góruje nad AL, bo porównywanie CPU 250W do CPU 140W jest trochę nie na miejscu w dzisiejszych czasach.
Równie dobrze AL mógłby pokazać co potrafi w porównaniu do 48 rdzenioweg epyc'a zużywającego tyle samo energii elektrycznej.
- ... (autor: pwil2 | data: 3/11/21 | godz.: 00:27)
Dodatkowy link najpewniej pozwoli na uwspólnianie pamięci L3 cache różnych CCD. Tak trochę na wzór najnowszych procesorów IBM. Powstanie coś w stylu L3+L4.
- @1. (autor: pwil2 | data: 3/11/21 | godz.: 00:36)
Asycjacyjność to ilość miejsc w pamięci cache, gdzie mogą trafić dane z określonego adresu pamięci. Przeszukiwanie pamięci podręcznych musi być szybkie, więc upraszcza się do sprawdzenia kilku adresów (przykładowo 8 lub 20).
Efekt jest taki, że jeśli dane są zbyt uporządkowane w pamięci, to naprzemienny dostęp w wybrane adresy pamięci będzie wyrzucać dane z cache. Celowo deoptymalizując soft pod dany procesor można sprawić, by właśnie ten musiał często sięgać do wolnej pamięci, gdy inny będzie trzymał zawartość w szybszym cache.
Robimy pętlę, która pobiera dane z tablicy, która ma kolejne komórki przesunięte względem siebie o 512kB i po odczytaniu 9 elementu wracamy do pierwszego, a cała pętla pobiera dane z RAMu na Ryzenie, a po jednym przejściu z L2 cache w Intelu. Gdzie wykona się 10-20x szybciej?
- c.d. (autor: pwil2 | data: 3/11/21 | godz.: 00:38)
Ze względu na asocjacyjność i unikanie wypychania wzajemnego z cache potrzebnych często danych Intel stosuje takie mniej typowe pojemności jak właśnie 1.25MB, 1.375MB, 1.5MB, 3MB.
- c.d. (autor: pwil2 | data: 3/11/21 | godz.: 00:39)
Dzięki temu zdarzały się anomalia, gdzie 3MB cache wypadało w wyjątkowych sytuacjach lepiej od 4MB w wyższej wersji.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
