|
TwojePC.pl © 2001 - 2026
|
 |
Środa 26 lutego 2020 |
 |
| |
|
Monolityczny Ryzen 9 3950X byłby ponad 2x droższy w produkcji
Autor: Wedelek | źródło: Guru3D | 05:44 |
(13)") |  Tajemnicą poliszynela jest, że procesor oparty o tzw. chiplety jest znacznie tańszy w produkcji niż taki sam układ o budowie monolitycznej. Ciężko było tylko stwierdzić jak duża jest to różnica. W sukurs przyszło nam tu samo AMD, które podało swoje wyliczenia dotyczące procesorów z rodziny Ryzen. Według producenta z Sunnyvale ich Ryzen 9 3950X w wersji monolitycznej byłby ponad dwukrotnie droższy w produkcji niż obecnie sprzedawany model z chipletami. Ma na to wpływ wiele czynników. Po pierwsze uzysk w litografii 7nm mimo iż bardzo dobry nie dorównuje starszej, bardziej dopracowanej technologii produkcji. Tajemnicą poliszynela jest, że procesor oparty o tzw. chiplety jest znacznie tańszy w produkcji niż taki sam układ o budowie monolitycznej. Ciężko było tylko stwierdzić jak duża jest to różnica. W sukurs przyszło nam tu samo AMD, które podało swoje wyliczenia dotyczące procesorów z rodziny Ryzen. Według producenta z Sunnyvale ich Ryzen 9 3950X w wersji monolitycznej byłby ponad dwukrotnie droższy w produkcji niż obecnie sprzedawany model z chipletami. Ma na to wpływ wiele czynników. Po pierwsze uzysk w litografii 7nm mimo iż bardzo dobry nie dorównuje starszej, bardziej dopracowanej technologii produkcji.
Innymi słowy im mniejszy układ tym ryzyko jego uszkodzenia jest niższe, a więc i ostateczny wolumen produkcji jest wyższy.
Poza tym chiplety są jak klocki. Dokładając kolejne można relatywnie szybko i łatwo tworzyć kolejne, bardziej skomplikowane układy, a jeśli któryś z nich nie spełnia wymogów technicznych, to po prostu go odcinamy tworząc procesor z niższej półki cenowej. To redukuje ilość całkowicie niesprawnych procesorów zwiększając tym samym ostateczny uzysk i obniżając całkowity koszt produkcji.
Przy tym różnica na korzyść chipletów rośnie wraz z dodawaniem kolejnych tranzystorów, co świetnie obrazują poniższe wykresy.
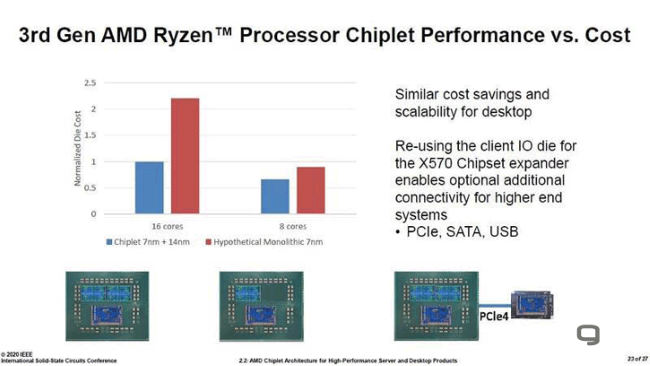 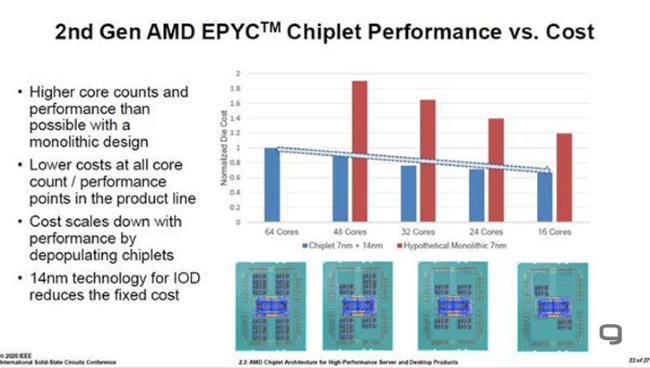 |
| |
|
|
|
|
|
 |
 |
|
|
|
K O M E N T A R Z E |
 |
| |
|
- nieźle AMD zamieniło swoją słabość (brak własnych fabów, własnej technologii) (autor: Qjanusz | data: 26/02/20 | godz.: 09:51)
w atut (opracowanie chipletów i zlecanie produkcji niewielkich kawałków krzemów na zewnątrz)
Dodać trzeba że żadna obecna technologia uniemożliwiłaby wyprodukowanie monolitu z 64 rdzeniami.
Z innych... Panowie Redaktorzy, mamy tzw. środę popielcową, początek wielkiego postu. Proponuje pożegnać już te świąteczno-bałwankowe klimaty na naszym logo :-)
Wiem że ciężko się rozstać, ale już czas.
- Daj spokój. (autor: Muchomor | data: 26/02/20 | godz.: 09:59)
Do wiosny jeszcze miesiąc :)
- @1... (autor: El Vis | data: 26/02/20 | godz.: 10:50)
A od kiedy bałwanek i śnieg to symbol świąt? Nie widzę bombek i światełek na tych choinkach ;-)
- Wszystko przed nami. (autor: Mario1978 | data: 26/02/20 | godz.: 11:56)
Może akurat symbolem Świąt Wielkanocnych stanie się śnieg.A wracając do konstrukcji architektury Zen właśnie przez takie coś otrzymamy przyśpieszenie w rozwoju.Z biegiem czasu łączenie małych układów w jeden duży będzie jeszcze bardziej popularne właśnie z powodu kosztów i wydajności na Watt.Oprócz tego dojdzie układanie w stosy więc będziemy mieli kolejną pieczeń na tym samym kawałku krzemu.A ludzie narzekają , że Ray Tracing dalej najwcześniej za 10 lat a niektórzy wyrokowali za 20 lat a w ciągu 5 lat tak wiele się zmieni.W końcu są odpowiednie technologie oraz szybkie magistrale żeby nie spowalniać zbytni łączenia się takich układów między sobą.
- @El Vis (autor: Qjanusz | data: 26/02/20 | godz.: 12:02)
nie to żebym się czepiał, ale to logo to jest nasz pakiet świąteczny, który został zapodany właśnie na święta a nie pierwszego dnia zimy ;-)
https://twojepc.pl/...sze-GPU-Navi-u-Samsunga.html
btw... @DYD - logo nie przepędziło wiosny niestety. Musimy coś innego wykombinować.
- 48c (autor: pwil2 | data: 26/02/20 | godz.: 12:16)
Spodziewałem się, że w 48c będzie 8 chipletów po 6 rdzeni (2x3), a z grafiki wynika, że jest 6 pełnych chipletów. To zapewne wersja z jedynie 192MB L3 cache. Wersja z 256MB L3 musi być jednak z 8 chipletami. Ciekawe, czy wtedy blokują po jednym rdzeniu w każdym CCX, czy całe CCXy.
- Modułowa budowa CPU to jest przyszłość... (autor: Xclusiv | data: 26/02/20 | godz.: 13:06)
Już nawet kilkanaście lat temu powstał przecież prototyp :)
https://www.yourprops.com/...inchip-Artifact-1.jpg
- dobry ruch AMD (autor: komisarz | data: 26/02/20 | godz.: 13:31)
ciekawe czy intel probowal juz isc w tym kierunku? w koncu pierwsze procesory dwu a potem czterordzenowe komunikowaly sie przez szyne i wydajnosc byla dobra. dziwne ze nie drazyli tematu.
Poza tym pokazuje to ze marze intela nie byly tak astronomiczne, skoro mieli dwa razy wyzsze koszty.
- 8%% (autor: Mario1978 | data: 26/02/20 | godz.: 14:08)
Ty chyba sam nie wiesz co piszesz.Nawet jak koszty produkcji u Intela są wyższe nie zmienia to faktu , że zgodnie z prawem wyciska kasę ile się da.Zyski odzwierciedlają jak wysoką marżę ma Intel więc ocieplanie wizerunku tej firmy nie ma sensu.Firmy , które sprzedają dużo i zarabiają na tym ogromną kasę są dla mnie nic nie warte bo pokazują , że mają gdzieś portfel konsumenta.Ludzie z generacji na generację są bardziej inteligentni i nawet jeżeli robimy coś honorowo dla swojego kraju , wspierając firmy to i tak dojdziemy do punktu-dojść tego.
Firmy mające wysokie marże mogą podać rękę Złodziejowi.Podobieństwa są takie by jak najwięcej zarobić najmniejszym kosztem.Intel nie obniża cen bo AMD ma lepszą ofertę ale dlatego , że wiele firm myśli nad zmianą i oni to widzą.
Każda z firm testuje rozwiązania AMD u siebie w swoim środowisku programowym.To jest czas oczekiwania a gdy Intel wydając Ice Lake SP nie zrobi wrażenia a to już pewne to trzeba się przygotować , że Epyc 3 zrobi swoje.
- @komisarz (autor: VP11 | data: 26/02/20 | godz.: 15:36)
o ile pamietam dawno temu. Wyszo wtedy ze dostawalo po dupie od AMD, ktore robilo dwurdzeniowe nie sklejone.
Wiadomo ze kazde laczenie prowadzi do utraty wydajnosci. Intel wyjezdza jeszcze na tym ze jednowatkowo obchodzi AMD, pomijam koszty tego.
- @1 owszem istnieje inna technika produkcji ogromnych monolitow... (autor: gantrithor | data: 26/02/20 | godz.: 15:43)
a jest nia waferscale engine czyli procesor zajmujacy caly wafel krzemowy i jakis czas temu firma cerebras systems zbudowala taki uklad o rozmiarze 46225mm/2 co daje 56 razy wiekszy uklad niz nvidia gv 100.
Moze uklad wielkosci calego wafla krzemowego nie jest praktyczny w zastosowaniach domowych... ale juz do produkcji ukladow mcm jest idealny.
Obecnym ograniczeniem dla monolitycznych ukladow jest rozmiar okolo 850mm/2 ale dzieki najnowszym odkryciom w dziedzinie matematyki mozna w pewien sposob obejsc problem aberacji soczewek w maszynach litograficznych i prawdopodobnie zwiekszyc ten limit do okolo 1200mm/2 co jest i tak dosc niepraktyczne.
Jednak uklady mcm sa przyszloscia a wraz z nia wafer scale chociaz by do druku interpostera na ktorym zostana osadzone duzo mniejsze uklady mcm.
- @4. (autor: Mariosti | data: 26/02/20 | godz.: 16:25)
Widzisz, w CPU udało się wprowadzić MCM, ale wynika to ze specyfiki wątków które działają na rdzeniach x86. Są to tzw. pełne wątki, z własną przestrzenią adresową, zupełnie niezależne od innych.
Stosowane są również tzw lekkie wątki i te np dobrze wspomagają techniki SMT.
W przypadku GPU natomiast nie mamy stricte pojęcia rdzeni, ich ekwiwalentami są bardziej Compute Units składające się z dziesiątek Stream Processors no i fakt iż zasadniczo wewnątrz CU wszyskie SP mogą zwykle wykonywać tylko ten sam kod na sąsiednich danych. Z kolei instrukcje z np gry są dekodowane w Schedulerze który to w odróżnieniu od x86 jest jeden na całe gpu, a nie tak jak w x86 jeden per rdzeń.
To oznacza że do działania MCM to scheduler musiałby rozdzielać zadania na poszczególne chiplety, a to nie lada problem ponieważ chiplety działają dobrze dzięki faktowi iż każdy ma osobną pamięć podręczną.
Scheduler gpu do tej pory miał kompletną kontrolę nad całym, spójnym cache, a i tak zajmował znaczną część powierzchni gpu.
Nie mówię że nie da się tego zrobić, bo na pewno się da. Szczególnie AMD powinno być wstanie to zrobić bo mają już doświadczenie w praktycznych mechanizmach synchronizacji pamięci podręcznej między chipletami, także ten jeden aspekt były już prawie załatwiony.
Wciąż pozostaje wtedy kwestia znacznego skomplikowania schedulera gpu do obsługi chipletów i tutaj problem zdaje się być większy bo w kwestii efektywności działania schedulera AMD nie błyszało przed RDNA.
Pozostaje jeszcze kwestia tego jak wielki musiałby być ekwiwalent chipu IOd ze schedulerem, no i jak rozwiązać kwestię dostępu do ramu... do tej pory w gpu grupki CU miały własny, bezpośredni dostęp do kontrolera ramu... w przypadku techniki mcm byłoby to dość ciężkie do zrealizowania ze znowu zapewnieniem spójności danych w ramie.
Niemniej jednak chętnie bym zobaczył GPU z 32GB ramu i np 16tys SP bez jakiegoś szalonego taktowania a za to z TDP np 150W.
- @12 patrzac na schemat blokowy ukladow... (autor: gantrithor | data: 27/02/20 | godz.: 16:20)
gpu to nvidia miala by najlatwiejsze zadanie ze skonstruowaniem ukladu mcm gdzie jednostka gigathread rozdziela dane na odrebne SP ktore rownie dobrze moga znajdowac sie w fizycznie innym chipie i przemielone dane ewentualnie laduja we wspolnej pamieci ram.
|
|
|
|
|
|
|
|
|
D O D A J K O M E N T A R Z |
|
| |
|
Aby dodawać komentarze, należy się wpierw zarejestrować, ewentualnie jeśli posiadasz już swoje konto, należy się zalogować.
|
|
|
|
|
|
|
|
|
|
